







主要涉及python对excel的操作
顺手帮朋友处理毕业数据写的小脚本,她的问题如下:
样本前后顺序是固定的。id是升序排列之后的, time_dif表示时间差。想生成新变量count=所在的组里样本的数量。分组的依据为id 和 time_dif,分组规则为在同一id内,从第一个样本开始数,一直到下一个time_dif>5之前的样本分为一组。分组如图所示:
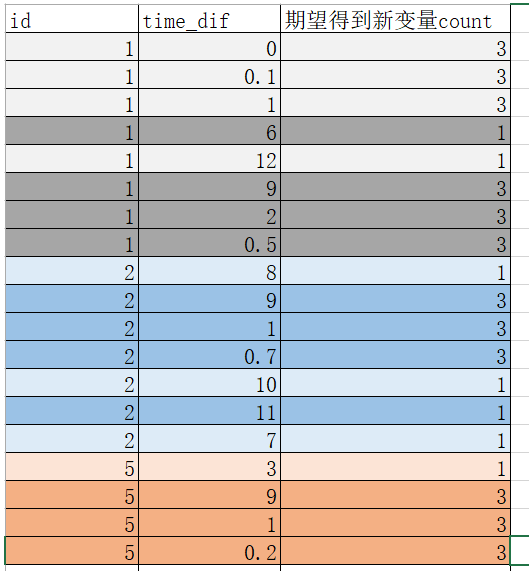
朋友给的数据集里开始已经经过了一些预处理,如下:

处理思路的话比较简单,相当于在一列数组里,如果下一个数较之上一个数小,那么这个数的值便是这一段小数列的count值,用两个for循环既可以遍历出结果,代码如下:
#在这里我们使用xlrd,xlsxwriter两个包对xlsx进行处理,通过pip或者anaconda进行安装即可
import xlrd
import xlsxwriter
ExcelFile=xlrd.open_workbook(r'C:\Users\Administrator\Desktop\dataexample-excel.xlsx') #打开目标处理xlsx
sheet=ExcelFile.sheet_by_index(0) #定位到索引为0的工作表,即第一个工作表
cols=sheet.col_values(7) #取第8列的数据
del cols[0]
newcols = []
groupNum = 1
num = 0
try:
for i in cols:
if (cols[num+1]>i):
groupNum=groupNum+1
num = num+1
else:
for i in range(0,groupNum) :
newcols.append(groupNum)
groupNum = 1;
num = num + 1
#遍历到最后一个数的时候会发生索引溢出,所以catch一下,不影响后续操作
except IndexError:
print newcols
#在写入数据的时候,我本来是打算用xlwt的,但是由于处理的数据量较大,因此用xlwt会发生错误ValueError:row index (65536)not an intin range(65536),在查阅资料后选择了xlsxwriter进行写入,最大能够支持1048576行数据,16384列数据。
workbook = xlsxwriter.Workbook('result.xlsx') #生成表格
worksheet = workbook.add_worksheet(u'sheet1') #在文件中创建一个名为TEST的sheet,不加名字默认为sheet1
worksheet.set_column('A:A',20) #设置第一列宽度为20像素
bold=workbook.add_format({'bold':True}) #设置一个加粗的格式对象
for i in range(len(newcols)):
worksheet.write('A%s'%str(i+1),newcols[i]) #循环写处理后的数据生成的列表
workbook.close()
参考文献:
【1】http://blog.csdn.net/dongyouyuan/article/details/52681617
【2】https://www.cnblogs.com/jessicaxu/p/7847046.html















 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









