






 该博客介绍了Go语言中纯英文字符串和中英文混合字符串的处理。对于纯英文字符串,可直接用函数处理。而中英文混合字符串,不同方法结果不同,一种得字节数,不适用统计;另两种可统计字符数,其中转成特定类型操作更方便,建议采用。
该博客介绍了Go语言中纯英文字符串和中英文混合字符串的处理。对于纯英文字符串,可直接用函数处理。而中英文混合字符串,不同方法结果不同,一种得字节数,不适用统计;另两种可统计字符数,其中转成特定类型操作更方便,建议采用。
Go语言获取中英文混合字符串长度
1. 纯英文字符串
使用len()函数。
testString1 := "China!"
length1 := len(testString1)
fmt.Printf("testString1 字符串的长度是:%d", length1)
长度是6。
2. 中英文混合字符串
2.1 先使用len()函数。
testString2 := "我爱你中国,我爱你China!"
length2 := len(testString2)
fmt.Printf("字符串的长度是:%d", length2)
fmt.Printf("testString2字符串的长度是:%d\n", length2)
fmt.Printf("testString2中的最后一个字符是:%s\n", testString2[length2-1])
fmt.Printf("testString2中的最后一个字符是:%c\n", testString2[length2-1])
fmt.Printf("testString2中的下标6-末尾的子字符串是:%s\n",testString2[:15])
fmt.Printf("testString2中的下标6-末尾的子字符串是:%s\n",testString2[:16])
这种方法的到的是字节数。Go语言中,中文字符按utf-8编码,占3字节,故长度是31。故此方法不适用统计中英文混合或者中文字符串长度。
2.2 使用utf8.RuneCountInString()方法。
testString2 := "我爱你中国,我爱你China!"
length3 := utf8.RuneCountInString(testString2)
fmt.Printf("使用utf8中的方法统计的字符串长度是:%d\n", length3)
此方法可统计字符数,输出结果是15。
2.3 转成[]rune类型,再对此类型进行操作
testString2 := "我爱你中国,我爱你China!"
temp := []rune(testString2)
length4 := len(temp)
fmt.Printf("使用rune统计的字符串的长度是:%d\n", length4)
//获取字符串中最后一个字符
lastChar := string(temp[length4-1])
//获取下标从0到3(不包括3)的子串
subString1 := temp[0:3]
subString2 := temp[6:9]
fmt.Printf("testString2中的最后一个字符是:%s\n", lastChar)
fmt.Printf("testString2中的下标0-2的子字符串是:%s\n",string(subString1))
fmt.Printf("testString2中的下标6-8的子字符串是:%s\n",string(subString2))
此方法也可输出字符个数15。但是此方法能获取指定下标范围的子字符串,也能获取指定下标位置的字符。比第二种方法方便。
3.示例代码
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
//纯英文
testString1 := "China!"
length1 := len(testString1)
fmt.Printf("testString1字符串的长度是:%d\n", length1)
lastCharA := testString1[length1-1]
//此处用%s格式输出最后一个字符会出错,只能用%c
fmt.Printf("testString1字符串中最后一个字符是:%s\n", lastCharA)
fmt.Printf("testString1字符串中最后一个字符是:%c\n", lastCharA)
fmt.Printf("testString1中的下标0-2的子字符串是:%s\n",testString1[0:3])
fmt.Printf("testString1中的下标3-末尾的子字符串是:%s\n",testString1[3:])
fmt.Println()
//中英文加一起15个字符
testString2 := "我爱你中国,我爱你China!"
//此处长度是输出字节数,Go语言中文字符是UTF-8编码,长度3字节,故此处应该是15+1+9+6=31
length2 := len(testString2)
fmt.Printf("testString2字符串的长度是:%d\n", length2)
fmt.Printf("testString2中的最后一个字符是:%s\n", testString2[length2-1])
fmt.Printf("testString2中的最后一个字符是:%c\n", testString2[length2-1])
fmt.Printf("testString2中的下标6-末尾的子字符串是:%s\n",testString2[:15])
fmt.Printf("testString2中的下标6-末尾的子字符串是:%s\n",testString2[:16])
fmt.Println()
//此处就是统计字符数
length3 := utf8.RuneCountInString(testString2)
fmt.Printf("使用utf8中的方法统计的字符串长度是:%d\n", length3)
fmt.Println()
//转成rune类型,再统计字符数
temp := []rune(testString2)
//获取中英文混合字符串长度
length4 := len(temp)
fmt.Printf("使用rune统计的字符串的长度是:%d\n", length4)
//获取字符串中最后一个字符
lastCharB := string(temp[length4-1])
//获取下标从0到3(不包括3)的子串
subString1 := temp[0:3]
subString2 := temp[6:]
fmt.Printf("testString2中的最后一个字符是:%s\n", lastCharB)
fmt.Printf("testString2中的下标0-2的子字符串是:%s\n",string(subString1))
fmt.Printf("testString2中的下标6-末尾的子字符串是:%s\n",string(subString2))
}
4. 示例结果
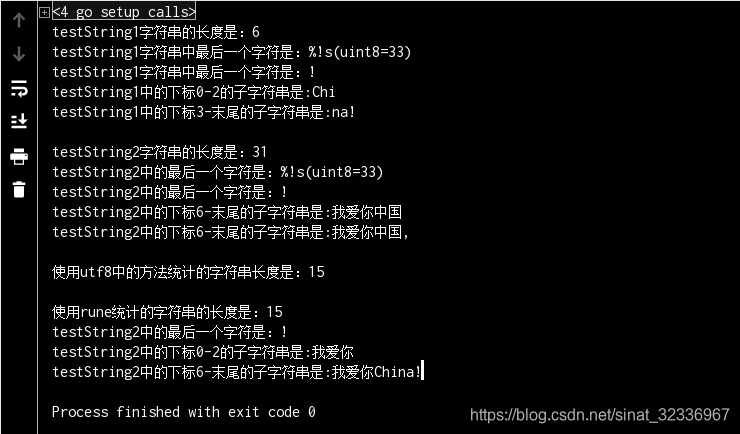
总结
如果是对中英文进行操作,建议用第三种方式。先转成rune[]型,再进行操作。

















 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









