







awk基本语法
awk ‘script’ files
script 由下面的结构组成 /pattern/{actions}
parttern为条件,actions为动作,在awk语句中由“{}”包裹的为actions,其余的为parttern
parttern支持多种情况,下面来简单介绍一下1>正则表达式作为parttern
测试文件test.txtspider@spider:/tmp$ cat test.txt jim 5445 33 herny 81558 28 lilei 25478 55 hanmm 11444 54 yina 9364585 44 teddy 25552 18 allen 54251 70 andy 412 4 jay 88424 75
spider@spider:/tmp$ awk '/an+/{print $1,$2,$3}' test.txt hanmeimei 11444 54 andy 412 4spider@spider:/tmp$ awk '$1~/^a.+[ny]$/' test.txt allen 54251 70 andy 412 4
2>比较表达式做为 pattern
spider@spider:/tmp$ awk '$NF > 4' test.txt jim 5445 33 herny 81558 28 lilei 25478 55
3>常量表达式做为 pattern
spider@spider:/tmp$ awk 'a=1' test.txt jim 5445 33 herny 81558 28 lilei 25478 55 hanmeimei 11444 54 yina 9364585 44 teddy 25552 18 allen 54251 70 andy 412 4 jay 88424 75 spider@spider:/tmp$ awk 'a=0' test.txt spider@spider:/tmp$
4>空作为pattern
spider@spider:/tmp$ awk '{print $0}' test.txt jim 5445 33 herny 81558 28 lilei 25478 55 hanmeimei 11444 54 yina 9364585 44 teddy 25552 18 allen 54251 70 andy 412 4 jay 88424 755>特殊的 pattern: BEGIN, END
下面的语句是输出第三行与最后一行的文本spider@spider:/tmp$ awk 'BEGIN {N=3};NR==N {print $0};END{print $0}' test.txt lilei 25478 55 jay 88424 756>模式范围: begpat, endpat
当NR==1是开始匹配,知道/hanmm/被匹配,awk停止工作spider@spider:/tmp$ awk 'NR==1,/hanmeimei/ {print $0}' test.txt jim 5445 33 herny 81558 28 lilei 25478 55 hanmeimei 11444 54内置变量
NR 已经读取过的记录数。 FNR 从当前文件中读出的记录数。 FILENAME 输入文件的名字。 FS 字段分隔符(缺省为空格)。 RS 记录分隔符(缺省为换行)。 OFMT 数字的输出格式(缺省为% g)。 OFS 输出字段分隔符。 ORS 输出记录分隔符。 NF 最后一列 如果你只处理一个文件,则NR 和FNR 的值是一样的。但如果是多个文件, NR是对所有的文件来说的,而FNR 则只是针对当前文件而言。控制流
1>if语句spider@spider:/tmp$ awk 'BEGIN {N=3};{if (NR>N){print NR,$1}else{printf "I am not result\n"}}' test.txt I am not result I am not result I am not result 4 hanmeimei 5 yina 6 teddy 7 allen 8 andy 9 jay2>while语句
