







亚马逊上海人工智能研究院成立于 2018 年,已成为深度学习研究领域的领先机构之一,共发表了~90 篇论文。研究领域包括深度学习的基础理论、自然语言处理、计算机视觉、图机器学习、高性能计算、智能推荐系统、欺诈检测与风险控制、知识图谱构建以及智能决策系统等。研究院率先研究和开发了世界领先的深度图学习库 Deep Graph Library (DGL),结合了深度学习和图结构表示的优势,影响许多重要应用领域。
检索增强生成(Retrieval-Augmented Generation, RAG)技术正在彻底革新 AI 应用领域,通过将外部知识库和 LLM 内部知识的无缝整合,大幅提升了 AI 系统的准确性和可靠性。然而,随着 RAG 系统在各行各业的广泛部署,其评估和优化面临着重大挑战。现有的评估方法,无论是传统的端到端指标还是针对单一模块的评估,都难以全面反映 RAG 系统的复杂性和实际表现。特别是,它们只能提供一个最终打分报告,仅反映 RAG 系统的性能优劣。
人生病了需要去医院做检查,那 RAG 系统生病了,如何诊断呢?
近日,亚马逊上海人工智能研究院推出了一款名为 RAGChecker 的诊断工具为 RAG 系统提供细粒度、全面、可靠的诊断报告,并为进一步提升性能,提供可操作的方向。本文详细介绍了这个 RAG 的 “显微镜”,看看它如何帮助开发者们打造更智能、更可靠的 RAG 系统。
-
论文:https://arxiv.org/pdf/2408.08067
-
项目地址:https://github.com/amazon-science/RAGChecker
RAGChecker: RAG 系统的全面诊断工具
想象一下,如果我们能对 RAG 系统进行一次全面的 “体检”,会是什么样子?RAGChecker 就是为此而生的。它不仅能评估系统的整体表现,还能深入分析检索和生成两大核心模块的性能。
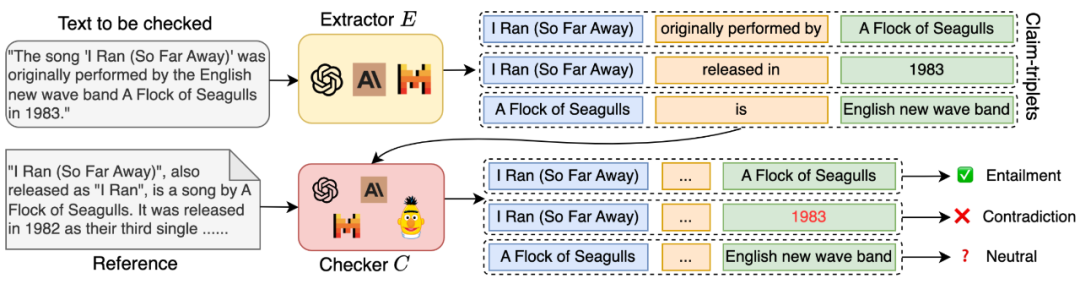
RAGChecker 的主要特点包括:
-
细粒度评估:RAGChecker 采用基于声明(claim)级别的蕴含关系检查,而非简单的回复级别评估。这种方法能够对系统性能进行更加详细和微妙的分析,提供深入的洞察。
-
全面的指标体系:该框架提供了一套涵盖 RAG 系统各个方面性能的指标,包括忠实度(faithfulness)、上下文利用率(context utilization)、噪声敏感度(noise sensitivity)和幻觉(hallucination)等。
-
经过验证的有效性:可靠性测试表明,RAGChecker 的评估结果与人类判断有很强的相关性,其表现超过了其他现有的评估指标。这保证了评估结果的可信度和实用性。
-
可操作的洞察:RAGChecker 提供的诊断指标为改进 RAG 系统提供了明确的方向指导。这些洞察能够帮助研究人员和实践者开发出更加有效和可靠的 AI 应用。
RAGChecker 的核心指标
RAGChecker 的指标体系可以用下图直观的理解:
