






 本文介绍了如何使用Python的Pandas和Pathlib库高效处理大量Excel文件。通过os库遍历文件夹,读取每个文件中的数据,计算起始日期、终止日期、平均转化率和平均客单价,最后汇总生成数据分析报告。Pathlib提供了更简洁的文件路径操作方式,简化了文件遍历过程,大大提高了数据处理效率。
本文介绍了如何使用Python的Pandas和Pathlib库高效处理大量Excel文件。通过os库遍历文件夹,读取每个文件中的数据,计算起始日期、终止日期、平均转化率和平均客单价,最后汇总生成数据分析报告。Pathlib提供了更简洁的文件路径操作方式,简化了文件遍历过程,大大提高了数据处理效率。

在数据分析的日常工作中,我们可能会经常需要处理这样的问题:将一个或多个文件夹下的文件中的数据进行分析、处理、整合。这些文件通常是相似的或是同类别的,比如我们有多个月份的销售信息,每个月份的数据分别存在一个excel文档中;多个类别的销售信息,每个类的数据分别存在一个excel文档中等等。像是如图中所示:

在当前文件夹中存在“files”文件夹,里面是我们将要分析的数据,在该文件夹目录下又有如下四个文件夹,我们可以看作是四个大类的数据:
这四个文件夹当中就分别存放着所对应的数据,随便打开其中一个文件夹,数据文件如图所示:

其中每个文件的内容大致是相同:
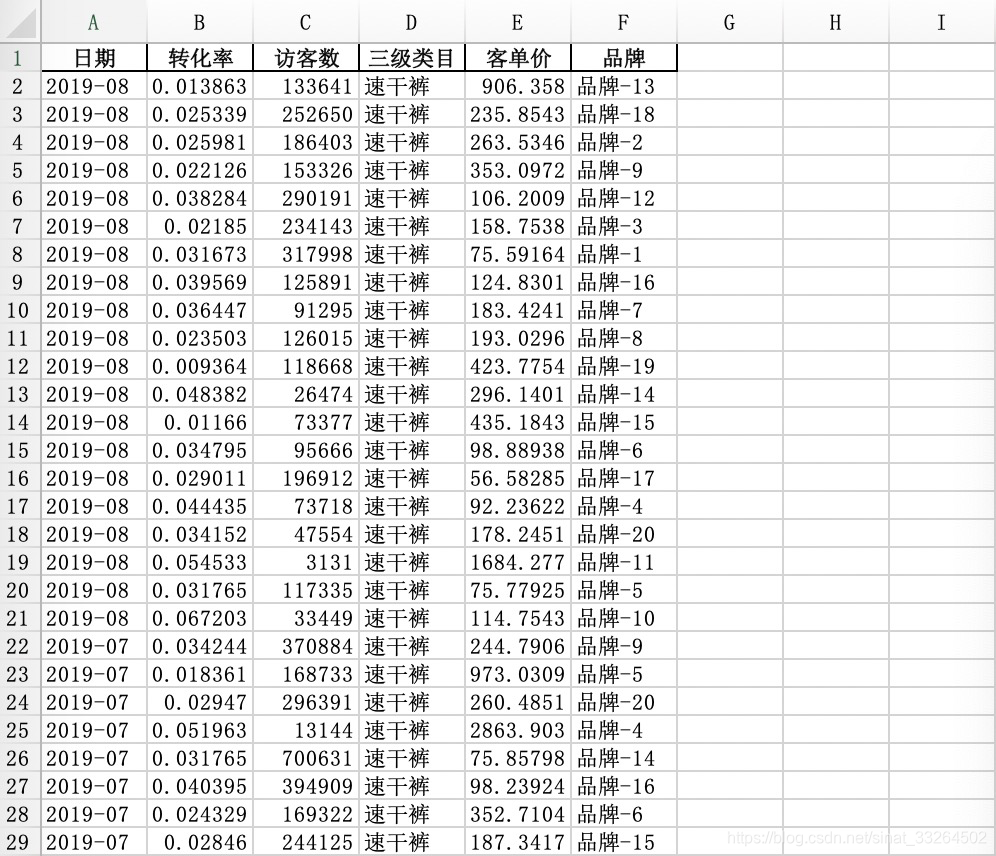
