







论文原文:Discourse-Based Objectives for Fast Unsupervised Sentence Representation Learning
引言
这篇文章的想法很有意思,为了学习到更好的句子表示,作者没有去设计新的模型来学习句子表示,而是设计了3个预训练目标来预训练已有的句子编码器(Sentence encoder),当模型经过这3个预训练后在针对目标任务进行训练。就好比,你要练一门神功,你最好要先练好基本功。作者发现模型学习到的句子表示虽然没有显著得优于当前最新结果,但是训练时间大大减少了。
预训练任务
- Binary Ordering of Sentences
你的模型是用来学习句子表示的是吧?那么你的模型是不是也要能判断两句相邻句子的前后顺序?这就是第一个任务,训练模型能判断两句句子的顺序,作者称之为ORDER。
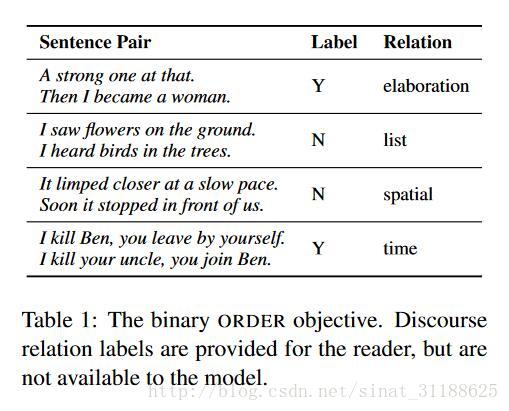
这个表展示了数据集中的4个句子对,如果两句句子排序正确,那么Label就是Y,否则就是N。当然我们不难发现,对于list关系,两个句子是并列的&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









