






我们经常会碰到一些关于字符的问题,这里我做了一下整理。
获取全字符表:
#include<stdio.h>
#define BLOCK 80
int main() //获取Unicode码表
{
for(int lc=0x20; lc < 0xff*BLOCK; printf("%lc",lc++))
// if((lc+1)%256==0)printf("\r\n%04X\r\n",lc) //这行显示区块码,可注释掉
;return 0; //为了方便注释,将上一行的分号移到了这一行的行首
}获取字符的二进制码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <wchar.h>
int main() //输出字符的utf8码及unicode编码
{
char str[]= "华夏文明";
wchar_t wstr[100];
int i,byte; //循环控制变量
mbstowcs(wstr,str,strlen(str)+1); //转换函数
for(byte = 0; str[byte]!= 0; byte ++){ //输出当前编码的16进制码
if( str[1]==0)printf("%6x",(str[byte]));
else printf("%x",(str[byte]));
if(str[byte+1] == 0)
printf(" ");}
for(byte = 0; str[byte]!= 0; byte ++){
if( str[1]==0)printf(" ");
for(I = 7 ; i>=0 ; i-- )//8位字符所以二进制数从0开始到8结束,共8位
{
printf("%d",(str[byte] >> i ) & 1);//输出第i位的值
if(i==0) printf(" ");
}
}
printf("Utf-8");
printf(" %s",str);
printf("\r\n");
for(int i=0;i<wcslen(wstr);i++) //Unicode码宽字符
{
printf("%6x",wstr[i]);
}
for(int j=0;j<wcslen(wstr);j++){
printf(" "); // 8位对齐
// printf(" "); // 6位对齐
for(i = 15 ; i>=0 ; i-- )//8位字符所以二进制数从0开始到8结束,共8位
{
if(i%8==7) printf(" "); // 8位对齐,i%8==7与i%6==5 效果差别大
// if(i%6==5) printf(" "); // 6位对齐 效果差别大
printf("%d",(wstr[j] >> i ) & 1);//输出第ibit的值
}
}
printf(" Unicode");
return 0;
}输出效果(ASCII字符):
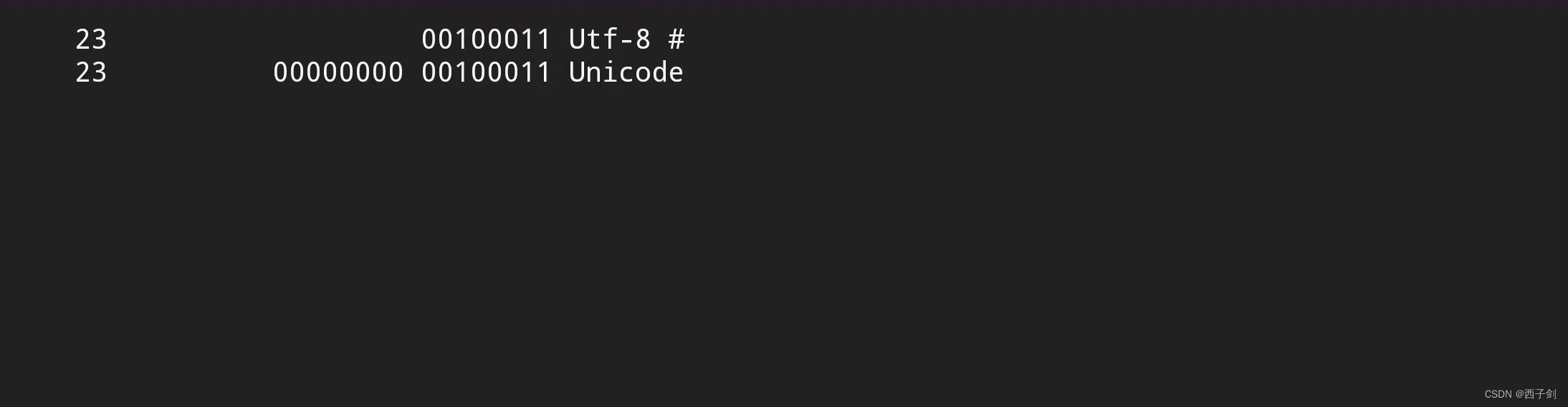
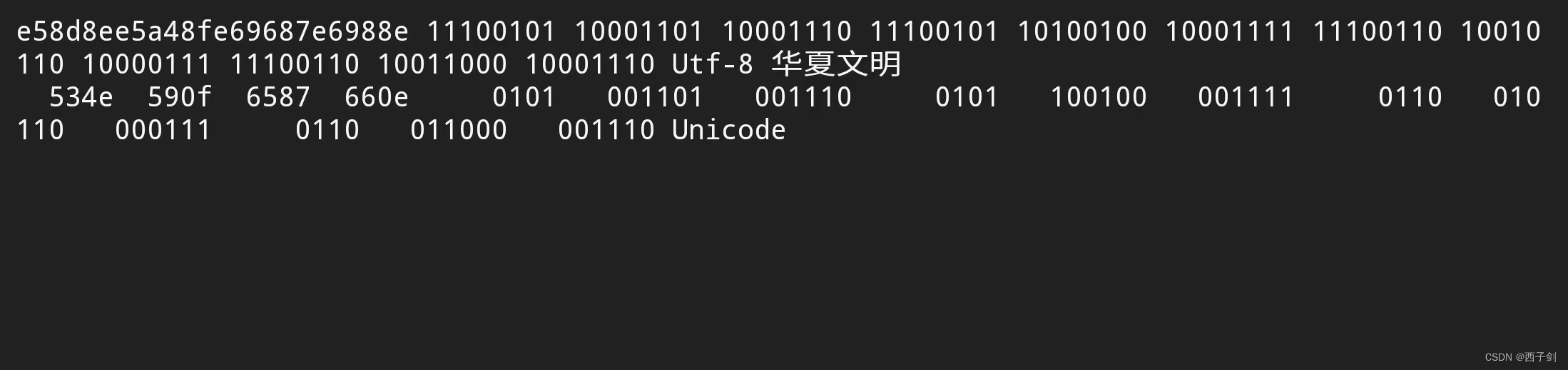
中文字符输出效果(6位对齐):
 中文字符输出效果(8位对齐):
中文字符输出效果(8位对齐):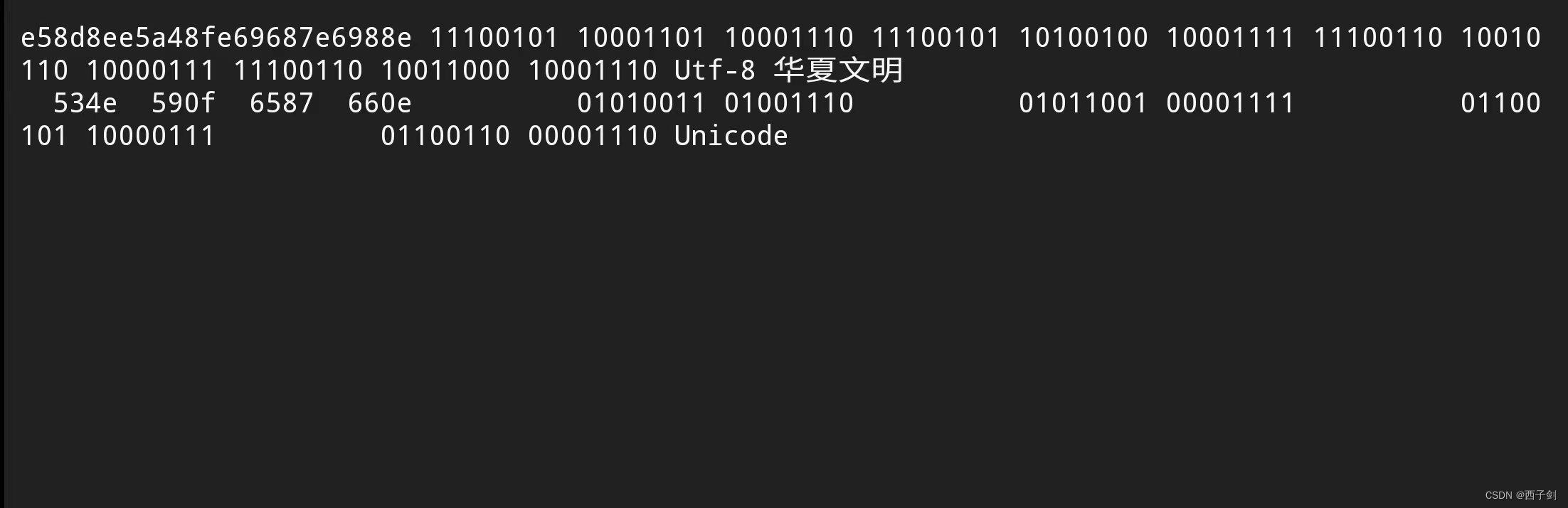
















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