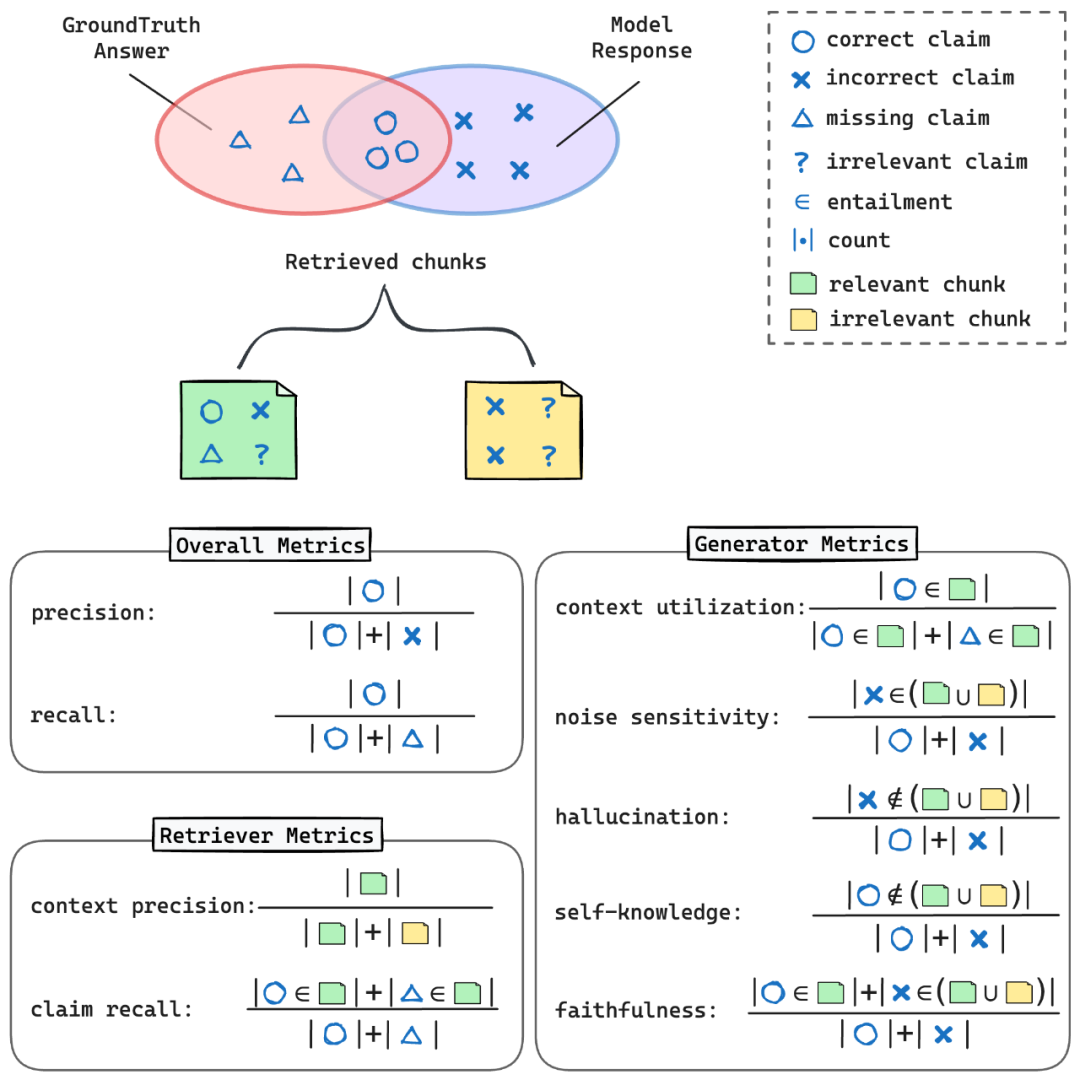
这些指标被分为三大类:
1. 整体指标:
-
Precision(精确率):模型回答中正确陈述的比例
-
Recall(召回率):模型回答中包含的标准答案中陈述的比例
-
F1 score(F1 分数):精确率和召回率的调和平均数,提供平衡的性能度量
2. 检索模块指标:
-
Context Precision(上下文精确率):在所有检索块中,包含至少一个标准答案陈述的块的比例
-
Claim Recall(陈述召回率):被检索块覆盖的标准答案陈述的比例
3. 生成模块指标:
-
Context Utilization(上下文利用率):评估生成模块如何有效利用从检索块中获取的相关信息来产生正确的陈述。这个指标反映了系统对检索到的信息的利用效率。
-
Noise Sensitivity(噪音敏感度):衡量生成模块在回答中包含来自检索块的错误信息的倾向。这个指标帮助识别系统对不相关或错误信息的敏感程度。
-
Hallucination(幻觉):测量模型生成既不存在于检索块也不在标准答案中的信息的频率。这就像是捕捉模型 “凭空捏造” 信息的情况,是评估模型可靠性的重要指标。
-
Self-knowledge(模型内部知识):评估模型在未从检索块获得信息的情况下,正确回答问题的频率。这反映了模型在需要时利用自身内置知识的能力。
-
Faithfulness(忠实度):衡量生成模块的响应与检索块提供的信息的一致程度。这个指标反映了系统对给定信息的依从性。
这些指标就像是 RAG 系统的 “体检报告”,帮助开发者全面了解系统的健康状况,并找出需要改进的地方。
开始使用 RAGChecker
对于想要尝试 RAGChecker 的开发者来说,上手过程非常简单。以下是快速入门的步骤:
1. 环境设置:首先,安装 RAGChecker 及其依赖:
pip install ragcheckerpython -m spacy download en_core_web_sm
2. 准备数据:将 RAG 系统的输出准备成特定的 JSON 格式,包括查询、标准答案、模型回答和检索的上下文。数据格式应如下所示:
{"results": [{"query_id": "< 查询 ID>","query": "< 输入查询 >","gt_answer": "< 标准答案 >","response": "<RAG 系统生成的回答 >","retrieved_context": [{"doc_id": "< 文档 ID>","text": "< 检索块的内容 >"},...]},...]}
3. 运行评估:
-
使用命令行:
ragchecker-cli \--input_path=examples/checking_inputs.json \--output_path=examples/checking_outputs.json
-
或者使用 Python 代码:
