









步骤一:安装JDK1.8
1.卸载centos系统自带的openjdk,此步的目的是避免JDK冲突,openjdk的路径为(/usr/lib/jvm)
1.1 查看openjdk版本
#查看系统自带的openjdk版本
# java -version
openjdk version "1.8.0_232"
OpenJDK Runtime Environment (build 1.8.0_232-b09)
OpenJDK 64-Bit Server VM (build 25.232-b09, mixed mode)
1.2 查询所在安装位置
#rpm为包管理器(Red Hat Linux)
rpm -qa | grep java
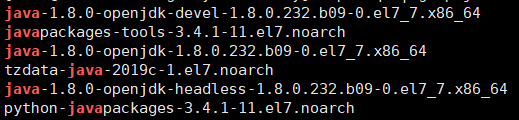
1.3 删除全部(noarch文件可以不动)
rpm -e --nodeps java-1.8.0-openjdk-devel-1.8.0.232.b09-0.el7_7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64
rpm -e --nodeps java-1.8.0-openjdk-1.8.0.232.b09-0.el7_7.x86_64
#执行上述三条命令后,输入
java -version
#-bash: /usr/bin/java: No such file or directory
1.4 安装JDK1.8(我的是用本地下载jdk然后用Xftp传服务器上的)
JDK官网下载地址
下载jdk-8u231-linux-x64.tar.gz(1.8版本)
#解压
tar -zxvf jdk-8u231-linux-x64.tar.gz
#转移目录位置
mv jdk1.8.0_231/ /home/zzy/jdk1.8
1.5 配置环境变量
#编辑
vi /etc/profile
export JAVA_HOME=/home/zzy/jdk1.8
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=${JAVA_HOME}/bin:$PATH```
#使配置生效
source /etc/profile
1.6 验证是否成功:

步骤二:安装Hadoop2.5
1.先把安装包传到服务器(hadoop-2.5.2.tar.gz)
Apache官网下载地址
tar -zxvf hadoop-2.5.2.tar.gz
mv hadoop-2.5.2 /home/zzy/hadoop2.5
2.安装并配置环境变量
vi /etc/profile
#输入以下内容
export HADOOP_HOME=/home/zzy/hadoop2.5
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
3.验证是否成功安装(下图为成功安装显示内容)
hadoop version

步骤三:
Hadoop的各个组件均可利用XML文件进行配置,core-site.xml用于配置通用属性,hdfs-site.xml文件用于配置HDFS属性,mapred-site.xml文件则用于配置MapReduce属性,yarn-site.xml文件用于配置YARN属性。以上文件存放在/etc/hadoop子目录下。
| 运行模式 | 特点 |
|---|---|
| 独立(本地)模式 | 无需任何守护进程,所有程序都在同一个JVM上执行。在该模式下测试和调试MapReduce程序很方便,比较适合开发阶段 |
| 伪分布模式 | Hadoop守护进程运行在本地机器上,模拟一个小规模的集群 |
| 全分布模式 | Hadoop守护进程运行在一个集群上 |
1.更改配置文件
1.1 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
<configuration>
1.2 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<configuration>
1.3 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<configuration>
1.4 yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<configuration>
2.配置SSH
在伪分布模式下必须启动守护进程,而启动守护进程的前提是使用需要提供的脚本成功安装SSH。
2.1 首先确保SSH已经安装,且服务器正在运行。
#例如Ubuntu
# sudo apt-get install ssh
2.2 基于新口令生成一个新的SSH密钥,以实现无密码登录。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
2.3 测试与localhost是否能连接(成功)
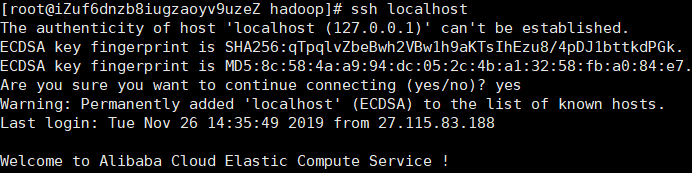
3 在首次使用hadoop前,必须格式化文件系统。
hdfs namenode -format

4.启动和终止守护进程
#.sh文件在/hadoop2.5/sbin目录下
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
注:可能会遭遇以下问题(JAVA_HOME is not set and couldn’t be found)
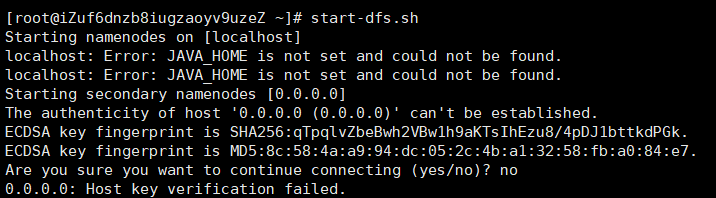
解决办法:
编辑/home/zzy/hadoop2.5/etc/hadoop/hadoop-env.sh,依照自己的JDK路径更改。
vi /home/zzy/hadoop2.5/etc/hadoop/hadoop-env.sh
#export JAVA_HOME=${JAVA_HOME}改成export JAVA_HOME=/home/zzy/jdk1.8
5.启动情况



6.关闭进程
mr-jobhistory-daemon.sh stop historyserver
stop-yarn.sh
stop-dfs.sh















 4067
4067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









