







一、Redis数据类型和数据结构
1.常用数据类型
1. String(字符串)
string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value,但一个字符串类型的值能存储最大容量是512M。string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。一般做一些复杂的计数功能的缓存。
实例
redis 127.0.0.1:6379> SET name "w3cschool.cn"
OK
redis 127.0.0.1:6379> GET name
"w3cschool.cn"其数据结构用的是SDS:
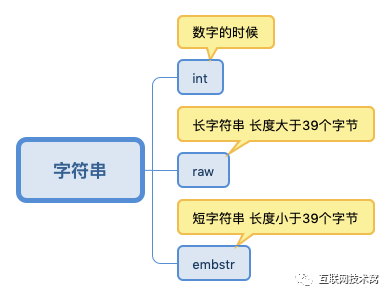
其中:embstr和raw都是由SDS动态字符串构成的。唯一区别是:raw是分配内存的时候,redisobject和 sds 各分配一块内存,而embstr是redisobject和raw在一块儿内存中。
2. Set(集合)
Set 就是一个集合,集合的概念就是一堆不重复值的组合。利用 Redis 提供的 Set 数据结构,可以存储一些集合性的数据。
如:
```
redis 127.0.0.1:6379> sadd w3cschool.cn rabitmq
(integer) 1
redis 127.0.0.1:6379> sadd w3cschool.cn rabitmq
(integer) 0
```
Redis DEL 命令用于删除已存在的键。不存在的 key 会被忽略。
如果键被删除成功,命令执行后输出 (integer) 1,否则将输出 (integer) 0
Redis Smembers 命令返回集合中的所有的成员。 不存在的集合 key 被视为空集合。如:
redis 127.0.0.1:6379> SADD myset1 "hello"
(integer) 1
redis 127.0.0.1:6379> SADD myset1 "world"
(integer) 1
redis 127.0.0.1:6379> SMEMBERS myset1
1) "World"
2) "Hello"其用到的数据结构主要为inset和hash表如下:

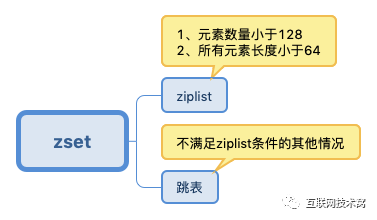
3. sorted set(有序集合)
sorted set多了一个权重参数score,集合中的元素能够按score进行排列。可以做排行榜应用,取TOP N操作。
sorted set可以用来做延时任务。最后一个应用就是可以做范围查找。
其数据结构如下:
4. 列表(List)
List数据结构是链表结构是双向的,可以在链表左,右两边分别操作,同时也会用到压缩列表;

使用List的数据结构,可以做简单的消息队列的功能(既可以保证消息的顺序性)。另外还有一个就是,可以利用lrange命令,做基于redis的分页功能,性能极佳,用户体验好。
5. 哈希(Hash)
这里value存放的是结构化的对象,比较方便的就是操作其中的某个字段。
其用到的数据结构主要为ziplist和hash表如下:

如在做单点登录的时候,就是用这种数据结构存储用户信息,以cookieId作为key,设置30分钟为缓存过期时间,能很好的模拟出类似session的效果。
整体数据类型和数据结构可参考如下:

