







 本文详细解析了目标检测中常见的损失函数,包括类别损失(如CrossEntropyLoss、FocalLoss)和位置损失(如L1Loss、L2Loss、SmoothL1Loss、IoULoss及其变种)。通过实例说明了各种损失函数的特点和应用场景。
本文详细解析了目标检测中常见的损失函数,包括类别损失(如CrossEntropyLoss、FocalLoss)和位置损失(如L1Loss、L2Loss、SmoothL1Loss、IoULoss及其变种)。通过实例说明了各种损失函数的特点和应用场景。
文章目录
一般的目标检测模型包含两类损失函数,一类是类别损失(分类),另一类是位置损失(回归)。这两类损失函数往往用于检测模型最后一部分,根据模型输出(类别和位置)和实际标注框(类别和位置)分别计算类别损失和位置损失。
类别损失
Cross Entropy Loss
交叉熵损失是基于“熵”这个概念,熵用来衡量信息的不确定性。对于概率分布为
p
(
X
)
p(X)
p(X)的随机变量
X
X
X,熵可以表示为:
f
(
x
)
=
{
−
∫
p
(
x
)
log
p
(
x
)
d
x
x
连
续
−
∑
x
log
p
(
x
)
x
离
散
f(x)=\left\{ \begin{aligned} -\int{p(x)\log p(x)dx} & &{x连续}\\ -\sum_{x}\log p(x) & &{x离散} \end{aligned} \right.
f(x)=⎩⎪⎪⎨⎪⎪⎧−∫p(x)logp(x)dx−x∑logp(x)x连续x离散
当
X
X
X分布的不确定性越大,对应的熵越大(对应
log
(
x
)
\log(x)
log(x))积分面积),反之,熵越小。当把熵用于分类问题时,分类的结果越好(可以理解为预测为某一类的概率远高于其他类别的概率),不确定性越低,熵就越小;反之,分类的结果越差(可以理解为预测的各个类别的概率都比较高,没有明确的分界线),此时不确定性越强,熵就越高。
针对以上分析,可以把熵用于分类问题的损失,根据分类的类别数量不同,可以分为二元交叉熵损失和多分类交叉熵损失。
对于二分类问题(即0-1分类),即属于第1类的概率为
p
p
p,属于第0类的概率为
1
−
p
1-p
1−p。则二元交叉熵损失可表示为:
L
=
{
−
log
(
1
−
p
)
y
=
0
−
log
(
p
)
y
=
1
L=\left\{ \begin{aligned} -\log (1-p) & &{y=0}\\ -\log (p) & &{y=1} \end{aligned} \right.
L={−log(1−p)−log(p)y=0y=1
也可以统一写成如下形式:
L
=
−
y
∗
log
(
p
)
−
(
1
−
y
)
∗
log
(
1
−
p
)
L = -y* \log(p) - (1-y) * \log(1-p)
L=−y∗log(p)−(1−y)∗log(1−p)
可以理解为:当实际类别为1时,我们希望预测为类别1的概率高一点,此时
l
o
g
(
p
)
log(p)
log(p)的值越小,产生的损失越小;反之,我们希望预测为类别0的概率高一点,此时
l
o
g
(
1
−
p
)
log(1-p)
log(1−p)的值越小,产生的损失也越小。在实际应用中,二分类的类别概率通常采用sigmoid函数把结果映射到(0,1)之间。
对比二元交叉熵损失,可以推广到多分类交叉熵损失,定义如下:
L
(
X
i
,
Y
i
)
=
−
∑
j
=
1
c
y
i
j
∗
log
(
p
i
j
)
L(X_i, Y_i) = -\sum_{j=1}^{c}{y_{ij} * \log(p_{ij})}
L(Xi,Yi)=−j=1∑cyij∗log(pij)
其中,
Y
i
Y_i
Yi是一个one-hot向量,并定义如下:
y
i
j
=
{
1
第
i
个
样
本
属
于
类
别
j
0
o
t
h
e
r
w
i
s
e
y_{ij}=\left\{ \begin{aligned} 1 & &{第i个样本属于类别j}\\ 0 & &{otherwise} \end{aligned} \right.
yij={10第i个样本属于类别jotherwise
p
i
j
p_{ij}
pij表示第
i
i
i个样本属于类别j的概率。在实际应用中通常采用SoftMax函数来得到样本属于每个类别的概率。
Focal Loss
Focal Loss首次在目标检测框架RetinaNet中提出,RetinaNet可以参考
它是对典型的交叉信息熵损失函数的改进,主要用于样本分类的不平衡问题。为了统一正负样本的损失函数表达式,首先做如下定义:
p
t
=
{
p
y
=
1
1
−
p
y
=
0
p_t=\left\{ \begin{aligned} p & &{y =1}\\ 1-p & &{y=0} \end{aligned} \right.
