







High discriminative SIFT feature and feature pair selection to improve the bag of visual words model学习
上星期学习了Lifeng Liu的这篇论文,笔记如下
1.视觉单词和短语的选择方法
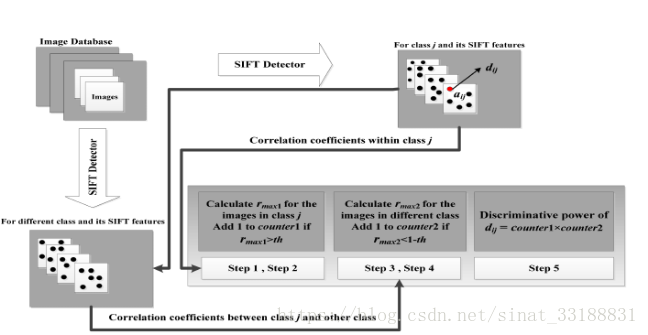
1.计算sift描述子dij和与它在相同类中的每个其他描述子的相关系数。rmax1表示最高的相关系数。将th设为预定义阈值。这里th被设定为0.5.如果rmax1>th,将计数器1加1
2.重复步骤1,直到第j类中剩余图片的rmax1都被取得。
3.计算sift描述子dij和与它在不同类中的每个其他描述子的相关系数。Rmax2表示最高的相关系数。如果rmax2<1-th,将计数器2加1.
4. 重复步骤3,直到不同类中剩余图片的rmax1都被取得。计数器2之后被标准化为单位长度。
5. dij的辨别力被表示为计数器1和2的乘积。
我们可以通过检查类内和类间相关系数的相应值来确定给定SIFT特征是否具有高判别力。类内相关系数越大,类间相关系数越小,计数器1和计数器2的乘积越大。具有较大计数器乘积对应的sift关键点能被看做是一个高辨别度的关键点。在提取所有具有高判别能力的SIFT特征后,我们从这些SIFT特征中进行k均值聚类,形成高判别性的视觉词汇。
2.改进bow算法
训练:
1.根据第二部分在所有图片的sift特征点中选择前60%作为高判别性的sift关键点,并将它们聚类成视觉词典。
2. 根据第3节提取高判别性SIFT关键点对。将这些SIFT关键点对进行聚类以形成视觉短语词典。
3. 生成联合直方图(如图7所示),将每个训练图像的视觉词汇和短语的直方图与权重因子α和1-α连接起来。
测试:
1. 从测试图像中提取SIFT关键点并生成相应的MST。根据第3节的描述从MST中选择SIFT关键点对。根据训练阶段获得的视觉词典和视觉词典词典生成关节直方图。
2. 通过SVM训练获得分类结果
视觉词汇和视觉词组的直方图乘以权重参数α和1-α的原因主要是由于视觉词汇和视觉词组的直方图在图像分类中起着不同的作用。
参考文献:High discriminative SIFT feature and feature pair selection to improve the bag of visual words model
Lifeng Liu; Yan Ma; Xiangfen Zhang,;Yuping Zhang; Shunbao Li;

















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