2.常用数据结构
1.动态字符串SDS
SDS是"simple dynamic string"的缩写。redis中所有场景中出现的字符串,基本都是由SDS来实现的
- 所有非数字的key。例如 setmsg"hello world" 中的key msg.
- 字符串数据类型的值。例如`` set msg "hello world"中的msg的值"hello wolrd"
- 非字符串数据类型中的“字符串值”。例如 RPUSH fruits"apple""banana""cherry"中的"apple" "banana" "cherry"
SDS长这样:
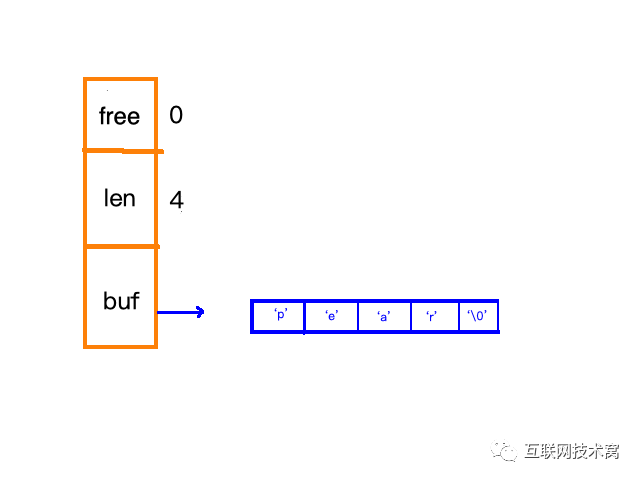
free:还剩多少空间 len:字符串长度 buf:存放的字符数组
空间预分配
为减少修改字符串带来的内存重分配次数,sds采用了“一次管够”的策略:
- 若修改之后sds长度小于1MB,则多分配现有len长度的空间
- 若修改之后sds长度大于等于1MB,则扩充除了满足修改之后的长度外,额外多1MB空间
惰性空间释放
为避免缩短字符串时候的内存重分配操作,sds在数据减少时,并不立刻释放空间。
————————————————
版权声明:本文为CSDN博主「JavaShark」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/JavaShark/article/details/125286203
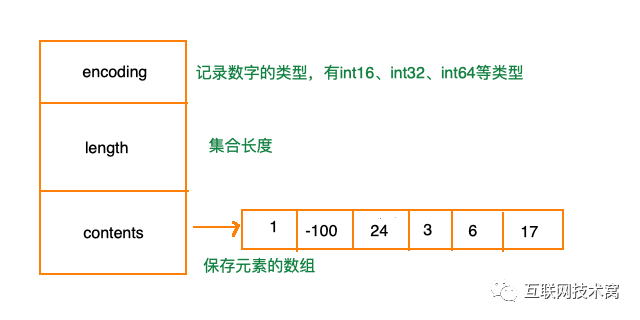
2.intset
整数集合是集合键的底层实现方式之一,是基于数组来实现的。
3.哈希表
哈希表略微有点复杂。哈希表的制作方法一般有两种,一种是:开放寻址法,一种是 拉链法。redis的哈希表的制作使用的是 拉链法。
整体结构如下图:
2.跳跃表
产生背景

拍卖行的商品总数量有几十万件,对应数据库商品表的几十万条记录。
如果是按照商品名称精确查询还好办,可以直接从数据库查出来,最多也就上百条记录。
如果是没有商品名称的全量查询怎么办?总不可能把数据库里的所有记录全查出来吧,而且还要支持不同字段的排序。
所以,只能提前在内存中存储有序的全量商品集合,每一种排序方式都保存成独立的集合,每次请求的时候按照请求的排序种类,返回对应的集合。
比如按价格字段排序的集合:
比如按等级字段排序的集合:
需要注意的是,当时还没有Redis这样的内存数据库,所以小灰只能自己实现一套合适的数据结构来存储。
拍卖行商品列表是线性的,最容易表达线性结构的自然是数组和链表。可是,无论是数组还是链表,在插入新商品的时候,都会存在性能问题。
基于数组的实现
如果要插入一个等级是3的商品,首先要知道这个商品应该插入的位置。使用二分查找可以最快定位,这一步时间复杂度是O(logN)。插入过程中,原数组中所有大于3的商品都要右移,这一步时间复杂度是O(N)。所以总体时间复杂度是O(N)。
基于链表的实现
如果要插入一个等级是3的商品,首先要知道这个商品应该插入的位置。链表无法使用二分查找,只能和原链表中的节点逐一比较大小来确定位置。这一步的时间复杂度是O(N)。
插入的过程倒是很容易,直接改变节点指针的目标,时间复杂度O(1)。因此总体的时间复杂度也是O(N)。
这对于拥有几十万商品的集合来说,这两种方法显然都太慢了。
跳跃表的概念
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针(注:可以理解为维护了多条路径),从而达到快速访问节点的目的。
与Redis当中的Sorted-set不谋而合。而Sorted-set这种有序集合,正是对于跳跃表的改进和应用。

