







1.tf.nn.l2_loss
tf.nn.l2_loss(t, name=None)
L2 Loss.Computes halfthe L2 normofa tensorwithoutthesqrt:
这个函数的作用是利用 L2 范数来计算张量的误差值,但是没有开方并且只取 L2 范数的值的一半
output =sum(t **2) /2
Args:
t: A Tensor. Must beoneofthe following types: float32, float64, int64, int32, uint8, int16, int8, complex64, qint8, quint8, qint32.
Typically2-D, but may haveany dimensions.
name: A nameforthe operation (optional).
Returns:A Tensor. Hasthe same typeas t.0-D.
2.tf.nn.softmax(logits, name=None)
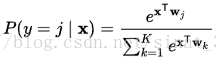
计算softmax
softmax[i, j] = exp(logits[i, j]) / sum_j(exp(logits[i, j]))
将神经网络前向传播得到的结果变成概率分布
tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,
因为它在函数内部进行sigmoid或softmax操作
3.tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
这个函数的作用是计算 logits 经 softmax 函数激活之后的交叉熵

注意:如果labels的每一行是one-hot表示,也就是只有一个地方为1,其他地方为0,
可以使用tf.sparse_softmax_cross_entropy_with_logits()
计算logits和labels的softmax交叉熵 logits, labels必须为相同的shape与数据类型
输入logits,shape是[batch_size, num_classes] ;labels,shape也是[batch_size, num_classes],神经网络期望的输出
output:lossshape:[batch_size]
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率
对于单样本而言,输出就是一个num_classes
第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵

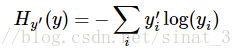
这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,
我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,
最后才得到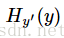
tf.reduce_mean操作,对向量求均值!
- import tensorflow as tf
- #our NN's output
- logits=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
- #step1:do softmax
- y=tf.nn.softmax(logits)
- #true label
- y_=tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]])
- #step2:do cross_entropy
- cross_entropy = -tf.reduce_sum(y_*tf.log(y))
- #do cross_entropy just one step
- cross_entropy2=tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits, y_))#dont forget tf.reduce_sum()!!
- with tf.Session() as sess:
- softmax=sess.run(y)
- c_e = sess.run(cross_entropy)
- c_e2 = sess.run(cross_entropy2)
- print("step1:softmax result=")
- print(softmax)
- print("step2:cross_entropy result=")
- print(c_e)
- print("Function(softmax_cross_entropy_with_logits) result=")
- print(c_e2)
-
- step1:softmax result=
- [[ 0.09003057 0.24472848 0.66524094]
- [ 0.09003057 0.24472848 0.66524094]
- [ 0.09003057 0.24472848 0.66524094]]
- step2:cross_entropy result=
- 1.22282
- Function(softmax_cross_entropy_with_logits) result=
- 1.2228
4.tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, name=None)
labels 的输入是稀疏表示的,是 [0,num_classes)中的一个数值,代表正确分类 。labels 的 shape为 [batch_size],即 有batch个数值
logits 是神经网络运行的结果(tensorflow神经网络中没有softmax层,而是在此方法会进行softmax运算)。
logits 的shape是 [batch_size,num_classes],即 batch数*类别数的矩阵
sparse_softmax_cross_entropy_with_logits 直接用标签上计算交叉熵,
而 softmax_cross_entropy_with_logits 是标签的onehot向量参与计算。
softmax_cross_entropy_with_logits 的 labels 是 sparse_softmax_cross_entropy_with_logits 的
labels 的一个独热版本(one hot version)。
一般的使用
5.tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;shape:[batch_size,num_classes],单样本是[num_classes]
labels:和logits具有相同的type(float)和shape的张量(tensor),
name:操作的名字,可填可不填
output:
loss,shape:[batch_size,num_classes]
Note:
它对于输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出
它适用于每个类别相互独立但互不排斥的情况:例如一幅图可以同时包含一条狗和一只大象
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用
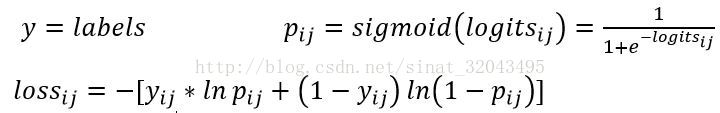
Python 程序:
importtensorflowas tf
import numpy asnp
def sigmoid(x):
return 1.0/(1+np.exp(-x))
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]]
# 5个样本三分类问题,且一个样本可以同时拥有多类
logits = np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])
y_pred = sigmoid(logits)E1 = -y*np.log(y_pred)-( 1-y)*np.log( 1-y_pred)
print(E1) # 按计算公式计算的结果
sess =tf.Session()
y = np.array(y).astype(np.float64) # labels是float64的数据类型
E2 = sess.run(tf.nn.sigmoid_cross_entropy_with_logits( labels=y, logits=logits))
print(E2)
6.tf.nn.weighted_cross_entropy_with_logits(labels,logits, pos_weight, name=None)
计算具有权重的sigmoid交叉熵sigmoid_cross_entropy_with_logits()
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes],单样本是[num_classes]
labels:和logits具有相同的type(float)和shape的张量(tensor),
pos_weight:正样本的一个系数
name:操作的名字,可填可不填
output:
loss,shape:[batch_size,num_classes]
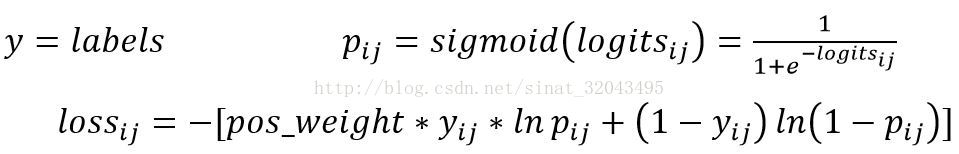
7.tf.losses.absolute_difference
绝对差分公式(也称为L1损失)
absolute_difference(
labels,
predictions,
weights=1.0,
scope=None,
loss_collection=tf.GraphKeys.LOSSES,
reduction=Reduction.SUM_BY_NONZERO_WEIGHTS
)
Adds an Absolute Difference loss to the training procedure.
weights acts as a coefficient for the loss. If a scalar is provided, then the loss is simply scaled by the given value.
If weights is a Tensor of shape [batch_size], then the total loss for each sample of the batch is
rescaled by the corresponding element in the weights vector.
If the shape of weights matches the shape of predictions, then the loss of each measurable element of predictions
is scaled by the corresponding value of weights.
Args:
· labels: The ground truth output tensor, same dimensions as 'predictions'.
· predictions: The predicted outputs.
· weights: Optional Tensor whose rank is either 0, or the same rank as labels, and must be broadcastable to labels (i.e., all dimensions must be either 1, or the same as the corresponding losses dimension).
· scope: The scope for the operations performed in computing the loss.
· loss_collection: collection to which this loss will be added.
· reduction: Type of reduction to apply to loss.
Returns:
Weighted loss float Tensor. If reduction is NONE, this has the same shape as labels; otherwise, it is scalar.
8.tf.losses.mean_squared_error(predictions, targets)
使用均方误差(MSE;也称为L2损耗)
9.tf.losses.hinge_loss
Hinge损失是0-1损失函数的一种代理函数,Hinge损失的具体形式如下:
max(0,1-m)
参考来自:
http://blog.csdn.net/mao_xiao_feng/article/details/53382790
http://blog.csdn.net/QW_sunny/article/details/72885403














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