所有文件共有128个,每个文件中条目数在几百行,我们需要分别对这些文件中的数据进行分析,求出每个文件中所属类目的起始日期、终止日期、平均转化率、平均客单价,然后汇总到一起输出一份数据分析报告。如果用excel来一个个处理的话需要处理128次,想想就觉得费力啊!那么这个时候用上我们的pandas就再合适不过了。这个时候有些朋友会有些疑惑,我们该如何遍历这些文件并读取数据呢?本文就通过os库以及pathlib库为大家讲解,并在最后重点介绍一下pathlib。
首先导入我们需要使用到的库:
import pandas as pd
import numpy as np
import os
from pathlib import Path
import time设置自己存放文件的根目录:
file_path = "/Users/***/jupyter_notebook/Python_file_processing/files"先用os的方法,这里我们使用os.walk()来遍历文件名:

可以看到每次遍历都包含当前文件夹的根路径、该文件夹下的文件夹、该文件夹下的所有文件列表。通过代码我们可以轻松地将所有文件名整理到一个列表中:
# 存放所有文件名
file_list = []
# 存放每个子文件夹下所对应的文件名
file_dict = {}
for iroot, idirs, ifiles in os.walk(file_path):
if not idirs:
ifiles.remove('.DS_Store')
file_list.extend(ifiles)
file_dict[iroot] = ifiles
