







 LibraR-CNN是一种新的目标检测框架,旨在解决模型训练过程中的不平衡问题,包括采样、特征和目标层面的不平衡。通过引入平衡化IOU采样、平衡化特征金字塔和平衡化L1损失,显著提升了检测性能,尤其在COCO数据集上比FPNFasterR-CNN和RetinaNet分别高出2.5%和2%的mAP。
LibraR-CNN是一种新的目标检测框架,旨在解决模型训练过程中的不平衡问题,包括采样、特征和目标层面的不平衡。通过引入平衡化IOU采样、平衡化特征金字塔和平衡化L1损失,显著提升了检测性能,尤其在COCO数据集上比FPNFasterR-CNN和RetinaNet分别高出2.5%和2%的mAP。
论文地址:https://arxiv.org/pdf/1904.02701.pdf
摘要
相比于模型框架,模型的训练过程对于检测器是否成功也同样重要。在本文工作中,我们重新研究了标准的训练过程,发现检测的性能经常受限于模型训练过程中的不平衡。这种不平衡包括以下3个层面:采样层面、特征层面和目标层面。为了缓和着中国不平嗯带来的不利影响,我们提出了一种简单有效的面向目标检测中的不平衡学习的框架,即Libra R-CNN,该框架有3个新颖的部分组成:平衡化IOU采样、平衡化特征金字塔和平衡话L1损失。这3个部分分别用于缓解采样层面、特征层面和目标层面的不平衡。受益于整体的平衡化设计,Libra R-CNN显著提高了检测性能,在不采用其他技巧的前提下,Libra R-CNN在COCO数据集上的表现比FPN Faster R-CNN和RetinaNet分别高了2.5%和2%的mAP。
动机
典型的目标检测框架主要包含候选框提取、从候选框提取特征和预测(分类和边界框回归)3个步骤。也因此目标检测的性能受以下几点的影响较大:
- 选择的候选框是否具有代表性(质量怎么样?是否包含了大部分的目标?)
- 提取到的特征有没有得到充分的利用?
- 针对所有的目标设计的损失函数是否是最优的?
然而,经典的训练过程在在上述的三个方面有表现出严重的“不平衡”问题,具体表现为:
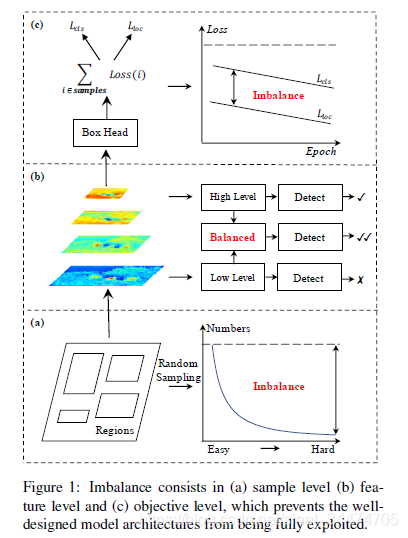
- **采样层面的不平衡衡。**在目标检测训练过程中困难样本往往比简单样本有更大的价值,但在一张图片中,背景区域要远远大于存在目标的区域。在候选框提取阶段,往往都是通过随机采样的方式选择候选框参与训练,这就导致了每次采样的结果包含大部分简单样本(主要是背景)和少数的困难的样本(如下图a)。虽然现有的研究中已经有针对这一问题的研究,如困难样本挖掘技术和Focal Loss,但困难样本挖掘对噪声比较敏感,而Focal Loss主要针对一阶段检测模型(二阶段模型中,大部分的简单样本已经被候选区域提取网络过滤掉,且在训练阶段也严格控制了正负样本的比例,如1:3)
