







[1] Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J]. Journal of machine learning research, 2003, 3(Feb): 1137-1155.
在[1]中Bengio提出了使用神经网络来训练语言模型方法,该语言模型是一个N-gram模型,即通过输入的n-1个单词,来预测第n个单词的概率分布。
Bengio使用了一个简单的三层神经网络:
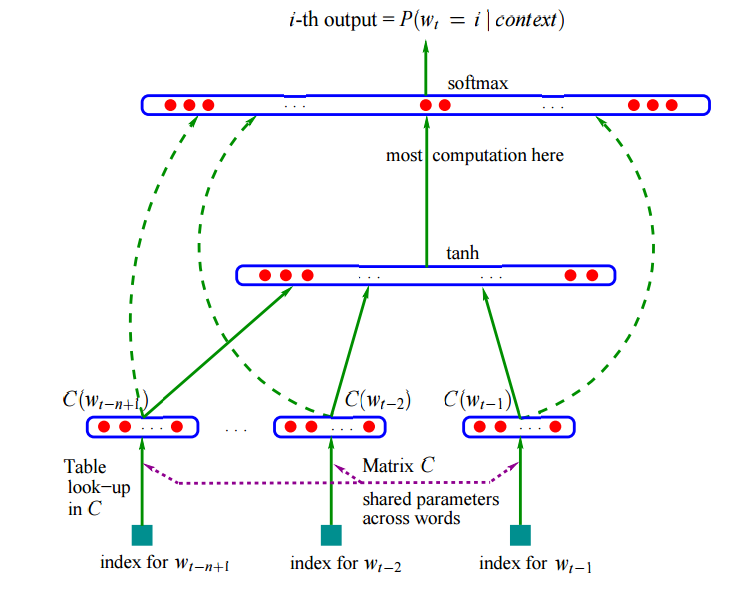
输入层:通过一个映射矩阵C(矩阵的规模为|V|*m,其中|V|是词表大小,m是词向量的维度),将前n-1个离散的单词映射成n-1个m维向量,也就是通过查表的方式将单词变成词向量。然后将这n-1个m维向量首尾相接形成一个m(n-1)的向量,该向量就是神经网络的输入向量x。
隐藏层:隐藏层的节点个数为h,为了将输入层输出的m(n-1)维向量x转化为隐藏层(维度为h)的输入,在输入层和隐藏层之间需要一个参数矩阵H(H的规模为h*m(n-1)),同时需要一个偏置d,该变化可以表示为f(x)=Hx + d,这是一个线性变换。隐藏层的输出需要将经过线性变换的向量在做一次非线性变换,在这里选择的函数为tanh(双曲正切),也就是激活函数。那么我们可以知道隐藏层的输出就是tanh(Hx + d)。
输出层:从隐藏层到输出层的传递同样需要一个线性变换和一个非线性变化,即首先通过线性变换将隐藏层的输出向量的维数转化为和输出层的节点数一致(其实此时已经可以将这个这个值作为输出),但是为了将输出表示成概率分布的形式(每个维度上的值之和为1),我们还需要对输出层的输入(也就是隐藏层的输出)进行一个非线性变换,激活函数为softmax,才能达到我们想要的效果。由于我们希望网络的输出可以对第n个单词的分布做出概率预测,所以输出层的维度为|V|,即整个词表的大小,那么从隐藏层到输出层的参数矩阵U的规模就是|V|*h,
i>如果输入层和输出层之间没有直连边,那么输出层的输入就是y=b+Utanh(Hx + d);
ii>如果输入层和输出层之间有直连边,该变换同样需要一个参数矩阵W(W的规模为|V|*m(n-1)),和一个偏置b,那么输出层的输入就是y=b + Wx + Utanh(d + Hx).
最终输出层的输出就是经过softmax函数激活后的概率:
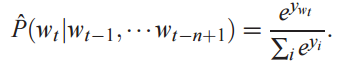
其中,分子就是词w(t)对应的输出,例如单词w(t)在词表的位置是第100个,那么分子就是输出向量的第100维上的值。
该神经网络的参数θ=(b, d, W, U, H, C),而训练模型的方法是和随机梯度下降(SGD)类似的随机梯度上升(SGA)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