因为pandas读取文件需要绝对路径,所以我们建立一个根路径与文件名对应的字典,之后拼凑成绝对路径。file_dict如下图所示:
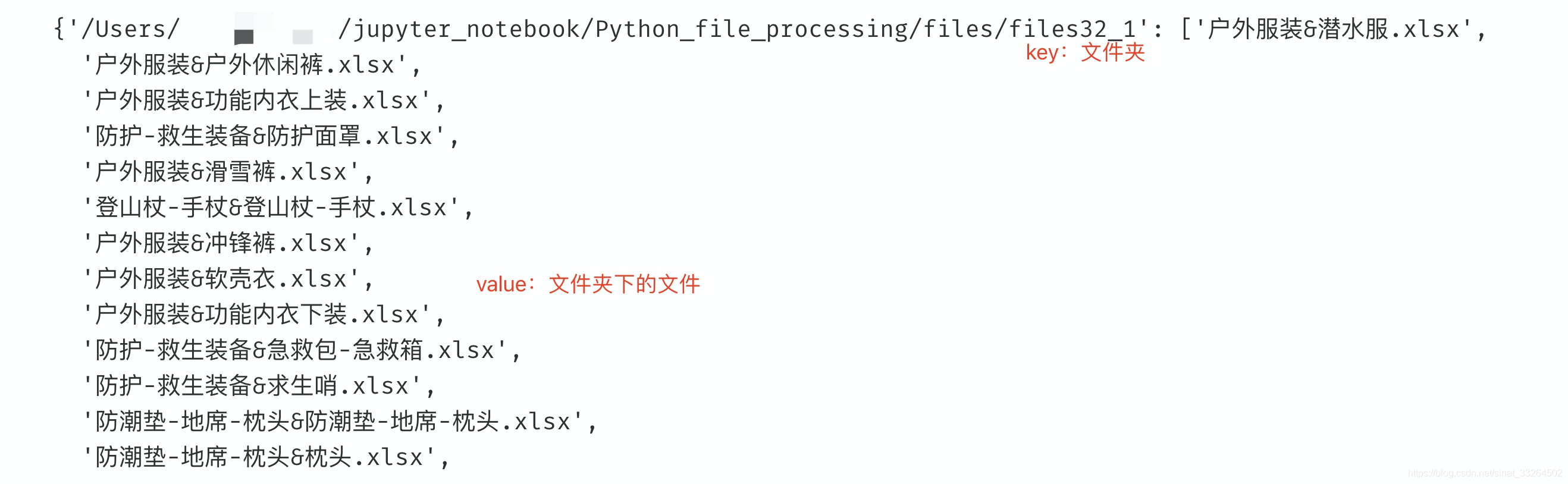
这样我们就可以通过dict.items()来拼接文件的绝对路径了,然后遍历读取文件,分析我们所需要的指标:
start_time = []
end_time = []
conversion_mean = []
category = []
unit_price_mean = []
start = time.time()
# 遍历所有文件,拼接路径
for k, v in file_dict.items():
for i in v:
file_name = os.path.join(k, i)
file = pd.read_excel(file_name)
start_time.append(file['日期'].min())
end_time.append(file['日期'].max())
conversion_mean.append(file['转化率'].mean())
category.append(file['三级类目'].unique()[0])
# 文件中有inf值
unit_price_mean.append(file['客单价'].replace(np.inf, np.nan).dropna().mean())
output_file = pd.DataFrame({'起始日期': start_time,