特点:每一层索引节点树是下策的一半左右,直到最上一层只有两个节点。

跳跃表的效率可以和平衡树想媲美了,最关键是它的实现相对于平衡树来说,代码的实现上简单很多
1.跳跃表插入原理
1.新节点和各层索引节点逐一比较,确定原链表的插入位置。O(logN)
2.把索引插入到原链表。O(1)
3.利用抛硬币的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(logN)
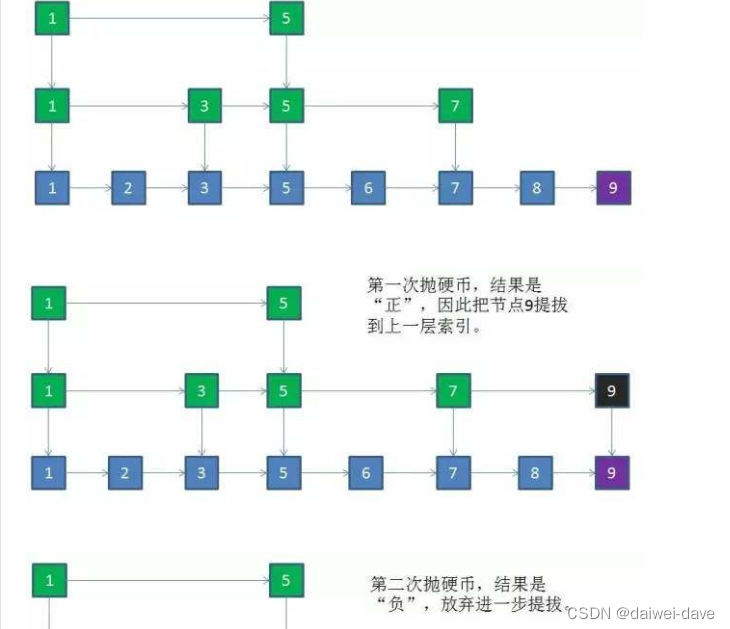
总体上,跳跃表插入操作的时间复杂度是O(logN),而这种数据结构所占空间是2N,既空间复杂度是 O(N)。
为什么使用抛银币的方法?

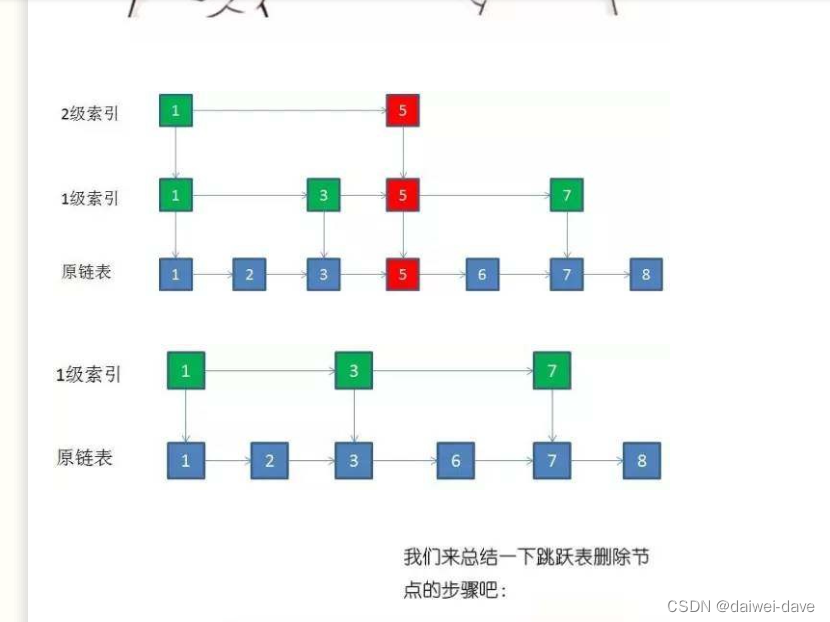
2.跳跃表删除原理
1.自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)
2.删除每一层查找到的节点,如果该层只剩下1个节点,删除整个一层(原链表除外)。O(logN)
总体上,跳跃表删除操作的时间复杂度是O(logN)。
3.跳跃表和平衡二叉树的比较

