







学柿饼UI,送柿饼M3活动
感谢RT-Thread对我公众号和微信交流群的信任及大力支持,本次活动有RT-Thread提供的柿饼M3模块免费回馈给各位读者及群友。
本次活动主要面向对UI感兴趣,喜欢折腾的朋友们,参与本次活动,你将收获柿饼UI官方的专业指导,加入微信交流群即可与大咖们零距离交流。
参与方式:
报名仅限今天和明天两天时间(11月2号和3号),
参与形式非常简单,提问问题(问题后边留下你的微信号),便有机会获得M3模块(一共十个):
https://docs.qq.com/doc/DQ2pzTWNHUldsR09Y
柿饼UI简介
https://mp.weixin.qq.com/s/60asR4OnWoB7z5MpgJLdkw
柿饼UI以JavaScript语言开发嵌入式GUI的优点:
-
JavaScript开发GUI便捷高效,节省用户大量的界面逻辑开发时间
-
底层核心逻辑和上层业务逻辑分离,负责数据流转、屏幕刷新和设备控制的代码都由C/C++实现,JavaScript不会影响界面帧率
-
柿饼UI支持JavaScript代码压缩、混淆、编译成字节码,对于关键代码可编译成字节码执行,实测执行效率与C基本接近
-
对于大型项目,可有效降低调试内存泄漏BUG的痛苦
-
有较为完善的针对可穿戴设备的低功耗设计
基于柿饼UI的M3模块:
为了能更好的满足大家的使用和“折腾”需求,柿饼UI团队这次不仅做了一款非常小的柿饼模块 —— PersimM3模块,还向广大开发者朋友开放了模块的SDK,大家可以很好的“折腾”底层了,以后换屏神马的都是小事。其中PersimM3模块参数如下:

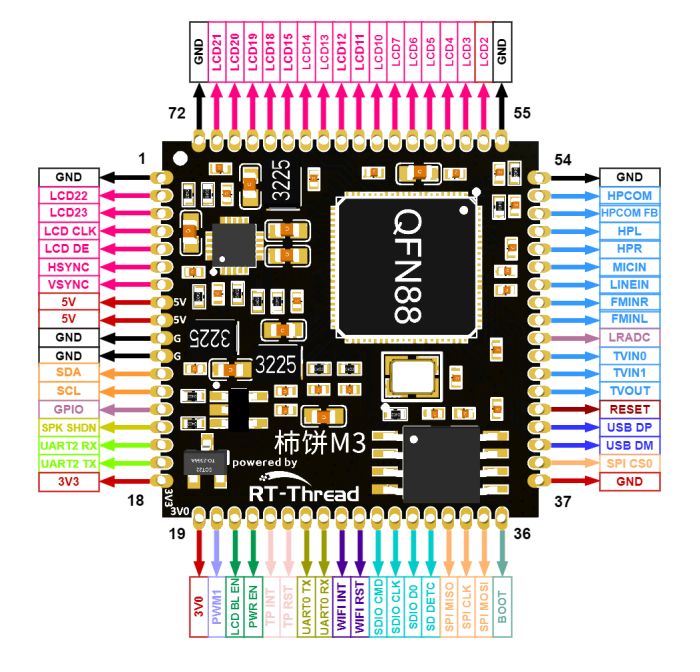
柿饼UI学习资料
柿饼UI的一些资料:
柿饼UI官网:https://www.rt-thread.org/page/persimmonui.html
柿饼M3 SDK下载地址:
奶牛快传:https://realthread.cowtransfer.com/s/9248651f54b94c
百度网盘:https://pan.baidu.com/share/init?surl=RQPUJnCfeeOXGlwLpuUVjw(提取码jnz5)
柿饼派官方文档资料:https://www.rt-thread.org/document/persimmon/site/
B站柿饼UI教程:https://space.bilibili.com/423462075/channel/detail?cid=74036
加群学习
不管有没有获取到柿饼M3模块,只要你对柿饼UI感兴趣,都欢迎加入技术交流群,了解大咖们的学习动态。
QQ群:

关注公众号,后续有精彩内容会第一时间发送给您!

















 1506
1506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











