







 本文深入探讨序列模型,特别是用于机器翻译的sequence2sequence模型。介绍了基础的encoder-decoder结构,强调了注意力机制的重要性,解释了贪心搜索与beam search的区别,并详细阐述了beam search的优化方法,包括长度归一化。此外,还提到了BLEU得分在机器翻译评估中的应用,以及注意力模型的直观理解。最后,简要讨论了语音识别和触发字检测的相关内容。
本文深入探讨序列模型,特别是用于机器翻译的sequence2sequence模型。介绍了基础的encoder-decoder结构,强调了注意力机制的重要性,解释了贪心搜索与beam search的区别,并详细阐述了beam search的优化方法,包括长度归一化。此外,还提到了BLEU得分在机器翻译评估中的应用,以及注意力模型的直观理解。最后,简要讨论了语音识别和触发字检测的相关内容。
这一课将学习sequence2sequence model,广泛地应用于机器翻译等领域
1.基础模型basic model
以翻译为例,将如下一句法文翻译成英文,输入是法文的每个单词,输出是英文的每个单词,分别用x<t>,y<t>表示:
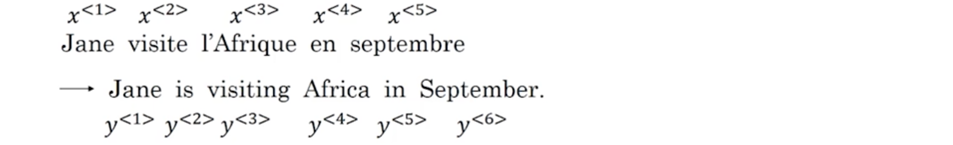
如何构建一个模型,使得输入法文序列的词,输出英文序列的词呢?接下去要介绍的知识与思想主要来自于这两篇论文:

(1)首先建立一个网络,称之为encoder network,是一个RNN结构。RNN结构中的单元可以是GRU,也可以是LSTM。每个时刻只向该网络输入一个法语单词;当接收完所有单词之后,这个人NN网络会输出一个向量来代表这个输入序列。
(2)接着建立一个网络,称之为decoder network。每个时刻输出一个英文单词,直到它输出句子的结尾标记,这个解码网络的工作就结束了。
以上两步如下图所示:

事实证明,当训练的样本足够多时,这个模型确实在翻译上有非常优秀的表现。
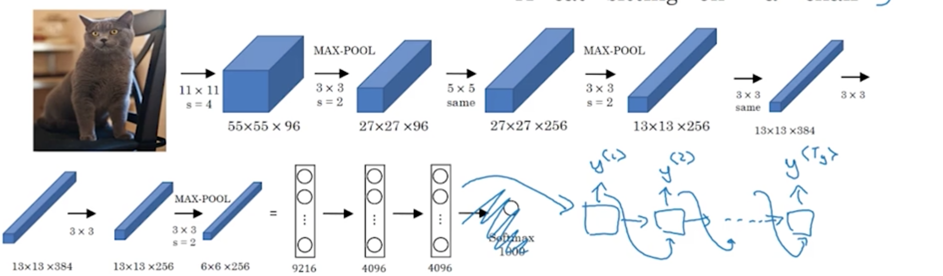
有一个与此类似的结构被用来做图像描述,即输入一张图片,输出一句对图像描述的句子。
首先将图片经过一个预训练的卷积神经网络(比如Alexnet),去掉最后一层的softmax层,将前一层的结果(4096维的向量)作为encoder network获取到的编码后的向量,输入给decoder network。与翻译模型一样,decoder network在每一个时刻输出一个词,所有词组合起来就是句对图像的描述的句子。比如输入的句子将会是:a cat sitting on a chair
结构如下:
2.选择最可能的句子
通过encoder-decoder的RNN,会将输入的法语句子翻译成英语句子,decoder输出单词的过程与语言模型生成序列一样,但是语言模型生成的序列是随机的,而机器翻译中生成的序列需要依据输入的语言,给出最好的翻译,是有条件的,因此称之为条件语言模型。
但是对同一句法语的翻译可能会有多个分布,机器翻译追求的是精准,因此并不是随机取样,而是要选出最好的最可能的翻译句子,即使得一下的条件概率最大化:

其中,x是输入的序列,y是输出的序列。
要选出最优的结果,你可能会想到“贪心搜索(greedy search)”,什么是贪心搜索呢?
首先会去选出最优的第一个词,在选出了第一个词的基础之上,再选出最优的第二个词,以此类推。但是贪心搜索在机器翻译中并不合适,我们要的是一词性输出整体最优的句子,使得整体的概率最大化。比如下面两个句子,显然第一个币第二个翻译得更好,因为第一个更简洁:
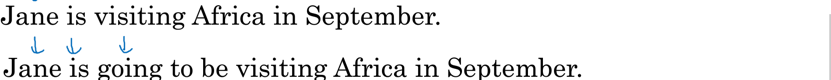
但是,若按照贪心算法,当选择好前两个词jane is 之后根据贪心算法,第三个词会是going最优,因此就会给出第二个句子,但是整个句子的条件概率并没有最大化。
贪心搜索的另一个缺点是计算量大,假设有10000个词,要生成10个词的句子,那么就是去计算10000的10次方。
因此可以使用一种近似的搜索算法,叫做beam search algrithm.下一节中介绍。
3.集束搜索beam search
直接进入主题。
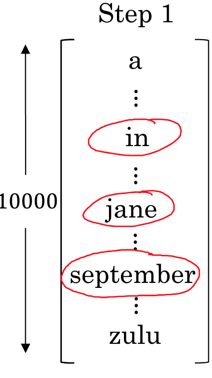
(1)第一步,选出第一个词。与上面的贪心搜索不同之处,首先在decoder端的第一个输出,是在所有词库中选择出概率最大的3个词做为起始词。即p(y<1>|x)最大。比如选出了如下B个词(B是认为设定的,比如3):
(2)第二步,针对每个起始词,都在decoder端的第二个时刻输出一个所有词库里的最优词,使该词与第一个词的联合条件概率最大,即p(y<1>,y<2>|x)最大,该概率可以如下计算得到:
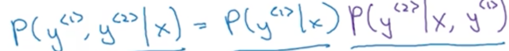
比如第一个词为”in”时第二最好的词是september;
第一个词为”jane”时第二最好的词是is;
第一个词为”september”时第二最好的词是XXX;
于是总共需要计算3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