pt={p1−py=1y=0
p
t
p_t
pt在形式上就表示被预测为对应的正确类别的置信度。这样二分类交叉信息熵损失就可以重写成如下形式:
C
E
(
p
,
y
)
=
C
E
(
p
t
)
=
−
log
(
p
t
)
CE(p,y) = CE(p_t) = -\log(p_t)
CE(p,y)=CE(pt)=−log(pt)
为了平衡多数类和少数类的损失,一种常规的思想就是在损失项前乘上一个平衡系数
α
∈
(
0
,
1
)
\alpha\in(0,1)
α∈(0,1),当类别为正时,取
α
t
=
α
\alpha_t=\alpha
αt=α,当类别为负时,取
α
t
=
1
−
α
\alpha_t=1-\alpha
αt=1−α,这样得到的带有平衡系数的交叉信息熵损失定义如下:
C
E
(
p
t
)
=
−
α
log
(
p
t
)
CE(p_t) = -\alpha \log(p_t)
CE(pt)=−αlog(pt)
这样,根据训练样本中正负样本数量来选取
α
\alpha
α的值,就可以达到平衡正负样本的作用。然而,这样做还不能对简单和困难样本区别对待,在目标检测中,既要平衡多数类(背景)和少数类(包含目标的前景),还要平衡简单样本和困难样本,而往往训练过程中往往遇到的问题就是大量简单的背景样本占据损失函数的主要部分。因此,还需要对上述带有平衡系数的交叉信息熵损失做进一步的改进。于是就有了Focal Loss,它定义如下:
F
L
(
p
t
)
=
−
(
1
−
p
t
)
γ
log
(
p
t
)
FL(p_t) = -(1-p_t)^{\gamma} \log(p_t)
FL(pt)=−(1−pt)γlog(pt)
相比于上面的加了平衡系数
α
\alpha
α的损失函数相比,Focal Loss有以下两点不同:
- 固定的平衡系数 α \alpha α替换成了可变的平衡系数 ( 1 − p t ) (1-p_t) (1−pt)
- 多了另外一个调节因子 γ \gamma γ,且 γ ≥ 0 \gamma\ge0 γ≥0
位置损失
L1 Loss
L1 loss即平均绝对误差(Mean Absolute Error, MAE),指模型预测值和真实值之间距离的平均值。
M
A
E
=
∑
n
=
1
n
∣
f
(
x
i
)
−
y
i
∣
n
MAE=\frac{\sum_{n=1}^n{|f(x_i)-y_i|}}{n}
MAE=n∑n=1n∣f(xi)−yi∣
记
x
=
f
(
x
i
−
y
i
)
x=f(x_i-y_i)
x=f(xi−yi),对于单个样本,L1 loss可表示为:
M
A
E
=
∣
f
(
x
i
)
−
y
i
∣
=
∣
x
∣
MAE= |f(x_i)-y_i|=|x|
MAE=∣f(xi)−yi∣=∣x∣
L2 Loss
L2 loss即均方误差损失(Mean Square Error, MSE),指预测值和真实值之差的平方的平均值。
M
S
E
=
∑
n
=
1
n
(
f
(
x
i
)
−
y
i
)
2
n
MSE=\frac{\sum_{n=1}^n{(f(x_i)-y_i)^2}}{n}
MSE=n∑n=1n(f(xi)−yi)2
对于单个样本,L2 loss可表示为:
M
S
E
=
(
f
(
x
i
)
−
y
i
)
2
=
x
2
MSE = (f(x_i)-y_i)^2=x^2
MSE=(f(xi)−yi)2=x2
Smooth L1 Loss
Smooth L1 loss是基于L1 loss修改得到,对于单个样本,记
x
x
x为预测值和真实值的差值,则对应的Smooth L1 loss可表示为:
f
(
x
)
=
{
0.5
x
2
i
f
∣
x
∣
<
1
∣
x
∣
−
0.5
o
t
h
e
r
w
i
s
e
f(x)=\left\{ \begin{aligned} 0.5x^2 & &{if|x|<1}\\ |x|-0.5 & &{otherwise} \end{aligned} \right.
