






在本快速入门中,我们将向您展示如何构建一个简单的LLM应用程序。该应用程序将文本从英语翻译成另一种语言。这是一个相对简单的LLM应用程序——它只是一个LLM调用加上一些提示。尽管如此,这仍然是开始使用LangChain的好方法——只需一些提示和一个LLM调用,就可以构建许多功能!
概念
我们将涵盖的概念是:
- 使用语言模型
- 使用PromptTemplates和OutputParsers
- 使用LangChain链接PromptTemplate + LLM + OutputParser
- 使用LangSmith调试和跟踪您的应用程序
- 使用LangServe部署您的应用程序
这是一些需要涵盖的内容!让我们开始吧。
目标
在本文档中,我们将构建一个应用程序,实现:利用大语言模型,将用户输入从一种语言翻译成另一种语言。
环境设置
Jupyter Notebook
本指南(以及留档中的大多数其他指南)使用 Jupyter 笔记本 。Jupyter笔记本非常适合学习如何使用LLM系统,因为经常会出错(意外输出、API关闭等),在交互式环境中浏览指南是更好地理解它们的好方法。
安装 LangChain
要安装LangChain,请运行:
pip install langchain有关更多详细信息,请参阅我们的安装指南。
LangSmith
我们使用 LangChain 构建的许多应用程序都包含多个步骤和多次调用LLM调用。随着这些应用程序变得越来越复杂,能够检查链或代理内部发生的情况变得至关重要。最好的方法是使用 LangSmith。
注册 LangSmith
LangSmith 在链接上注册后,请确保设置您的环境变量以开始记录跟踪:
export LANGCHAIN_TRACING_V2="true"
export LANGCHAIN_API_KEY="..."或者,如果在笔记本中,您可以使用以下方式设置它们:
import getpass
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()创建API密钥
要创建 设置页面 的API密钥头。然后单击创建API密钥。
安装 LangSmith 依赖
pip install -U langsmith至此,我们的初步准备工作已完成。
LangServe
LangServe 帮助开发者部署 LangChain 可运行文件和链作为 REST API。
安装 LangServe
安装客户端和服务器:
pip install "langserve[all]"或者只安装客户端:
pip install "langserve[client]"只安装服务器
pip install "langserve[server]"先介绍到这,下面会讲解如何部署和调用我们的 LangChain 程序。
选择大语言模型
首先,让我们学习如何单独使用语言模型。LangChain 支持许多不同的语言模型,您可以选择想要使用的模型!
选择 openai
pip install -qU langchain-openaiimport getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4")选择 gemini
pip install -qU langchain-google-vertexai
import getpass
import os
os.environ["GOOGLE_API_KEY"] = getpass.getpass()
from langchain_google_vertexai import ChatVertexAI
model = ChatVertexAI(model="gemini-pro")选择通义千问
如何拿到阿里云灵积模型服务的 apikey ?
