







常见的迁移学习任务
1、multi-task model
同时适用于多个task
2、multi-domain model
同时适用于多个domain
3、extensible model
模型可随时间进化,通过之前学习的知识来迁移到新的任务和domain上
创新
定义网络为![]() ;w是universal vector,固定且不同domain之间共享;α是parameter vector,为domain specific参数。其中,α要远小于w。如图(a)所示:
;w是universal vector,固定且不同domain之间共享;α是parameter vector,为domain specific参数。其中,α要远小于w。如图(a)所示:

1、Series Residual Adapters
![]() --->
---> ![]()
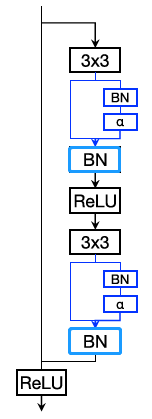
2、Parallel Residual Adapters
![]()
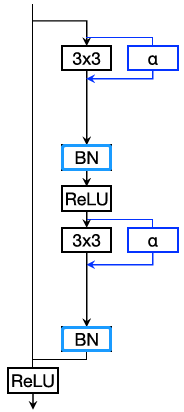
*共同点:
1)当α为0时,恢复原网络,额外的参数失效
2)参数量相同
3)蓝色标记的BN均为task-specific
*不同点:
series adapter无法plug-and-play,原因(作者回答):
We tried the series configuration in a plug and play configuration but the model did not train properly. I assume that inserting modules in series in a neural network hurts the backpropagation process whereas inserting these same modules seem to preserve good training properties. I do not have a clear reason why it works that way, it is just an observation.
*注意:
训练
1、Pretrain:1)series(include adapters)2)parallel(plug-and-play)
2、Freeze pre-trained model
3、Learn adaptation parameters
* dataset ⬆,weight decay⬇
解决N个任务,需要训出 1*主干 + (N-1)*adapter的参数
结论
1、parallel adapter 优于 series adapter
2、early + late layers都需要adapted
3、dropout对bigger pre-trained network有较大提升
4、deeper layers的adapter帮助最大(domain specific信息)
5、pretraining-network的category越多(如imagenet用1000类而不是100类),transfer的效果越好
Q & A(未解决)
数学推导部分















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