参考:
1.漫画算法:什么是跳跃表?漫画算法:什么是跳跃表? - lijiantao_smile - 博客园
Redis中的应用
和链表、字典等数据结构被广泛地应用在Redis内部不同,Redis只在两个地方用到了跳跃表,一个是实现有序集合键,另一个是在集群节点中用作内部数据结构,除此之外,跳跃表在Redis里面没有其他用途。
3.压缩列表
产生背景
听到“压缩”两个字,直观的反应就是节省内存。之所以说这种存储结构节省内存,是相较于数组的存储思路而言的。我们知道,数组要求每个元素的大小相同,如果我们要存储不同长度的字符串,那我们就需要用最大长度的字符串大小作为元素的大小(假设是20个字节)。存储小于 20 个字节长度的字符串的时候,便会浪费部分存储空间。

为了更好的利用数组的优势(排列紧凑,内存连续,CPU局部性原理优势),同时避免上述不足。我们可以对数组进行压缩。不过这样我们遍历的时候并不知道每个元素的大小,因此也就无法计算出下一个节点的具体位置,那么,redis压缩列表是如何解决这个问题的呢?
压缩列表概念
压缩列表( ziplist) 本质上就是一个字节数组, 是 Redis 为了节约内存而设计的一种线性
数据结构, 可以包含多个元素, 每个元素可以是一个字节数组或一个整数。
压缩列表(ziplist)是列表键和哈希键的底层实现之一。当一个列表键只包含少量列表项,并且每个列表项要么就是小整数值,要么就是长度比较短的字符串,那么Redis就会使用压缩列表来做列表键的底层实现。
检索效率
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了,所以一般只用于数据量小的列表
为什么数据量小的时候用压缩列表 ?
为了省内存。
————————————————
版权声明:本文为CSDN博主「李孛欢」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_61543601/article/details/124851042
二、 redis线程模型和如何支持高并发
1.redis高并发性能报告
redis 有主从架构,一主多从,一般来说,很多项目其实就足够了,单主用来写入数据,单机几万QPS,多从用来查询数据,多个从实例可以提供每秒10万的QPS。
从 Redis 官方给出的测试数据来看,它的随机读写性能大约在 50 万次 / 秒左右
2.单线程的redis为什么这么快?
分析:这个问题其实是对redis内部机制的一个考察。很多人其实都不知道redis是单线程工作模型。所以,这个问题还是应该要复习一下的。
回答:主要是以下三点
(一)纯内存操作
(二)单线程操作,避免了频繁的上下文切换
(三)采用了非阻塞I/O多路复用机制
redis线程模型,如图所示
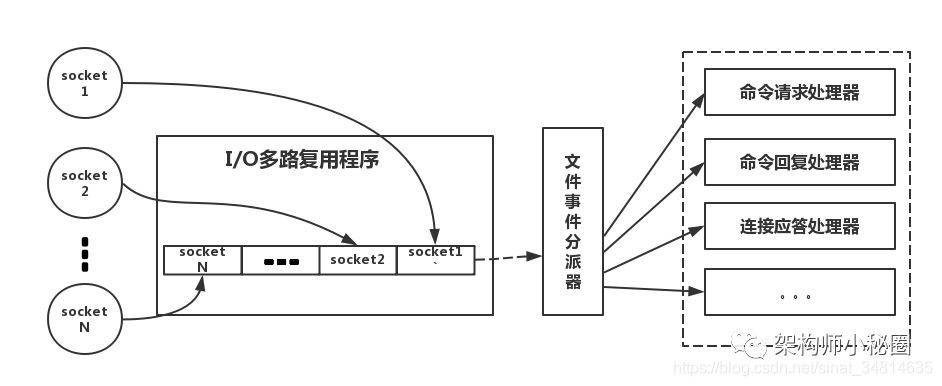
简单来说,就是。我们的redis-client在操作的时候,会产生具有不同事件类型的socket。在服务端,有一段I/0多路复用程序,将其置入队列之中。然后,文件事件分派器会创建一个线程,依次去队列中取,转发到不同类型的事件处理器中。
3.为什么 Redis 单线程却能支撑高并发?
尽管多个文件事件操作可能会并发的出现,但 I/O 多路复用系统总是会将所有产生的套接字( Socket ) 放到一个队列里面,然后通过这个队列,以有序、同步、每次一个套接字的方式向文件分派器传送套接字。只有当上一个套接字产生的事件被处理完毕之后, I/O 多路复用系统才会继续向文件分派器传送下一个套接字。
同时,单线程的模型反而带来了另一个好处是无需频繁的切换上下文,预防了多线程可能产生的竞争问题。
注意: Redis 6.0 之后的版本抛弃了单线程模型这一设计,原本使用单线程运行的 Redis 也开始选择性地使用多线程模型。
