







0.准备工作
更新Pandas,打开Anaconda Prompt进入命令行界面,输入下列代码
pip install --upgrade pandas
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pandas #加上清华源更快1.文件的读写
1.1. 主要读取文件的代码
df = pd.read_csv('地址+文件名.csv') #以当前的python文件所在的位置作为根目录上面是读取CSV文件,操作比较容易。对于目前用到的一个数据集为txt格式,空格分隔各个元素。读取时需要对分隔符做下注明,对比如下:
df_txt = pd.read_table('data/annotations.txt')
df_txt 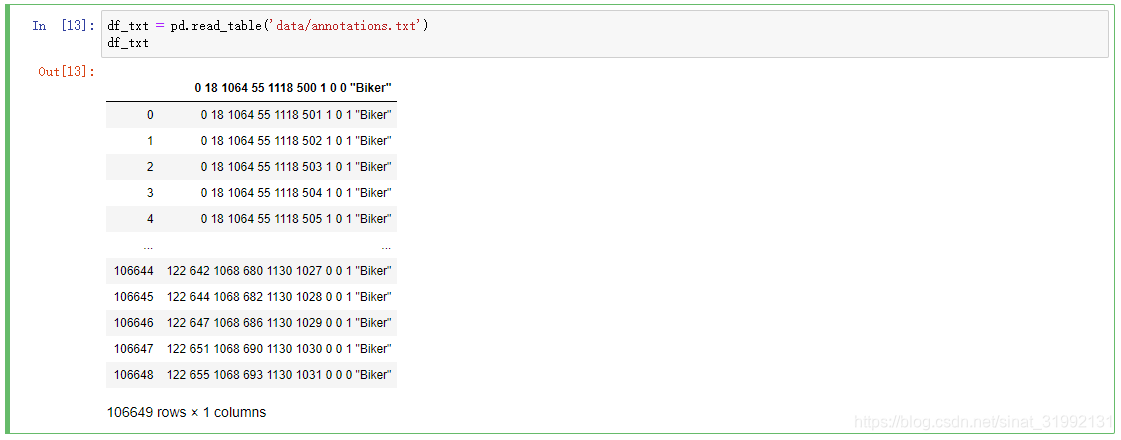
df_txt = pd.read_table('data/annotations.txt',sep=' ')
df_txt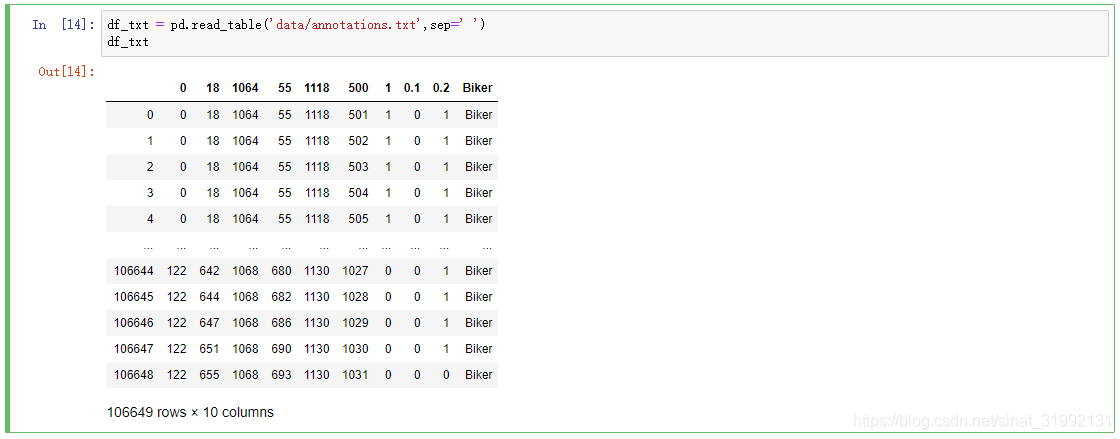
1.2. 对于写入操作,把当前的数据导出到文件
df.to_csv('data/new_table.csv')
#df.to_csv('data/new_table.csv', index=False) #保存时除去行索引索引为数据最左侧的编号
2.基本数据结构
series一维数据
dataframe二维数据,为series的容器
创建,访问元素,调用
3.常用函数
3.1. head和tail显示头尾数据
3.2. unique和nunique显示唯一值和唯一值的个数
3.3. count和value_counts非缺失值个数和各元素的个数
3.4. describe和info数据的描述
3.5. idxmax和nlargest最大值和返回前几个大的元素值
3.6. clip和replace是两类替换函数,需注意是在原表上替换还是返回替换后的
4.排序
设置索引排序
值排序
df.sort_values(by=['Address','Height']).head()














 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