from ragchecker import RAGResults, RAGCheckerfrom ragchecker.metrics import all_metrics# 从 JSON 初始化 RAGResultswith open ("examples/checking_inputs.json") as fp:rag_results = RAGResults.from_json (fp.read ())# 设置评估器evaluator = RAGChecker ()# 评估结果evaluator.evaluate (rag_results, all_metrics)print (rag_results)
4. 分析结果:RAGChecker 会输出 json 格式的文件来展示评估指标,帮助你了解 RAG 系统的各个方面表现。
输出结果的格式如下:

通过分析这些指标,开发者可以针对性地优化 RAG 系统的各个方面。例如:
-
较低的 Claim Recall(陈述召回率)可能表明需要改进检索策略。这意味着系统可能没有检索到足够多的相关信息,需要优化检索算法或扩展知识库。
-
较高的 Noise Sensitivity(噪音敏感度)表明生成模块需要提升其推理能力,以便更好地从检索到的上下文中区分相关信息和不相关或错误的细节。这可能需要改进模型的训练方法或增强其对上下文的理解能力。
-
高 Hallucination(幻觉)分数可能指出需要更好地将生成模块与检索到的上下文结合。这可能涉及改进模型对检索信息的利用方式,或增强其对事实的忠实度。
-
Context Utilization(上下文利用率)和 Self-knowledge(模型内部知识)之间的平衡可以帮助你优化检索信息利用和模型固有知识之间的权衡。这可能涉及调整模型对检索信息的依赖程度,或改进其综合利用多种信息源的能力。
通过这种方式,RAGChecker 不仅提供了详细的性能评估,还为 RAG 系统的具体优化方向提供了清晰的指导。
在 LlamaIndex 中使用 RAGChecker
RAGChecker 现在已经与 LlamaIndex 集成,为使用 LlamaIndex 构建的 RAG 应用提供了强大的评估工具。如果你想了解如何在 LlamaIndex 项目中使用 RAGChecker,可以参考 LlamaIndex 文档中关于 RAGChecker 集成的部分。
结语
RAGChecker 的推出为 RAG 系统的评估和优化提供了一个新的工具。它为开发者提供了一把 “显微镜”,帮助他们深入了解、精准优化 RAG 系统。无论你是正在研究 RAG 技术的学者,还是致力于开发更智能 AI 应用的工程师,RAGChecker 都将是你不可或缺的得力助手。读者可以访问 https://github.com/amazon-science/RAGChecker 获取更多信息或参与到项目的开发中来。















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









