









本来打算写一个可以查找任何关键字的图片抓取,但是我发现有一些问题,可能是我网速问题,也可能是代码的问题,代码如下
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import urllib.request
print("请输入你的500px账号")
username="***********"
print("请输入你的500px账号的密码")
password="*************"
driver=webdriver.Chrome()
driver.get("https://500px.com/home")
driver.find_element_by_class_name("static_nav__login").click()
time.sleep(3)
driver.find_element_by_name("email").send_keys(username)
driver.find_element_by_name("password").send_keys(password)
driver.find_element_by_name("password").send_keys(Keys.ENTER)
time.sleep(15)
driver.find_element_by_class_name("query").send_keys("**********")#这里是你填入需要搜索的照片主题
driver.find_element_by_class_name("query").send_keys(Keys.ENTER)
time.sleep(20)
path=r"C:\Users\Administrator\Desktop\Hupu\\" #文件夹随便写的,可自己修改
x = 1
links=driver.find_elements_by_class_name("photo_activity_item__img")
urls=[]
for item in links:
url=item.get_attribute("src")
print(url)
urls.append(url)
for url in urls:
driver.get(url)
time.sleep(5)
src = driver.find_element_by_class_name("photo").get_attribute("src")
urllib.request.urlretrieve(src, path+'%s.jpg'%x)
print (u"正在保存第", x, u"张照片", u" 发现共有", len(links), u"张照片")
print(u"TabError发生在"+x+u"张照片")
x = x + 1
错误并不是一开始出现的,在抓取了几张或者十几张的时候就会有找不到的报错。因为搜索出来的图片直接获取url并不是最清晰的版本,所以我要先获取点击图片的连接,然后在打开这个链接,再获取清晰版本的图片的url,所以这就比较麻烦,需要页面不断地跳转。于是我发现如果直接获取following的图片就没那么麻烦了。可以看看接下来两张截屏就知道为什么了。
图片1
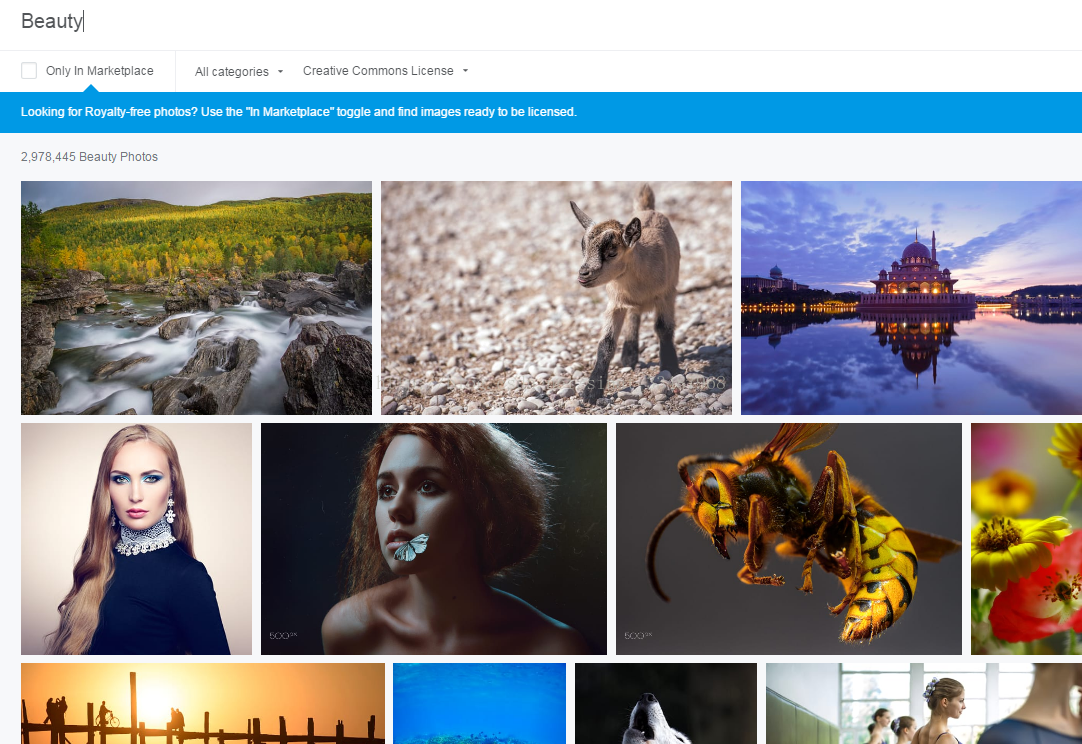
这是搜索的结果,明显每一张图不是最清晰的版本。
图片2
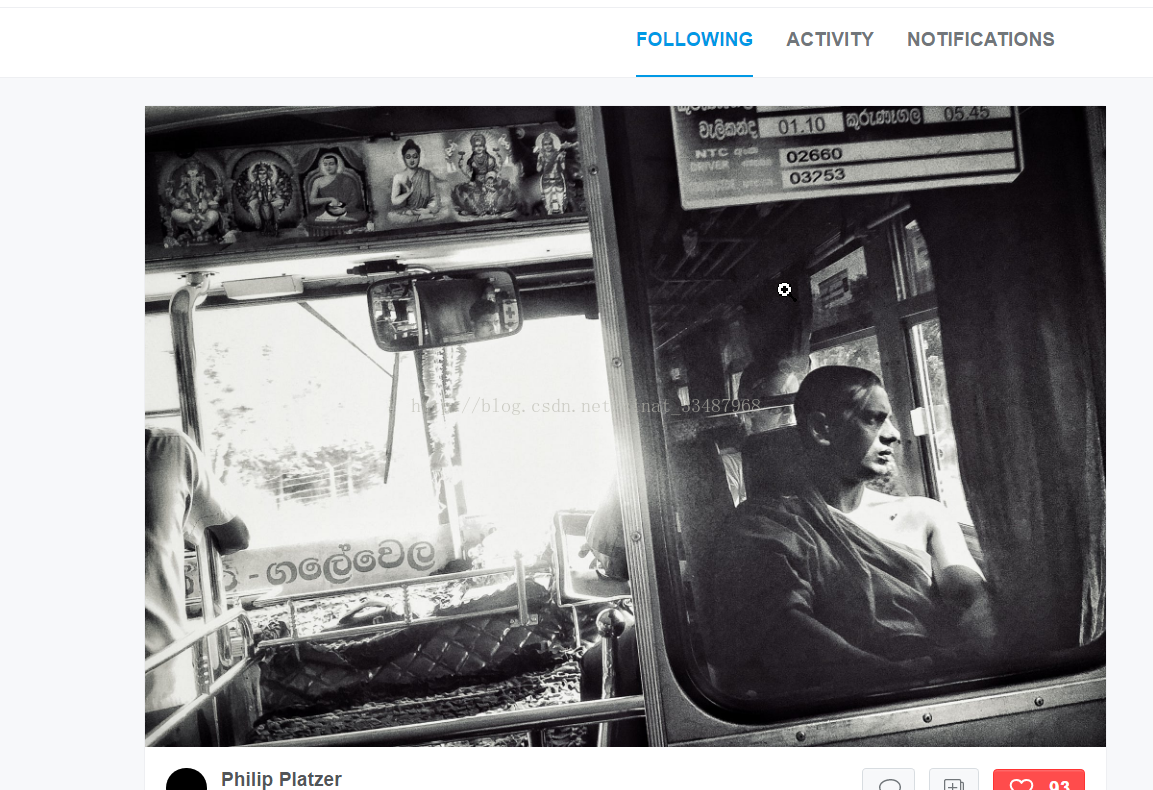
这是关注的图片,是最清晰的版本。
我下面再贴上抓取following 的图片的代码
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import urllib.request
print("请输入你的500px账号")
username="************"
print("请输入你的500px账号的密码")
password="**********"
driver=webdriver.Chrome()
driver.get("https://500px.com/home")
driver.find_element_by_class_name("static_nav__login").click()
time.sleep(3)
driver.find_element_by_name("email").send_keys(username)
driver.find_element_by_name("password").send_keys(password)
driver.find_element_by_name("password").send_keys(Keys.ENTER)
time.sleep(15)
driver.
