







最近一直想研究一下大数据Hadoop, 但是用了整整一个周末,也没发现合适的资料,还在京东了买了两本书,按照书上的说明,最后环境搭建失败了,估计是hadoop 对技术要求太高了。所以我就换到Spark上来研究一下。
之前安装过python,因为启动PySpark 需要使用python。但是启动时,却遇到错误,先在这里记录问题修复的过程,然后再说Spark的hello world。
这里启动的错误是:
no module named zlib
- 安装zlib
说明python 缺少了zlib包,所以这里我就去查了很多资料,最后的解决办法如下:
在官网上 http://www.zlib.net/ 下载了zlib-1.2.8.tar.gz包。
然后将这个包上传到ubuntu的/apphome 目录,并执行如下命令解压缩:
tar -xvf zlib-1.2.8.tar.gz
压缩完毕后,/apphome目录会多出zlib的目录,cd 进入到这个目录,依次执行如下命令:
./configure
make
make install
执行结束后zlib 安装完成。
重新编译python
将上一篇文章的内容重新执行一遍即可。Spark 安装
下载spark,进入到http://spark.apache.org/downloads.html ,注意下图中的选项。下载完以后,将包上传到ubuntu 的/apphome 目录。
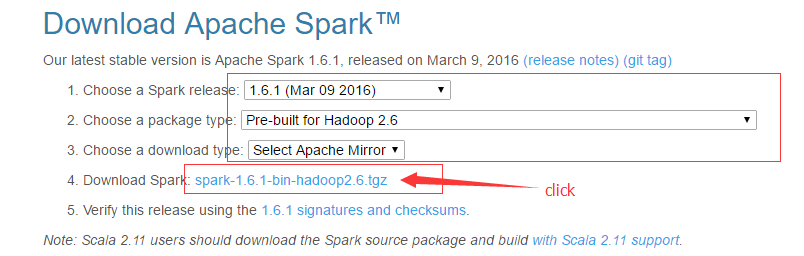
解压缩spark,在shell 中执行如下命令来解压缩:
tar -xvf spark-1.6.1-bin-hadoop2.6.tgz
执行完以后,/apphome目录中多了一个/apphome/spark-1.6.1-bin-hadoop2.6 目录。shell中执行cd 命令进入该目录。
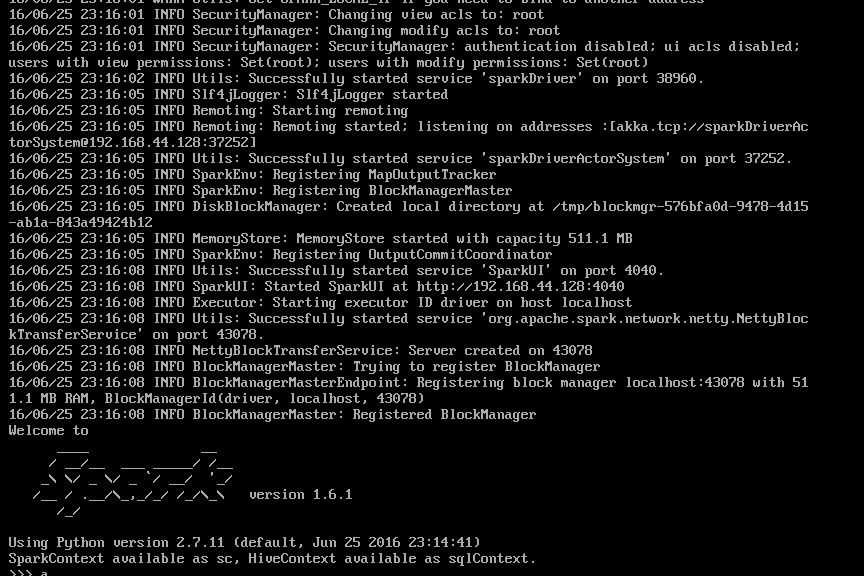
最重要的一步来了:
执行bin/pyspark 命令,待一阵刷屏过后,Spark 启动成功了,截图为证:















 6995
6995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