- **特征层面的不平衡。**在深层的卷积网络中,高层的特征语义信息更丰富,而浅层的特征更加精细。因此,一个自然而然的想法就是融合深层和浅层的特征,从而优势互补。但同时也带来一个问题:怎样融合的效果才更合理?在现有的研究中,以特征金字塔网络为代表的做法是融合相邻的不同分辨率特征图。而本文作者也指出:特征融合时应该平等对待不同分辨率的特征(如下图b)。特征金字塔的处理方式只考虑了相邻分辨率的特征,导致不相邻的语音特征在信息传播的过程中会被逐渐削弱。
- **目标层面的不平衡。**目标检测包含了分类任务和定位任务,因此也对应着不同的损失函数,在训练过程中,如果不能很好的权衡两类损失,很有可能导致训练被某一个任务主导,导致整体的检测性能下降(如下图c)。这一点和在候选框选取过程中很像,例如在候选框采样时,困难样本产生的梯度可能会远高于简单样本产生的梯度,甚至当梯度过大时,导致回归的Loss波动太大,直接导致模型发散。
主要工作
论文的主要工作也是围绕上面提到的三个层面的不平衡展开,具体如下。
IOU平衡化采样
论文在采样上的思想来源于对目标检测中一个问题的思考,即:候选框的的难易程度是否和其于实际标注框的重叠程度正相关?换句话说,是不是候选框和标注框的IOU越低,训练难度越大?为了论文中首先做了随机采样实验,并观察IOU分布,如下图:
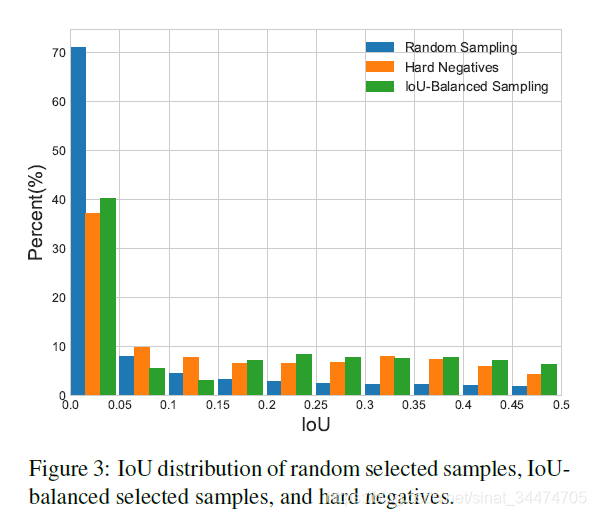
文中指出,超过60%的困难背景样本(一般IOU较高的背景样本在分类的时候比较困难)的IOU高于0.05,而通过随机采样得到的训练样本中,IOU高于0.05的样本只占30%。也就是说,大部分的困难背景样本被混到了多数简单样本中了。
为此,论文提出了分层采样策略,假设要从 M M M个候选框中选取 N N N个负样本,那么每个负样本被选到的概率 p = N M p=\frac{N}{M} p=MN。IOU平衡化采样的做法是首先根据IOU将所有的样本划分到 K K K个的区间中,每个区间对应的候选框数量记作 M k M_k Mk,然后从每个区间中选择 N K \frac{N}{K} KN个负样本。这样的好处在于,在选取困难负样本的时候,每个不同IOU区间的样本都会被照顾到,避免了随机采样得到的样本中大多数候选框的IOU都低于0.05的情况(IOU低于0.05的大多数为简单负样本),从而一定程度上增加了困难负样本的数量。
上面的分层采样是针对困难的负样本,理论上可以通过相同的采样方式对来选取正样本来保证困难正样本的数量。然而,在当前基于候选框的二阶段模型中,候选框中正样本数量相比于负样本往往较少。因此,论文采用了一种替代方案,对于一张图片中的每个标注框,都随机选取若干个正样本。(相当于对于图片中中的标注框,不论是困难还是简单的标注框,都会生成相同数量的候选框,从而保证困难正样本的数量)
平衡化特征金字塔
平衡化特征金字塔的主要思想是采用多级融合得到的特征图来增强每一级的特征图的表达能力。在实现上包含4个步骤:
- 重新调整特征图大小
- 整合特征图信息
- 改善特征图信息
- 特征图增强
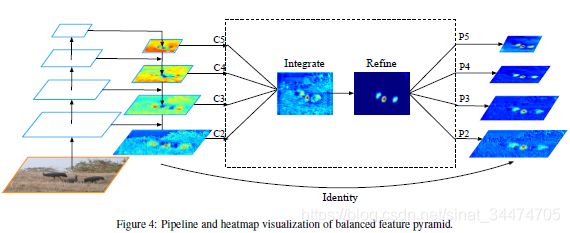