path=r"C:\Users\Administrator\Desktop\Hupu\\"
x = 1
links=driver.find_elements_by_class_name("photo_activity_item__img")
print(links)
urls=[]
for item in links:
url=item.get_attribute("src")
print(url)
urls.append(url)
for url in urls:
urllib.request.urlretrieve(url, path+'%s.jpg'%x)
print (u"正在保存第", x, u"张照片", u" 发现共有", len(links), u"张照片")
x = x + 1
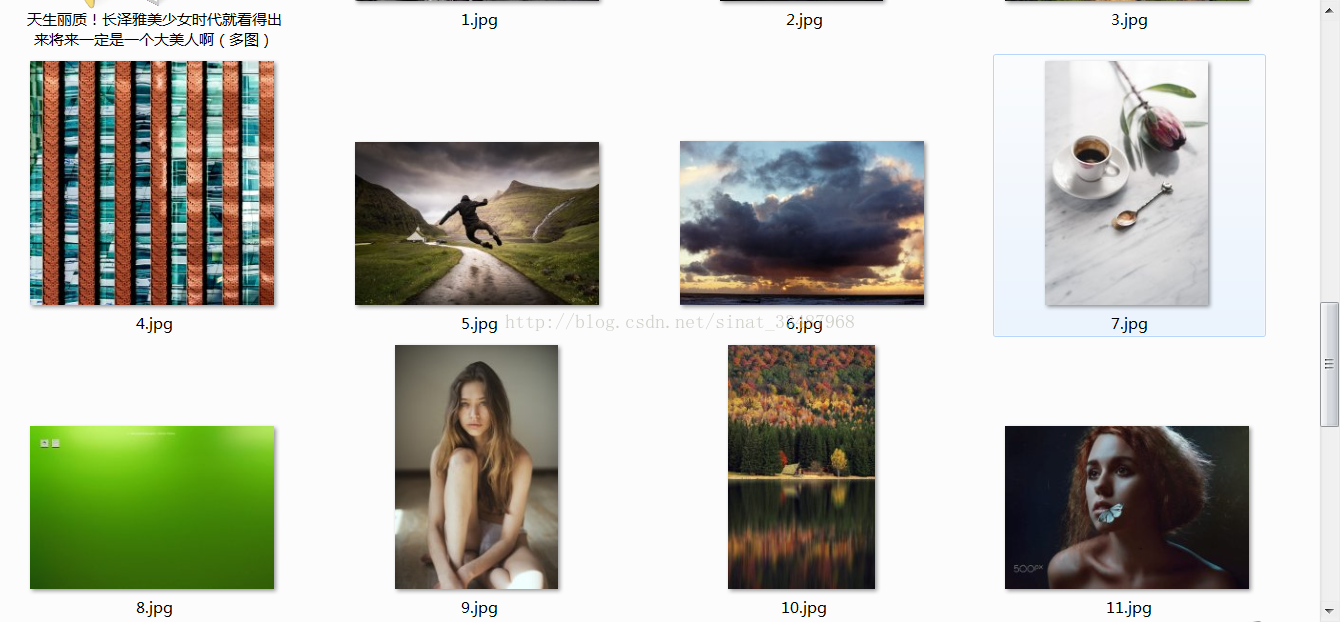
看看结果:
图片3
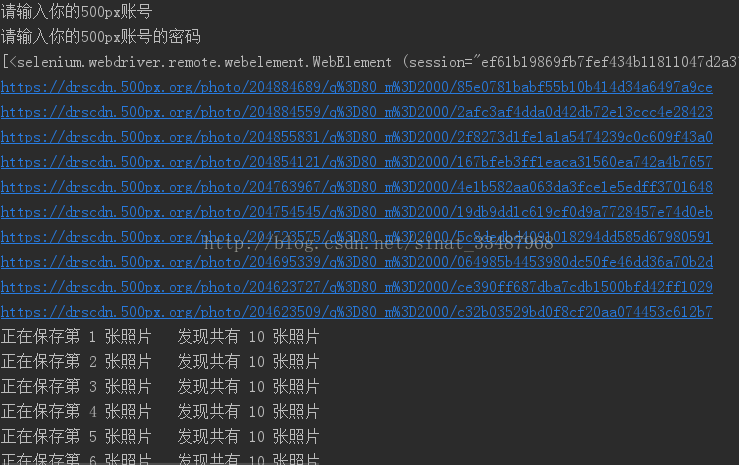
图片4
好吧我会改进一下的。目前还不完善。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