链接:阿里云开发者社区-云计算社区-阿里云 (aliyun.com)
- 登录或者注册:点击右上角进行注册账号,有账号的可以直接登录
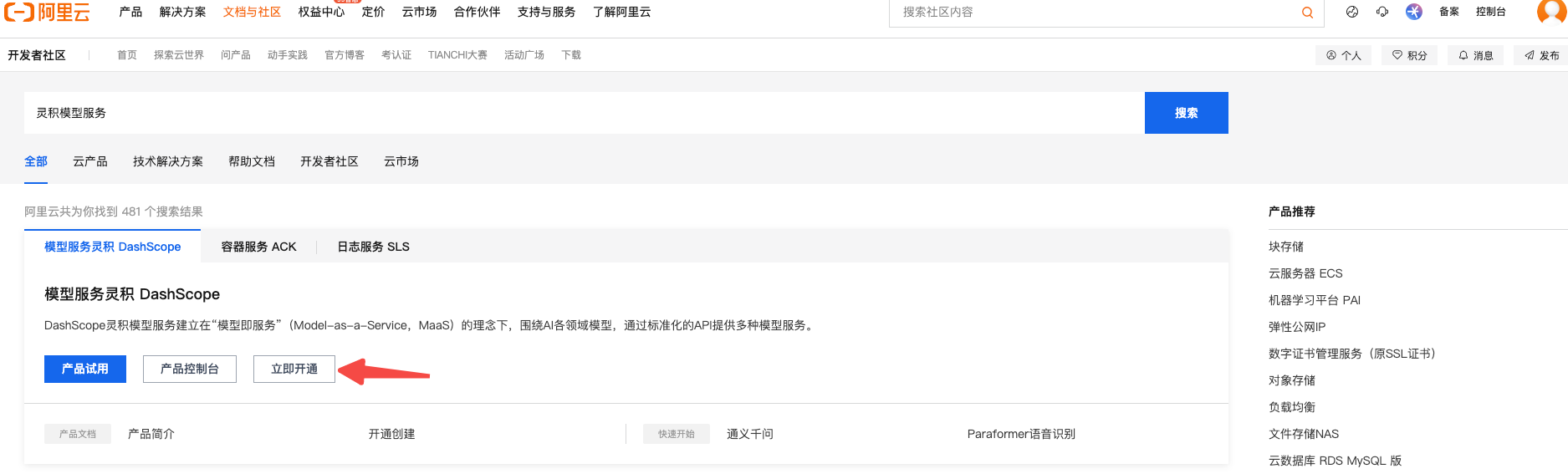
- 搜索灵积模型服务,开通服务
- 进入产品控制台,创建api-key,api-key要好好保存,如果不慎遗失了,可以在查看这个key
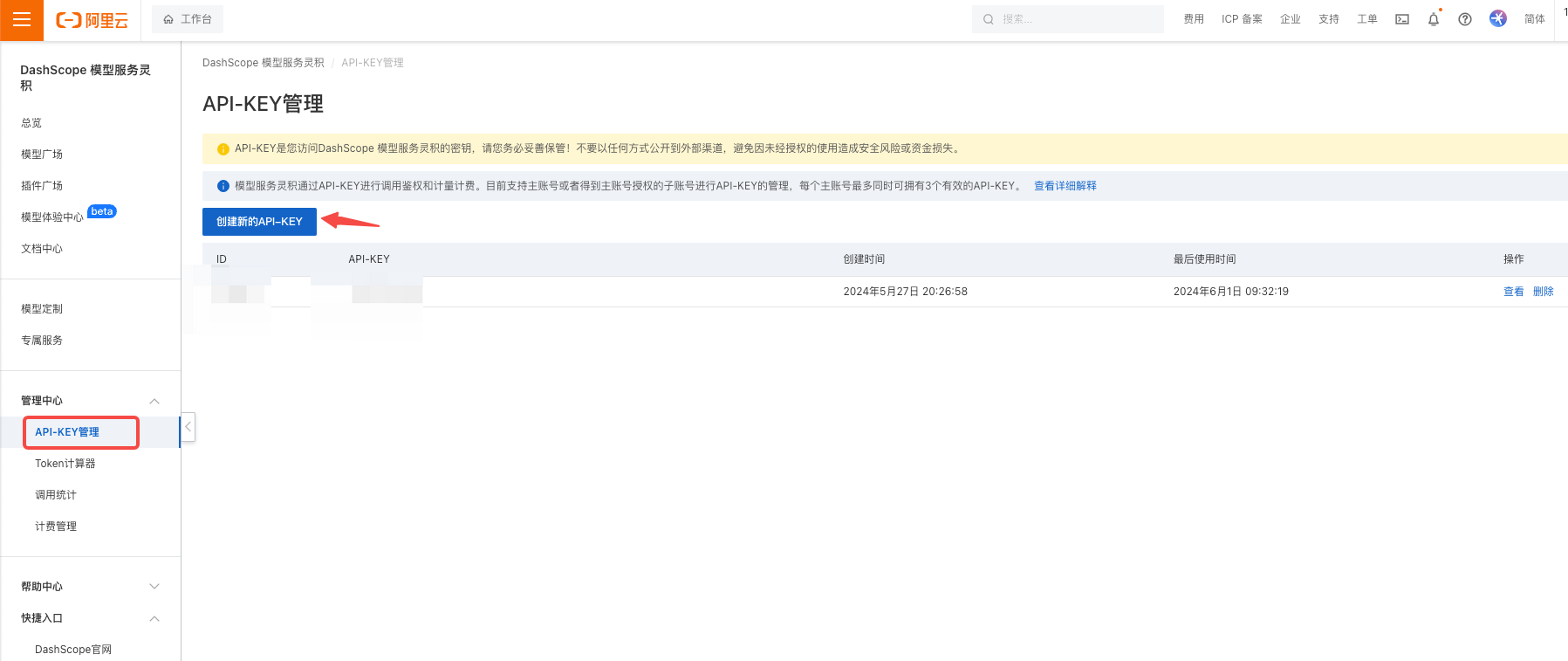
- 设置 API-KEY
export DASHSCOPE_API_KEY="你的apikey"
然后让我们直接使用模型。ChatModel 是 LangChain“Runnables”的实例,这意味着它们公开了一个与它们交互的标准接口。要简单地调用模型,我们可以将消息列表传递给 .invoke 方法。
from langchain_community.llms import Tongyi
from langchain_core.messages import HumanMessage, SystemMessage
# 使用 Tongyi LLM,并设置温度为 1,代表模型会更加随机,但也会更加不确定
llm = Tongyi(temperature=1)
# 创建一个系统消息,并将它添加到消息列表中
# 系统消息用于指定模型应该如何理解用户输入
messages = [
SystemMessage(content="将以下内容从英文翻译成中文:"),
HumanMessage(content="hi!"),
]
# 运行
result = llm.invoke(messages)
# 打印结果
print(result)API参考:HumanMessage | SystemMessage
输出打印结果: 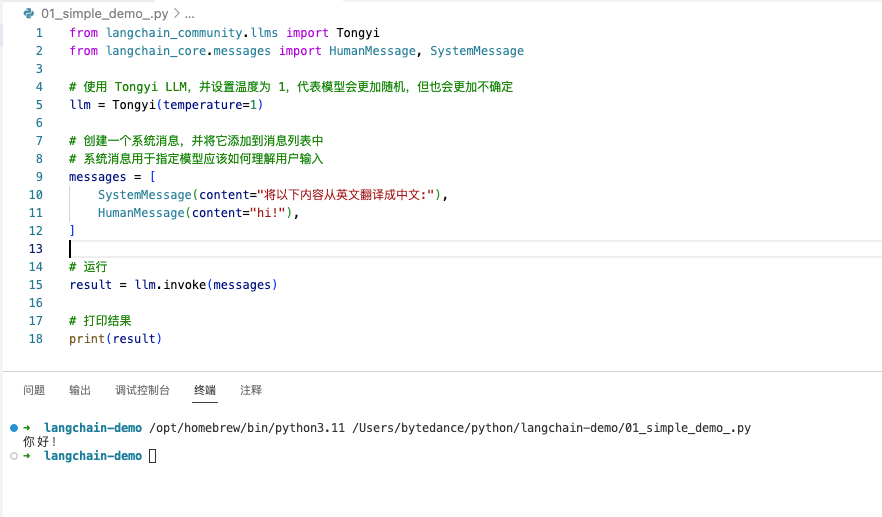
如果我们启用了LangSmith,我们可以看到此运行已记录到 LangSmith,并可以查看LangSmith的跟踪。 运行记录
OutputParsers