spider@spider:/tmp$ awk '{i=0;while (i < NF){printf "*";i++}printf "\n"}' test.txt
***
***
***
***
***
***
***
***
***3>for语句
spider@spider:/tmp$ awk '{for(x=1;x<NF;x+=1){printf"%s ",$1 "zbb";}printf "\n";}' test.txt jimzbb jimzbb hernyzbb hernyzbb lileizbb lileizbb hanmeimeizbb hanmeimeizbb yinazbb yinazbb teddyzbb teddyzbb allenzbb allenzbb andyzbb andyzbb jayzbb jayzbb内置函数
1>lengthspider@spider:/tmp$ awk 'NR==1{print length}' test.txt 112>split
awk的内建函数split允许你把一个字符串分隔为单词并存储在数组中。你可以自己定义域分隔符或者使用现在FS(域分隔符)的值。
格式:
split (string, array, field separator)
split (string, array) –>如果第三个参数没有提供,awk就默认使用当前FS值。time='12:34:56';echo $time|awk '{split($0,a,":");print a[1],a[2],a[3]}' 12 34 563>match
awk会在原字串中找寻合乎正则表达式的子字串。 若合乎条件的子字串有多个, 则以原字串中最左方的子字串为准。 awk找到该字串后会依此字串为依据进行下列动作:设定awk內建变量 RSTART, RLENGTH :
RSTART : 合条件的子字串在原字串中的位置。
若未找到合条件的子字串, RSTART=0;
RLENGTH : 合条件的子字串长度。
若未找到合条件的子字串, RLENGTH=-1。
返回 RSTART 之值。spider@spider:/tmp$ awk '{match($0,/^a.+/);print RSTART,RLENGTH}' test.txt 0 -1 0 -1 0 -1 0 -1 0 -1 0 -1 1 14 1 10 0 -14>index
若原字串中含有欲找寻的子字串,则返回该子字串在原字串中第一次出现的位置,若未曾出现该子字串则返回0。spider@spider:/tmp$ awk 'NR>6{print index($1,"a")}' test.txt 1 1 25>sub
sub ( regexp,replacement,target ) 在字符串target 中寻找符合regexp 的最长、最靠左的地方,以字串replacement 代替最左边的regexp。spider@spider:/tmp$ awk '{sub(/^a.+/,"----",$1)};{print $0}' test.txt jim 5445 33 herny 81558 28 lilei 25478 55 hanmeimei 11444 54 yina 9364585 44 teddy 25552 18 ---- 54251 70 ---- 412 4 jay 88424 756>substr
substr(string,start,length)返回字符串string的子字符串,这个子字符串的长度为
length,从第start个位置开始。spider@spider:/tmp$ awk '{print substr($0,1,7)}' test.txt jim 544 herny 8 lilei 2 hanmeim yina 93 teddy 2 allen 5 andy 41 jay 884附:
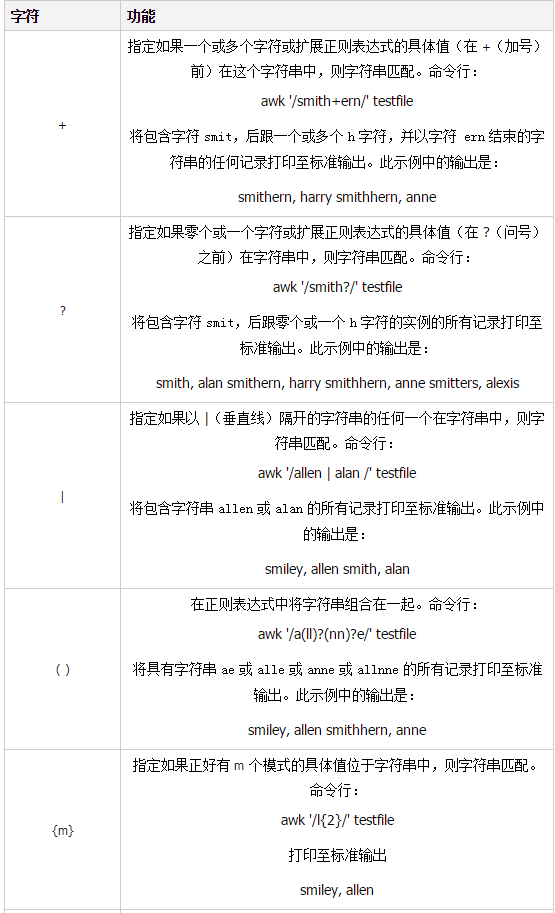
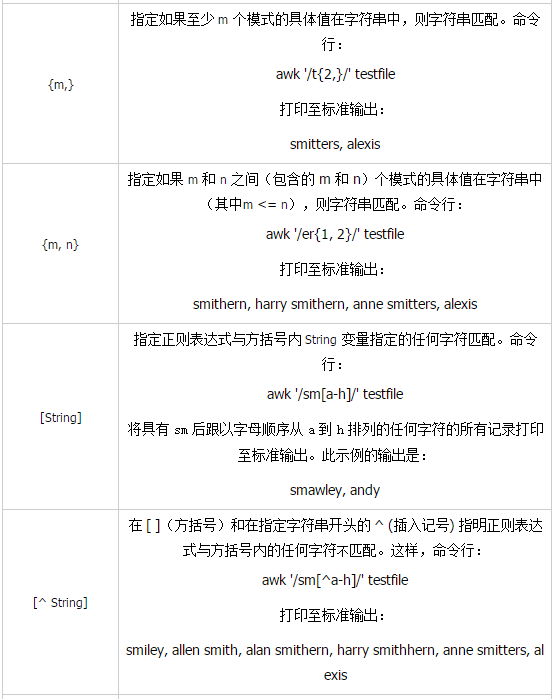
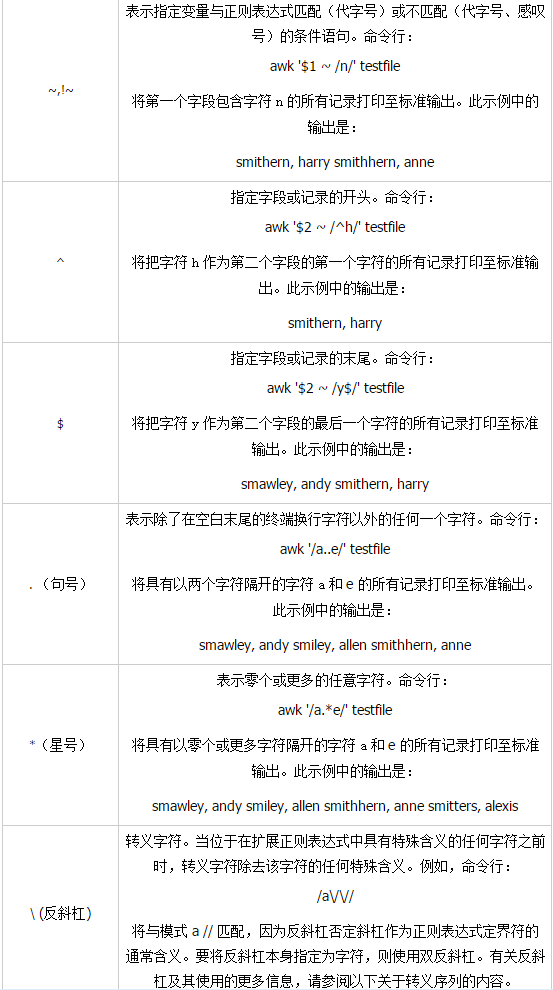















 811
811
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