需要说明的是,这个I/O多路复用机制,redis还提供了select、epoll、evport、kqueue等多路复用函数库,大家可以自行去了解。
Reids 没有直接使用 epoll 的 API,而是同时支持4种I/O多路复用模型,对这些模型的 API 进行了封装。然后在编译阶段检查操作系统支持的I/O多路复用模型,并按照策略来决定复用那张模型。
如:I/O多路复用底层主要用的Linux 内核·函数(select,poll,epoll)来实现,windows不支持epoll实现,windows底层是基于winsock2的select函数实现的(不开源)。
I/O多路复用机制请参考: https://www.cnblogs.com/dolphin0520/p/3916526.html
思考
1.redis为何使用单线程而不是多线程?
1.因为纯内存操作,时间短阻塞等待时间短,用多线程本身不能提高性能,且频繁的上下文切换反而会降低性能。
2.如果使用每一个线程都去连接一个socket,线程很快将耗尽,其他线程将会阻塞,同样非常影响性能。
三、 redis持久化机制
redis提供两种方式进行持久化.默认 Redis 是 RDB
1.RDB持久化(Redis DataBase)(是全量同步吗??)
原理是将Reids在内存中的数据库记录定时dump到磁盘上的RDB持久化。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。其过程如下: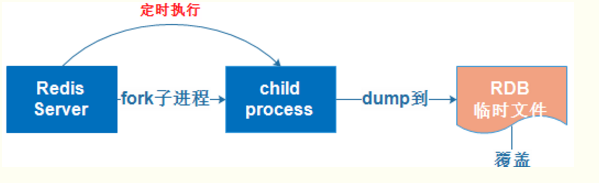
Redis会将数据集的快照dump到dump.rdb文件中。此外,我们也可以通过配置文件来修改Redis服务器dump快照的频率,在打开6379.conf文件之后,我们搜索save,可以看到下面的配置信息:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,则dump内存快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,则R快照。
1). 容灾性好,方便备份和持久化。
一旦采用该方式,那么你的整个Redis数据库将只包含dump.rdb一个文件,这对于文件备份而言是非常完美的。
比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易的进行恢复。
2). 性能最大化。
fork 子进程来完成写操作,让主进程继续处理命令,所以是 IO 最大化。
使用单独子进程来进行持久化,主进程不会进行任何 IO 操作,保证了 redis 的高性能
3)RDB恢复速度快,且启动效率高。
相比于AOF机制,恢复的更快.如果数据集很大,RDB的启动效率会更高,
1). 数据安全性低。
RDB 是间隔一段时间一般为5分钟或者更长的时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。
如果你想保证数据的高可用性,即最大限度的避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现宕机现象,此前没有来得及写入磁盘的数据都将丢失。
所以这种方式更适合数据要求不严谨的时候
2). 数据量太大时,可能会影响服务性能
由于RDB是通过fork子进程来协助完成数据持久化工作的,因此,如果当数据集较大时(比较吃CPU),可能会导致整个服务器停止服务几百毫秒,甚至是1秒钟。
2.AOF(append only file)持久化(增量同步)
原理是将Reids的操作日志以追加的方式写入文件
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。其过程如下:

在Redis的配置文件中存在三种同步方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件。
appendfsync everysec #每秒钟同步一次,该策略为AOF的缺省策略。
appendfsync no #从不同步。高效但是数据不会被持久化。
2.AOF的优势有哪些呢?
1). 该机制可以带来更高的数据安全性,即数据持久性。
Redis中提供了3中同步策略,即每秒同步、每修改同步和不同步。
每秒同步:也是异步完成的,其效率也是非常高的,即每隔一秒将会异步进行同步。即过所差的是一旦系统出现宕机现象,那么这一秒钟之内修改的数据将会丢失。
每修改同步:我们可以将其视为同步持久化,即每次发生的数据变化都会被立即记录到磁盘中。可以预见,这种方式在效率上是最低的。
至于无同步,无需多言,高效但是数据不会被持久化。
2). 由于该机制对日志文件的写入操作采用的是append模式,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。
然而如果我们本次操作只是写入了一半数据就出现了系统崩溃问题,不用担心,在Redis下一次启动之前,我们可以通过redis-check-aof工具来帮助我们解决数据一致性的问题。
3). 如果日志过大,Redis可以自动启用rewrite机制。
定期对AOF文件进行重写,以达到压缩的目的。
4). AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作。事实上,我们也可以通过该文件完成数据的重建。
1). AOF 文件比 RDB 文件大,且恢复速度慢,且启动效率低。
对于相同数量的数据集而言,AOF文件通常要大于RDB文件。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
2). 运行效率没有RDB高。
根据同步策略的不同,AOF在运行效率上往往会慢于RDB。总之,每秒同步策略的效率是比较高的,同步禁用策略的效率和RDB一样高效。
思考
1.RDB和 AOF两者如何选型?
Redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
主要从性能和数据可靠性两种情况考虑。如果两个都配了优先加载AOF。
数据可靠性aof
因为redis每写一次就会同步到aof文件,而RDB是定时的,所以AOF一致性更高。
就是看系统是愿意牺牲一些性能,换取更高的缓存一致性(aof)。
高性能
因为redis写了之后,不用立刻同步到RDB文件所以写的性能更高。且RDB故障恢复的更快。
还是愿意写操作频繁的时候,不启用备份来换取更高的性能,待手动运行save的时候,再做备份(rdb)。rdb这个就更有些 eventually consistent最终一致性的意思了。
四、 redis的过期策略与内存淘汰机制
1.redis的过期策略
分析:这个问题其实相当重要,到底redis有没用到家,这个问题就可以看出来。比如你redis只能存5G数据,可是你写了10G,那会删5G的数据。怎么删的,这个问题思考过么?还有,你的数据已经设置了过期时间,但是时间到了,内存占用率还是比较高,有思考过原因么?
回答:
redis采用的是定期删除+惰性删除策略。
主要从内存和CPU两个角度进行考虑,Redis中同时使用了惰性过期和定期过期两种过期策略。
1.为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
2.定期删除+惰性删除是如何工作的呢?
定期删除:redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
惰性删除:于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。当然读取的key对应的value也为空的。
该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。
键空间是指该Redis集群中保存的所有键。
3.采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
2.内存淘汰机制
在redis.conf中有一行配置
maxmemory-policy volatile-lru
该配置就是配内存淘汰策略的(什么,你没配过?好好反省一下自己)
redis默认的策略是volatile-lru。
1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
ps:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
思考
1.可以使用redis的过期机制来实现延迟队列吗?
通过上面的过期策略和淘汰机制发现,只有定时去访问key才能判断key是否过期来实现延迟队列。
参考文档
1.https://blog.csdn.net/JavaTeachers/article/details/108998121














 1837
1837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