请注意,来自模型的响应是一个 AIMessage 。这包含一个字符串响应以及关于响应的其他元数据。通常我们可能只想使用字符串响应。我们可以使用简单的输出解析器解析出这个响应。
我们首先导入简单的输出解析器。
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()API参考:StrOutputParser
使用它的一种方法是单独使用它。例如,我们可以保存语言模型调用的结果,然后将其传递给解析器。
result = model.invoke(messages)
parser.invoke(result)完整代码:
from langchain_community.llms import Tongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
# 使用 Tongyi LLM,并设置温度为 1,代表模型会更加随机,但也会更加不确定
llm = Tongyi(temperature=1)
# 创建一个系统消息,并将它添加到消息列表中
# 系统消息用于指定模型应该如何理解用户输入
messages = [
SystemMessage(content="将以下内容从英文翻译成中文:"),
HumanMessage(content="hi!"),
]
# 创建一个输出解析器,用于解析模型输出的文本
parser = StrOutputParser()
# 运行
result = llm.invoke(messages)
# 使用输出解析器解析模型输出的文本
parserResult = parser.invoke(result)
# 打印结果
print(parserResult)LangSmith 跟踪记录: 
创建链运行
更常见的是,我们可以用这个输出解析器“链接”模型。这意味着在这个链中每次都会调用这个输出解析器。这个链接受语言模型的输入类型(字符串或消息列表),并返回输出解析器的输出类型(字符串)。
我们可以使用 | 运算符轻松创建链。| 运算符在 LangChain 中用于将两个元素组合在一起。