f(x)={0.5x2∣x∣−0.5if∣x∣<1otherwise
IoU Loss
IoU类的损失函数都是基于预测框和标注框之间的IoU(交并比),记预测框为
P
P
P,标注框为
G
G
G,则对应的IoU可表示为:
I
o
U
=
P
∩
G
P
∪
G
IoU = \frac{P \cap G}{P \cup G}
IoU=P∪GP∩G
即两个框的交集和并集的比值。IoU loss定义为:
L
I
=
1
−
I
o
U
L_I = 1 - IoU
LI=1−IoU
GIoU Loss
IoU反映了两个框的重叠程度,在两个框不重叠时,IoU衡等于0,此时IoU loss恒等于1。而在目标检测的边界框回归中,这显然是不合适的。因此,GIoU loss在IoU loss的基础上考虑了两个框没有重叠区域时产生的损失。具体定义如下:
L
G
=
1
−
I
o
U
+
R
(
P
,
G
)
=
1
−
I
o
U
+
∣
C
−
P
∪
G
∣
∣
C
∣
L_G = 1 - IoU + R(P,G)= 1 - IoU + \frac{|C-P \cup G|}{|C|}
LG=1−IoU+R(P,G)=1−IoU+∣C∣∣C−P∪G∣
其中,C表示两个框的最小包围矩形框,
R
(
P
,
G
)
R(P,G)
R(P,G)是惩罚项。从公式可以看出,当两个框没有重叠区域时,IoU为0,但
R
R
R依然会产生损失。极限情况下,当两个框距离无穷远时,
R
→
1
R \rightarrow1
R→1
DIoU Loss
IoU loss和GIoU loss都只考虑了两个框的重叠程度,但在重叠程度相同的情况下,我们其实更希望两个框能挨得足够近,即框的中心要尽量靠近。因此,DIoU在IoU loss的基础上考虑了两个框的中心点距离,具体定义如下:
L
G
=
1
−
I
o
U
+
R
(
P
,
G
)
=
1
−
I
o
U
+
ρ
2
(
p
,
g
)
c
2
L_G = 1 - IoU + R(P,G)= 1 - IoU + \frac{\rho^2(p,g)}{c^2}
LG=1−IoU+R(P,G)=1−IoU+c2ρ2(p,g)
其中,
ρ
\rho
ρ表示预测框和标注框中心端的距离,
p
p
p和
g
g
g是两个框的中心点。
c
c
c表示两个框的最小包围矩形框的对角线长度。当两个框距离无限远时,中心点距离和外接矩形框对角线长度无限逼近,
R
→
1
R \rightarrow1
R→1
下图直观显示了不同情况下的IoU loss、GIoU loss和DIoU loss结果:
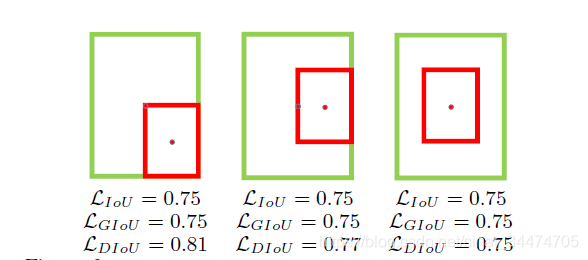
其中,绿色框表示标注框,红色框表示预测框,可以看出,最后一组的结果由于两个框中心点重合,检测效果要由于前面两组。IoU loss和GIoU loss的结果均为0.75,并不能区分三种情况,而DIoU loss则对三种情况做了很好的区分。
CIoU Loss
DIoU loss考虑了两个框中心点的距离,而CIoU loss在DIoU loss的基础上做了更详细的度量,具体包括:
- 重叠面积
- 中心点距离
- 长宽比
具体定义如下:
L
G
=
1
−
I
o
U
+
R
(
P
,
G
)
=
1
−
I
o
U
+
ρ
2
(
p
,
g
)
c
2
+
α
v
L_G = 1 - IoU + R(P,G)= 1 - IoU + \frac{\rho^2(p,g)}{c^2} + \alpha v
LG=1−IoU+R(P,G)=1−IoU+c2ρ2(p,g)+αv
其中:
v = 4 π 2 ( a r c t a n w g h g − a r c t a n w p h p ) 2 v = \frac {4} {{\pi}^2} (arctan\frac{w^g}{h^g} - arctan\frac{w^p}{h^p})^2 \\ v=π24(arctanhgwg−arctanhpwp)2
α = v ( 1 − I o U ) + v \alpha = \frac{v}{(1-IoU)+v} α=(1−IoU)+vv
可以看出,CIoU loss在DIoU loss的不同在于最后一项 α v \alpha v αv, v v v度量了两个框的长宽比的距离, α \alpha α相当于一个平衡系数,取值由IoU和 v v v共同决定。需要注意的是,计算 v v v关于 w p w^p wp和 h p h^p hp的梯度时,会在分母上出现 w p 2 + h p 2 {w^p}^2+{h^p}^2 wp2+hp2,而CIoU中, w p w^p wp和 h p h^p hp均是归一化后的值,会导致 w p 2 + h p 2 {w^p}^2+{h^p}^2 wp2+hp2的结果很小,容易出现梯度爆炸。因此,在官方的代码实现上,对损失函数做了优化,移除了梯度公式中 w p 2 + h p 2 {w^p}^2+{h^p}^2 wp2+hp2。
在使用CIoU loss时需要注意的是,在代码实现上,公式中的 v v v仅用于计算 α \alpha α,而原来的 v v v会用另一个变量 a r a_r ar代替,在计算 a r a_r ar的时候需要用到标准化的宽高(使用绝对宽高loss会发散)。
注:关于IoU系列损失更详细的分析可以参考论文:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