'终止日期': end_time,
'平均转换率': conversion_mean,
'所属类目': category,
'平均客单价': unit_price_mean})
cost = round(time.time() - start, 2)
print(f'处理数据共用时{cost}秒')最后输出分析报告,共128个条目:
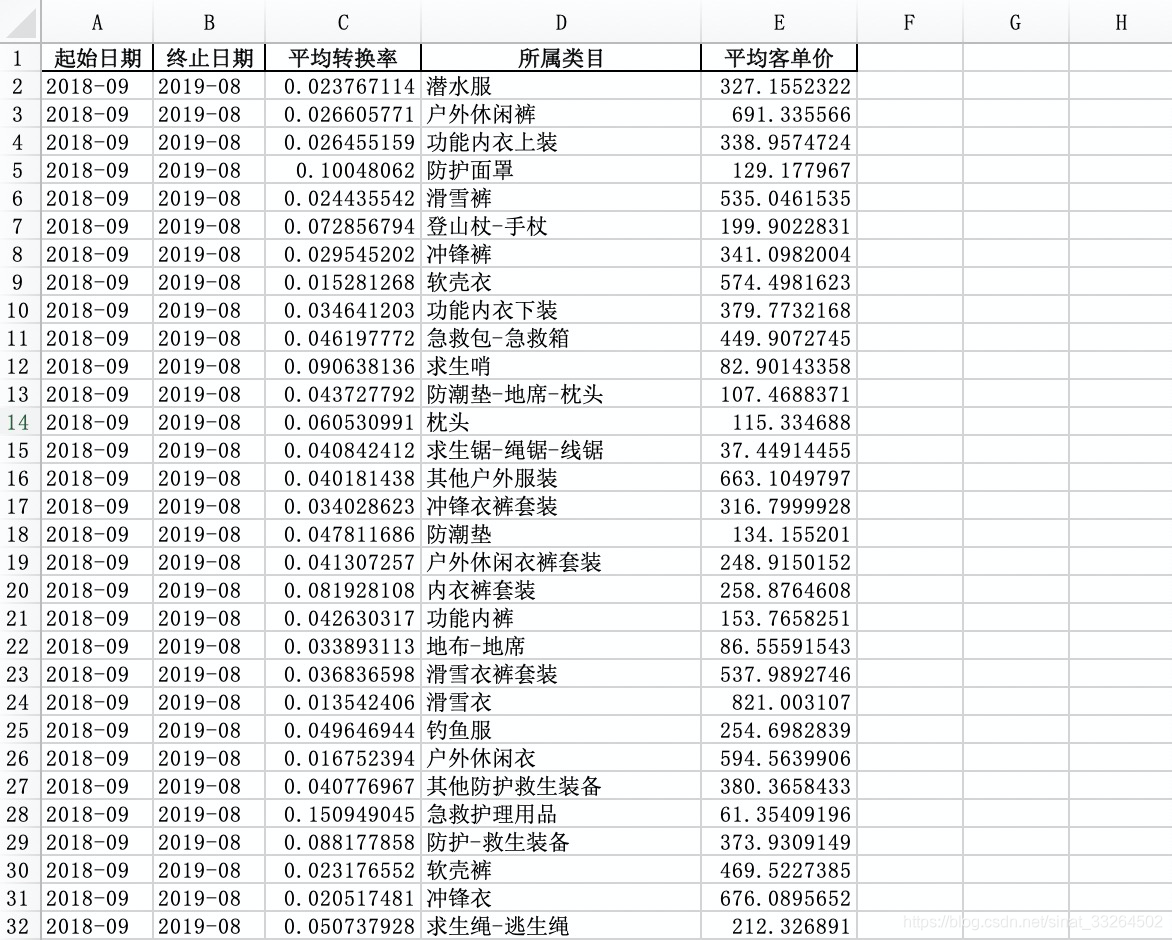
接下来我们用pathlib来遍历文件,可能比os要方便一些。
首先设置文件目录:
p = Path(file_path)让我们看一下通过pathlib的方法是如何遍历的:
# 所有以xlsx结尾的文件
for file in p.rglob('*.xlsx'):
print(file)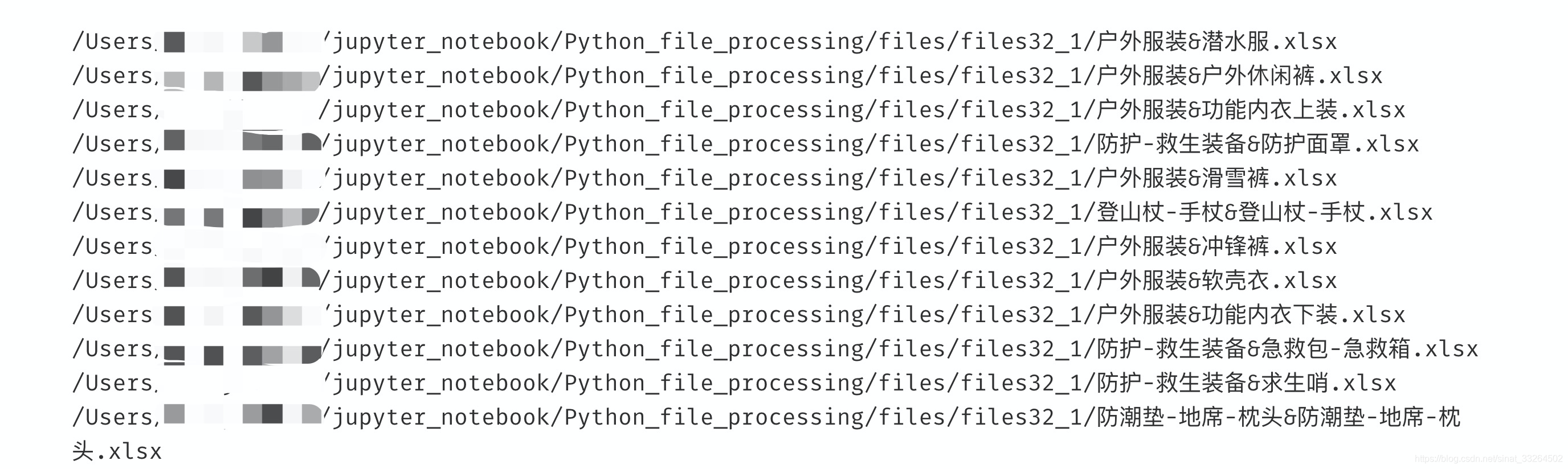
可以看到,通过pathlib.Path.rglob()方法可以直接遍历汇总所有文件的绝对路径,直接用pandas读取即可:
start_time = []
end_time = []
conversion_mean = []
category = []
unit_price_mean = []
start = time.time()
# 直接遍历出文件绝对路径
for file_name in p.rglob('*.xlsx'):
file = pd.read_excel(file_name)