chain = model | parser
chain.invoke(messages)完整代码:
from langchain_community.llms import Tongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
# 使用 Tongyi LLM,并设置温度为 1,代表模型会更加随机,但也会更加不确定
llm = Tongyi(temperature=1)
# 创建一个系统消息,并将它添加到消息列表中
# 系统消息用于指定模型应该如何理解用户输入
messages = [
SystemMessage(content="将以下内容从英文翻译成中文:"),
HumanMessage(content="hi!"),
]
# 创建一个输出解析器,用于解析模型输出的文本
parser = StrOutputParser()
# 将 LLM 和输出解析器连接起来,轻松创建链
chain = llm | parser
# 运行
result = chain.invoke(messages)
# 打印结果
print(result)如果我们现在看看 LangSmith,我们可以看到链有两个步骤:首先调用语言模型,然后将结果传递给输出解析器。我们可以看到 LangSmith 跟踪记录。 RunnableSequence 日志 StrOutputParser 日志 
Prompt Templates
现在我们正在将消息列表直接传递到语言模型中。这个消息列表来自哪里?
通常它是由用户输入和应用程序逻辑的组合构成的。这个应用程序逻辑通常接受原始用户输入,并将其转换为准备传递给语言模型的消息列表。常见的转换包括添加系统消息或使用用户输入格式化模板。
PromptTemplate 是 LangChain 中的一个概念,旨在帮助实现这种转换。它们接受原始用户输入并返回准备传递到语言模型的数据(提示)。
让我们在这里创建一个PromptTemplate。它将接受两个用户变量:
