







最近用kafka用的比较多,因此对生产消费模型有了不小的兴趣,就想着,如果在没有搭建kafka的情况下,该怎么实现生产消费模型呢?
前菜
进程:是系统进行资源分配的最小单位,它是程序执行时的一个实例。程序运行时系统就会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列,进程调度器选中它的时候就会为它分配CPU时间,程序开始真正运行。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。
线程:是程序执行时的最小单位,它是进程的一个执行流,是CPU调度和分派的基本单位,一个进程至少包含一个主线程,也可以由很多个线程组成,线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。
协程:又称为微线程,是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。在python中用户调度的方式一开始是通过yield关键字来实现的,后面有了asyncio模块来专门支持协程。
三者之间的关系:
进程包含线程,线程包含协程。
干货
下面废话不多说,直接放代码
假定应用场景:老周包子铺,有张三, 李四, 王五三位包子师傅,现在有小红, 小黄两个人来吃包子,老周包子铺的案板上最多只能容纳15个包子,等案板上有15个包子的时候,包子师傅就先不做包子了。
多线程版
思路简介:设置2个线程池,生产者线程池有3个线程,消费者线程池有2个线程,由于线程是共享进程中的所有资源,因此,可以用一个全局变量队列来存储消息。
import threading
import time, queue
import os
from concurrent.futures import ThreadPoolExecutor
q = queue.Queue(maxsize=15) # 声明队列
event = threading.Event()
def Producer(name):
count = 1
print("生产者{}线程号为:{},进程号为{}".format(name,threading.get_ident(),os.getpid()))
while True:
if q.qsize() == 0:
baozi = '%s生产的第%s包子' % (name, count)
print(baozi)
q.put(baozi)
count += 1
time.sleep(1)
def Consumer(name):
print("消费者{}线程号为:{},进程号为{}".format(name,threading.get_ident(),os.getpid()))
while True:
i = q.get()
print("%s吃了%s" % (name, i))
print("现在还有%d个包子" % q.qsize())
time.sleep(1)
def run():
"""
:return:
"""
# 3个大厨
producer_pool = ThreadPoolExecutor(max_workers=3)
producer_pool.map(Producer, ['张三', '李四', '王五'])
# 2个客人
consumer_pool = ThreadPoolExecutor(max_workers=2)
consumer_pool.map(Consumer, ['小红', '小黄'])
if __name__ == '__main__':
run()
多进程版
思路和多线程版差不多,但是进程之间的通信不像线程那么方便,所以用Manager()进行不同进程之间的通信。
from multiprocessing import Pool, Manager
import time
import os
import threading
def producer(producer_queue, name):
count = 1
print("生产者{}线程号为:{},进程号为{}".format(name, threading.get_ident(), os.getpid()))
while True:
if producer_queue.qsize() == 0:
baozi = '%s生产的第%s包子' % (name, count)
print(baozi)
producer_queue.put(baozi)
count += 1
time.sleep(1)
def consumer(consumer_queue, name):
print("消费者{}线程号为:{},进程号为{}".format(name, threading.get_ident(), os.getpid()))
while True:
i = consumer_queue.get()
print('%s吃了%s' % (name, i))
print('现在还有%d个包子' % consumer_queue.qsize())
time.sleep(1)
def run():
# 该语句不能随意移动,否则会报错:freeze_support()
deal_message = Manager().Queue(maxsize=15)
producer_pool = Pool(processes=3)
consumer_pool = Pool(processes=2)
producer_list = ['张三', '李四', '王五']
consumer_list = ['小红', '小黄']
for _ in producer_list:
producer_pool.apply_async(producer, args=(deal_message, _))
for _ in consumer_list:
consumer_pool.apply_async(consumer, args=(deal_message, _))
producer_pool.close()
consumer_pool.close()
producer_pool.join()
consumer_pool.join()
if __name__ == '__main__':
run()
协程yield版
和之前两版不一样,由于协程是用户自己控制的状态切换,因此在本例当中,写了一个简化的模拟,其实只有2个协程,一个协程充当生产者的角色,一个协程充当消费者的角色,又因为是自主切换,所以包子案板数量永远不会超过1个。
import random
import time
import threading
import os
total_count = 0
def consumer():
consumer_list = ['小红', '小黄']
global total_count
status = True
while True:
baozi = yield status
name = random.choice(list(consumer_list))
print("消费者{}线程号为:{},进程号为{}".format(name, threading.get_ident(), os.getpid()))
print('%s吃了%s' % (name, baozi))
total_count -= 1
print('现在还有%d个包子' % total_count)
if total_count >= 15:
status = False
time.sleep(1)
def producer(consumer):
global total_count
c.send(None)
producer_dict = {"张三": 0, "李四": 0, "王五": 0}
while True:
producer_name = random.choice(list(producer_dict.keys()))
print("生产者{}线程号为:{},进程号为{}".format(producer_name, threading.get_ident(), os.getpid()))
baozi = '%s生产的第%s包子' % (producer_name, producer_dict[producer_name] + 1)
print(baozi)
producer_dict[producer_name] = producer_dict[producer_name] + 1
total_count += 1
print('现在一共有个{}包子'.format(total_count))
time.sleep(1)
yield consumer.send(baozi)
if __name__ == '__main__':
c = consumer()
p = producer(c)
for status in p:
if status == False:
print('包子案板满了,暂停生产')
time.sleep(1)
协程asyncio版
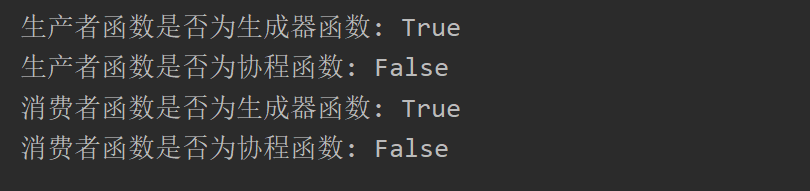
上面的协程使用的yield字段来控制,但是对基于生成器的协程的支持已弃用并计划在 Python 3.10 中移除,我们使用inspect模块来查看函数,其实是一个生成器:
import inspect
print('生产者函数是否为生成器函数:', inspect.isgeneratorfunction(producer))
print('生产者函数是否为协程函数:', inspect.iscoroutinefunction(producer))
print('消费者函数是否为生成器函数:', inspect.isgeneratorfunction(consumer))
print('消费者函数是否为协程函数:', inspect.iscoroutinefunction(consumer))
因此,用asyncio再实现了遍,代码形式和之前的线程版和进程版就很相似了,而且生产消费函数都是协程函数。
import asyncio
import threading, os
async def producer(name, queue):
print("生产者{}线程号为:{},进程号为{}".format(name, threading.get_ident(), os.getpid()))
count = 0
while True:
count += 1
baozi = '%s生产的第%s包子' % (name, count)
print(baozi.replace('的', '了'))
await queue.put(baozi)
await asyncio.sleep(1)
async def consumer(name, queue):
print("消费者{}线程号为:{},进程号为{}".format(name, threading.get_ident(), os.getpid()))
while True:
baozi = await queue.get()
print('%s吃了%s' % (name, baozi))
print('现在还有%d个包子' % queue.qsize())
await asyncio.sleep(1)
async def main():
queue = asyncio.Queue(maxsize=15)
await asyncio.gather(
producer("张三", queue),
producer("李四", queue),
producer("王五", queue),
consumer("小红", queue),
consumer("小黄", queue),
)
if __name__ == '__main__':
asyncio.run(main())
参考资料:














 5260
5260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