在用卷积神经网络提取图片特征时,不同深度的特征图按大小分成不同的层级,越浅层的特征图越大,越深层的特征图越小。为了增强特征图的表达能力,在目标检测中常把不同层级的特征图融合在一起(典型的方式如特征金字塔融合相邻的特征信息),Libra R-CNN的做法相对于是对于特征金字塔的延伸,利用多个层级的特征图信息来加强每一层级特征图的表达能力。具体过程如上图,首先对于几个不同层级的特征图 C 2 , C 3 , C 4 , C 5 C_2, C_3, C_4, C_5 C2,C3,C4,C5,都resize到一个中间大小(如 C 4 C_4 C4),对于比 C 4 C_4 C4小的 C 5 C_5 C5,采用插值的方式调整大小,对于比 C 4 C_4 C4大的 C 2 , C 3 C_2, C_3 C2,C3,采用最大池化的方式调整。之后再求4个层级的特征图的均值得到综合的特征图信息。最后再把得到的特征图均值以插值/最大池化的方式融合到各个层级的特征图上,从而实现多层级的特征融合。
平衡化L1损失
目标检测损失中包含分类损失和位置损失。平衡两类损失,最普遍的做法是给位置损失加一个权重。但这种做法会有一个潜在的问题:对于训练中的少数困难样本,预测的结果和实际的位置往往偏差较大,此时权重会将大的损失放大,从而产生更大的梯度信息,严重时可能会破坏模型的收敛过程,同时弱化多数简单样本产生的梯度信息。因此,为了平衡不同难度的样本带来的位置损失,论文基于smooth L1损失,提出了balanced L1损失,其对应的损失函数和梯度表达式如下:
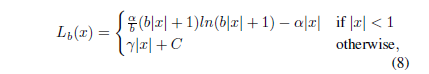
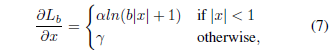
其中,几个参数项满足以下约束:
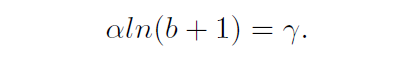
对应的曲线如下:
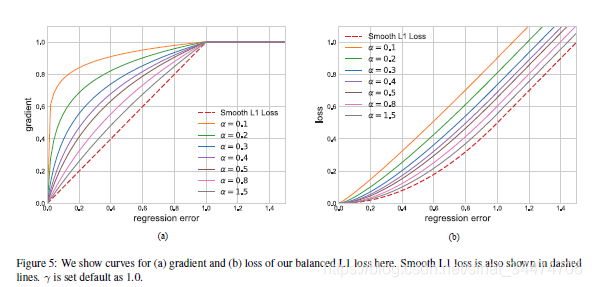
可以看出,相比于smooth L1损失,balanced L1损失在取不同的 α \alpha α 值下对简单样本产生的梯度有不同的增强效果,从而平衡了简单样本和困难样本产生的位置损失。
实验结果
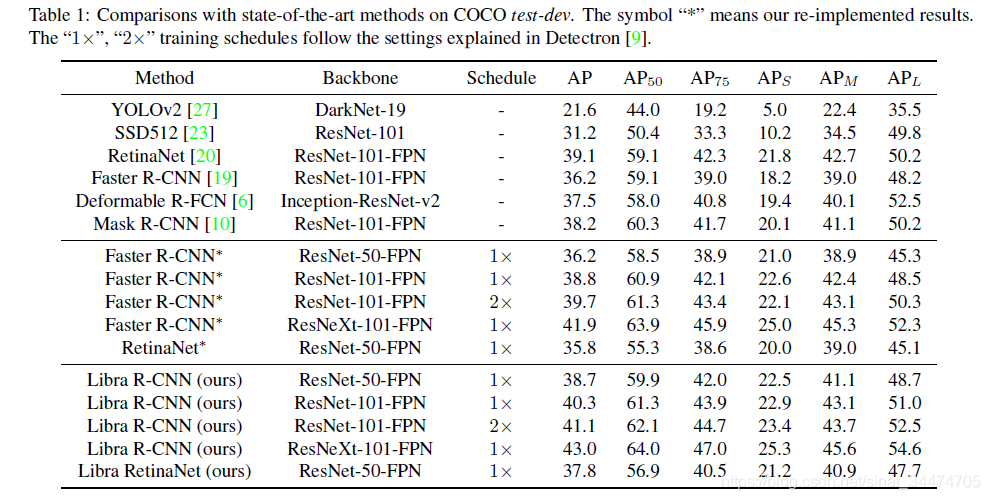
可以看出,Libra中的平衡化机制,不论用于一阶段模型(RetinaNet)和二阶段模型(Faster R-CNN),都带来了2%mAP左右的性能提升。
而在下表中的消融实验中也可以看出,Faster R-CNN中的3种平衡化策略在COCO数据集上都带来了约1%的mAP提升。
P左右的性能提升。
而在下表中的消融实验中也可以看出,Faster R-CNN中的3种平衡化策略在COCO数据集上都带来了约1%的mAP提升。


















 1973
1973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