- language: 将文本翻译成的语言
- text: 要翻译的文本
from langchain_core.prompts import ChatPromptTemplateAPI参考 : ChatPromptTemplate
首先,让我们创建一个字符串,我们将其格式化为系统消息:
system_template = "将以下内容翻译成{language}:"接下来,我们可以创建 PromptTemplate。这是 system_template 以及一个更简单的模板,用于放置文本
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)这个提示模板的输入是字典。我们可以自己玩这个提示模板,看看它自己做了什么
result = prompt_template.invoke({"language": "italian", "text": "hi"})我们可以看到它返回一个 ChatPromptValue 由两条消息组成。如果我们想直接访问消息,我们会这样做:
result.to_messages()我们现在可以将其与上面的模型和输出解析器结合起来。这将把所有三个组件链接在一起。
chain = prompt_template | model | parser
chain.invoke({"language": "italian", "text": "hi"})完整代码:
from langchain_community.llms import Tongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
# 使用 Tongyi LLM,并设置温度为 1,代表模型会更加随机,但也会更加不确定
llm = Tongyi(temperature=1)
system_template = "将以下内容从英文翻译成{language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
# 创建一个输出解析器,用于解析模型输出的文本
parser = StrOutputParser()
# 将 LLM 和输出解析器连接起来,轻松创建链
chain = prompt_template | llm | parser
# 运行
result = chain.invoke({"language": "chinese", "text": "hi"})
# 打印结果
print(result)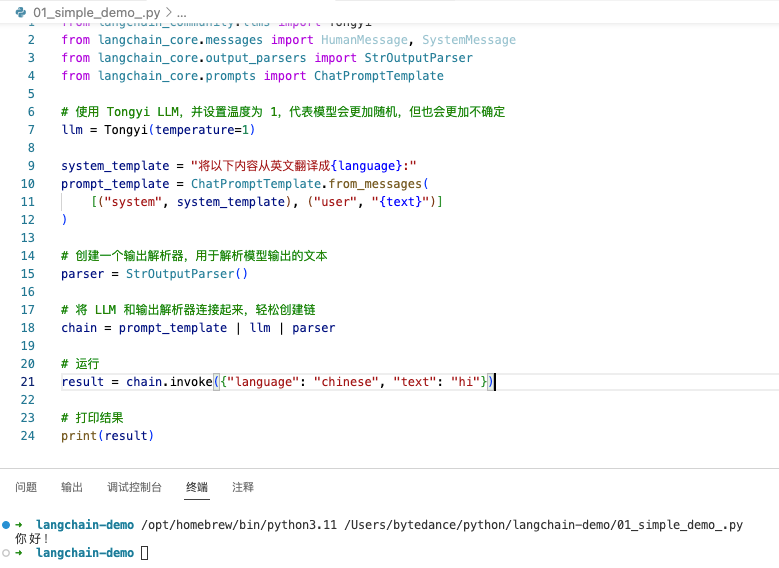
如果我们查看 LangSmith 跟踪,我们可以看到所有三个组件都显示在 LangSmith 跟踪中。 运行日志 
LangServe 部署示例
这是一个部署OpenAI聊天模型的服务器,实现文字翻译的应用。
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes
from langchain_community.llms import Tongyi
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from fastapi.middleware.cors import CORSMiddleware
# 使用 Tongyi LLM,并设置温度为 1,代表模型会更加随机,但也会更加不确定
llm = Tongyi(temperature=1)
# 提示模版
system_template = "将以下内容从英文翻译成{language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
# 创建一个输出解析器,用于解析模型输出的文本
parser = StrOutputParser()
# 创建应用
app = FastAPI(
title="LangChain Server",
version="1.0",
description="使用 Langchain 的 Runnable 接口的简单 api 服务器",
)