start_time.append(file['日期'].min())
end_time.append(file['日期'].max())
conversion_mean.append(file['转化率'].mean())
category.append(file['三级类目'].unique()[0])
unit_price_mean.append(file['客单价'].replace(np.inf, np.nan).dropna().mean())
output_file1 = pd.DataFrame({'起始日期': start_time,
'终止日期': end_time,
'平均转换率': conversion_mean,
'所属类目': category,
'平均客单价': unit_price_mean})
cost = round(time.time() - start, 2)
print(f'处理数据共用时{cost}秒')![]()
这样,通过pandas的方法我们一下子就处理完了所有数据,只用时2秒,和手动用excel一个个处理相比太方便了,而pathlib库的使用更加方便了我们代码的编写。
Pathlib简介:
得到当前目录:
p = Path.cwd()![]()
拼接路径,得到想要的文件的绝对路径:
p_new = p.joinpath('files', 'files32_1', '户外服装&潜水服.xlsx')
得到路径文件:
p_new.name![]()
得到路径文件的名称:
p_new.stem![]()
得到路径文件的后缀:
p_new.suffix![]()
得到路径文件的上一级目录:
p_new.parent![]()
得到路径的每一级:
p_new.parts
判断路径文件是否存在:
p_new.exists()![]()
判断路径文件是否为文件夹:
p_new.is_dir()![]()
判断路径文件是否为文件:
p_new.is_file()![]()
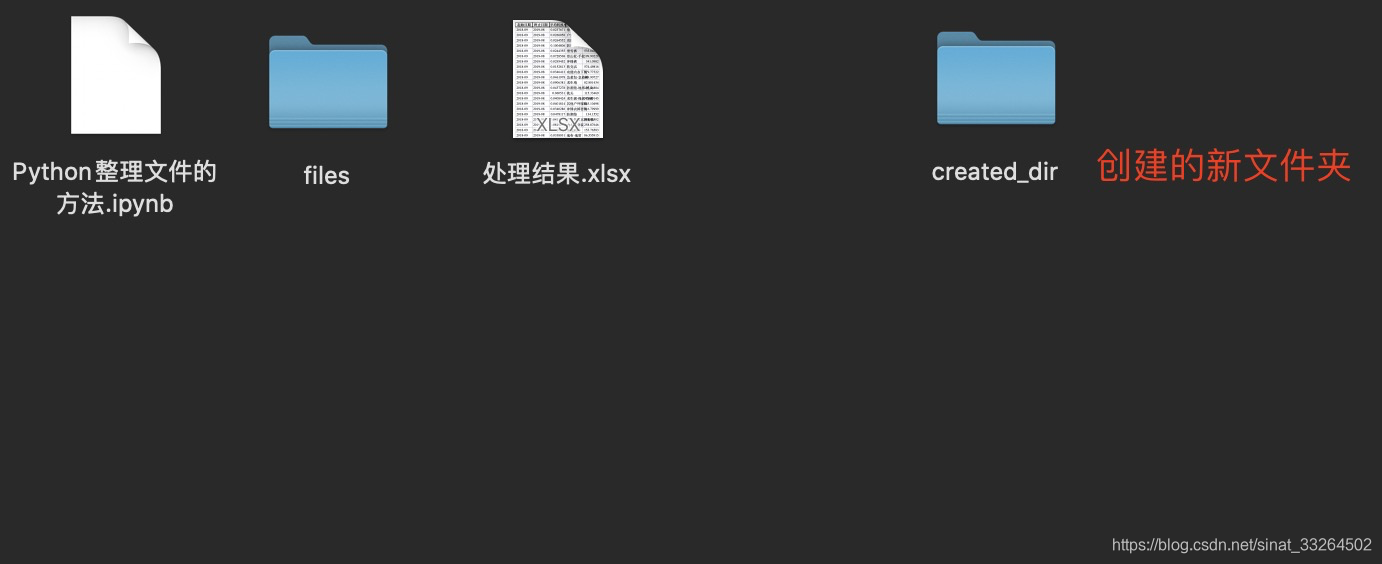
创建新文件夹:
p_dir = Path(Path.cwd().joinpath('created_dir'))
# parents参数:
# True--若p_dir不存在则递归创建文件夹
# False--若p_dir不存在则报错
p_dir.mkdir(exist_ok=True, parents=True)创建文件夹之前:
创建文件夹之后:
修改路径文件的文件后缀(with_shuffix修改后缀,with_name修改文件名):
# 将原来的xlsx换为txt
p_new.replace(p_new.with_suffix('.txt'))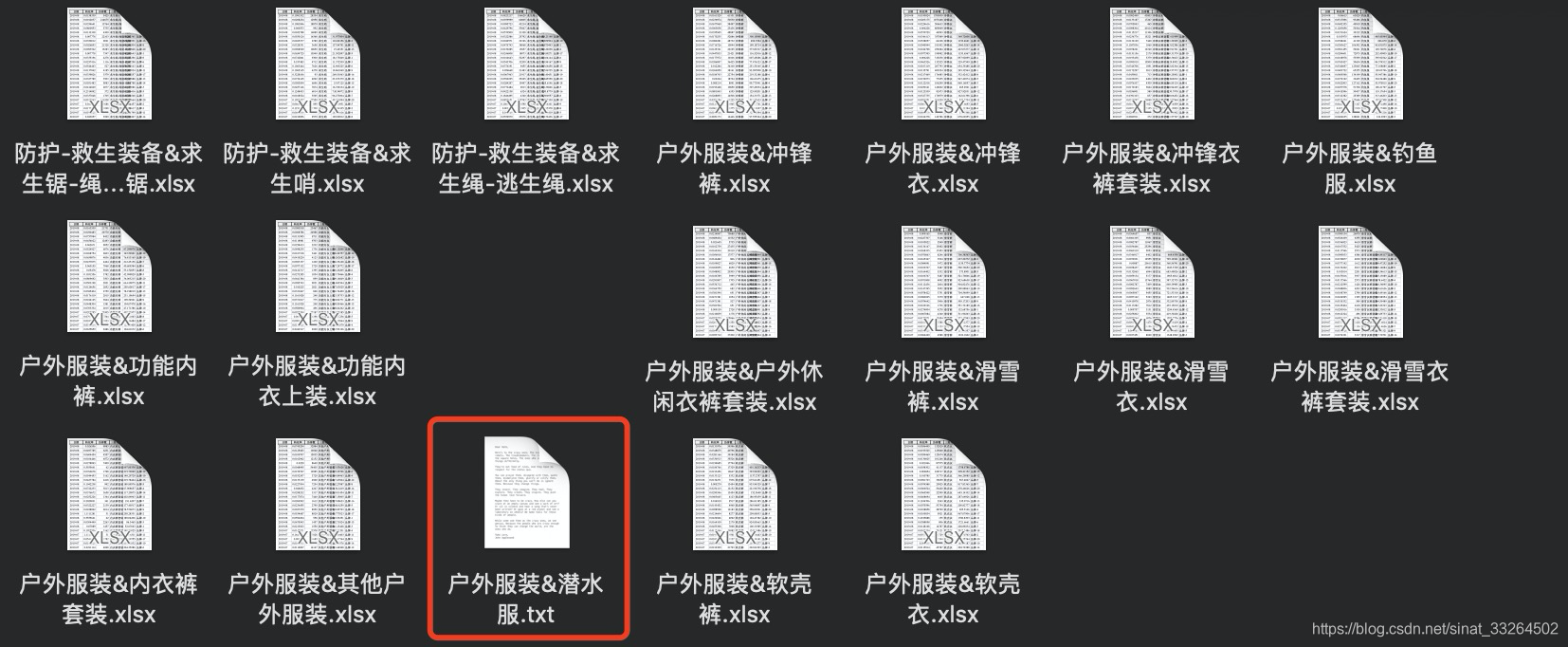
删除路径文件:
p_new.unlink()
感谢观看!

















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