# 设置所有启用 CORS 的源
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
expose_headers=["*"],
)
# 添加路由
add_routes(
app,
prompt_template | llm | parser,
path="/trans",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)上面的 api 服务启动之后,可以使用 curl 调用,查看返回结果。
curl --location --request POST 'http://localhost:8000/trans/invoke' \
--header 'Content-Type: application/json' \
--data-raw '{
"input": {
"language": "chinese",
"text": "hi"
}
}'API 服务启动: 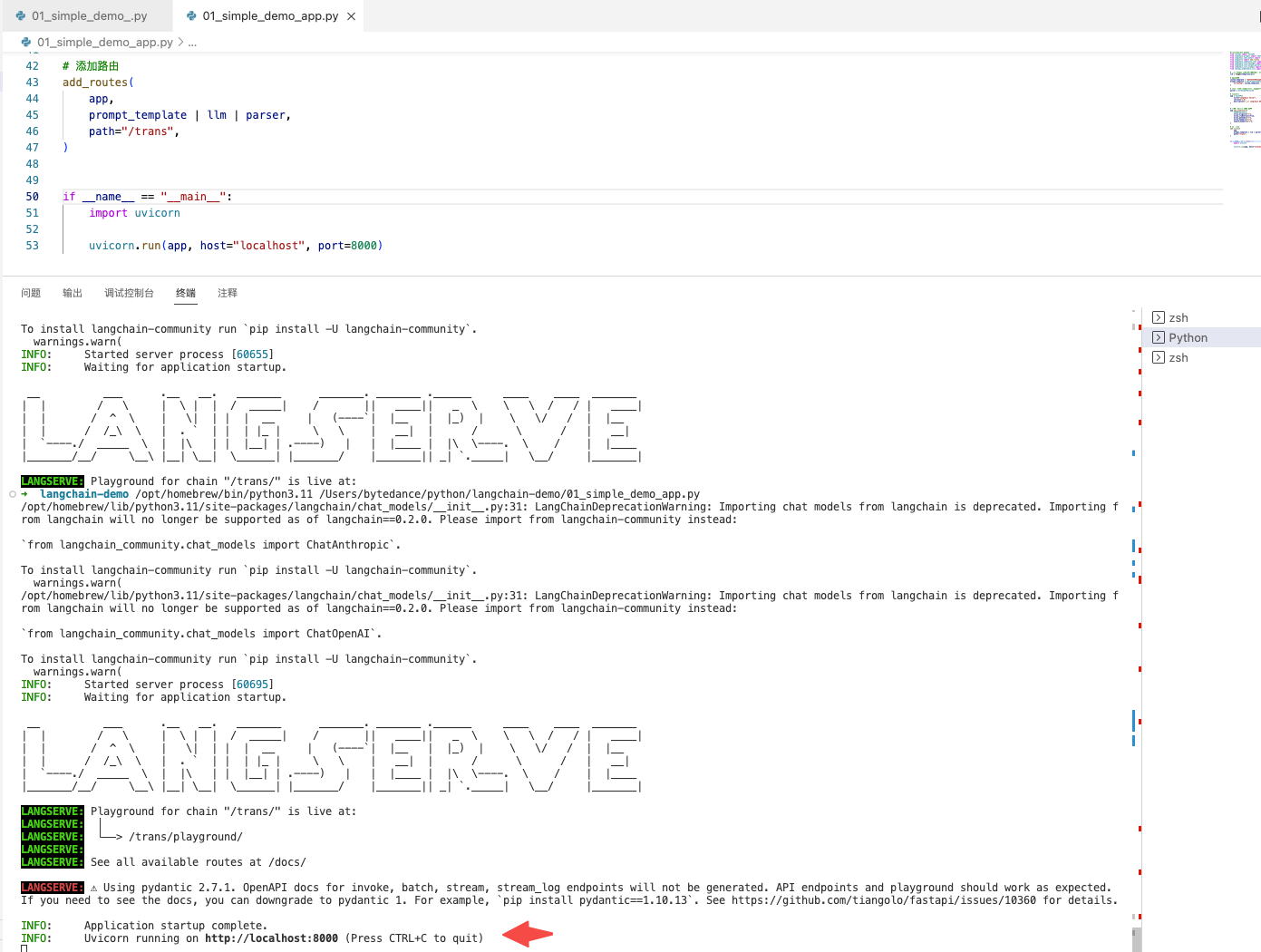
API 调用结果: 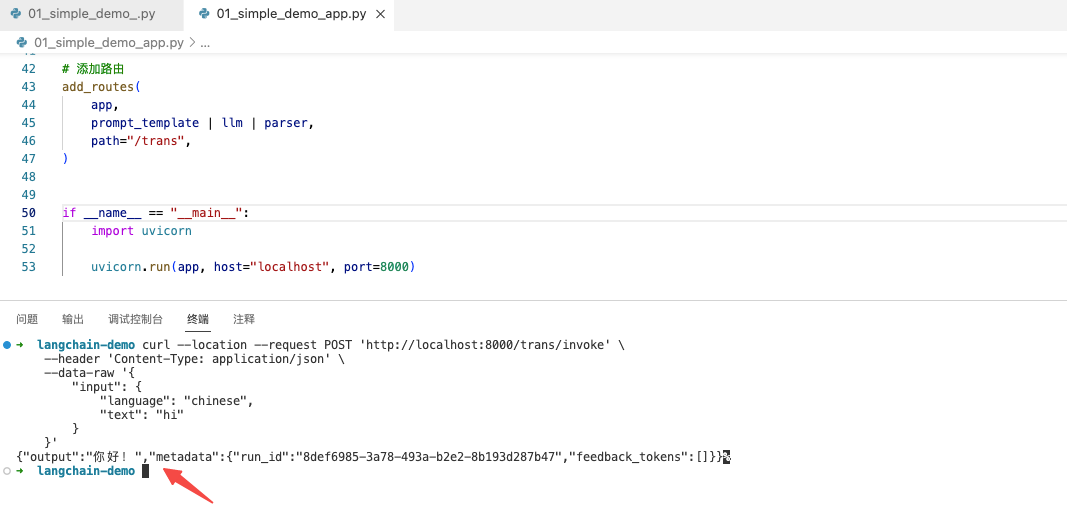
LangSmith 观察结果:运行日志 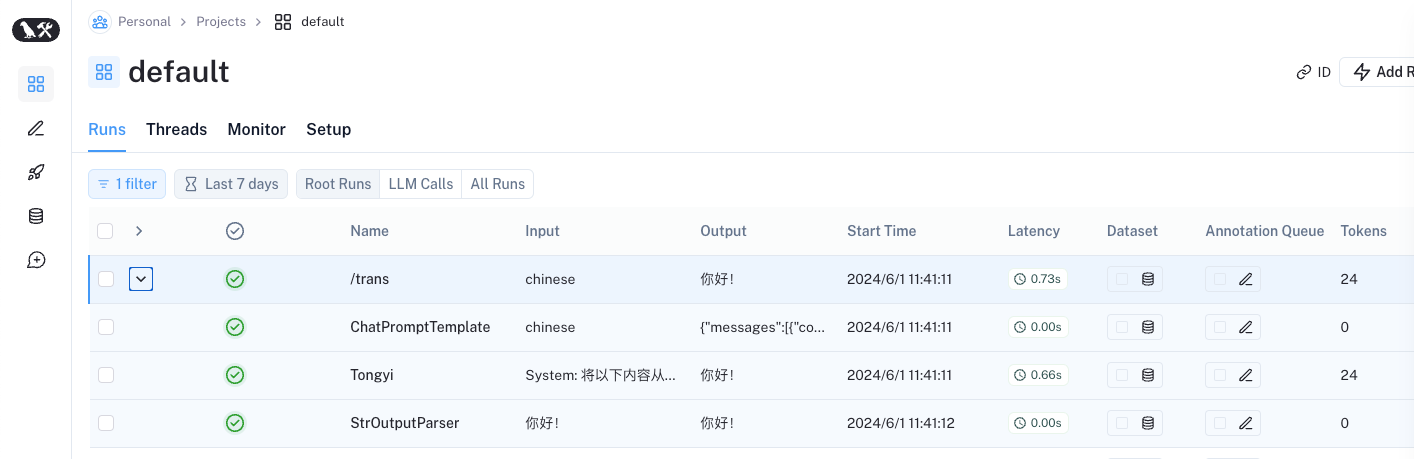
小结
在本教程中,我们已经完成了创建第一个简单的LLM应用程序。
我们已经学习了如何使用语言模型,如何解析它们的输出,如何创建提示模板,如何在您使用 LangSmith 创建的链中获得出色的可观察性,以及如何使用LangServe部署它们。
这只是触及了您想要学习成为一名熟练的AI工程师的表面。幸运的是——我们有很多其他资源! 有关更深入的教程,请查看 官方教程 部分。
欢迎关注微信公众号【千练极客】,尽享更多干货文章! 
本文由博客一文多发平台 OpenWrite 发布!















 1782
1782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









