







字节码有啥用呢?知道了字节码之后你会看到更广阔的天地。作为一个只会敲代码的打工人,你可能只会写java代码,但是知其然而不知其所以然也。大人,时代已经变了,曾经修个电脑就能上班的年代已经一去不复返。如果卷不动别人,就要被人卷。
字节码概述
JVM与字节码
我们都知道java的出现是围绕着一个愿景的:
一个代码写一遍,到处运行,因为那个年代不同的os上的底层的指令集是可能不一样的,这样子可就为难程序员了,同样的逻辑要写好几便。我们it领域解决问题都可以用分层的方式解决,一层不够那就再加一层,TCP就是这么弄出来的。java领域呢,也抽象出来了一层,往下屏蔽os,往上就可以进行统一化了,真正的实现,write one time,run everywhere。
java领域被抽象出来的东西就是JVM,而和jvm本身对接的东西我们称为字节码。
而java代码是更高的一层抽象,这一层屏蔽语言本身。类似于scala,groove,kotlin都可以运行在jvm上,这就是屏蔽了语言的好处。那么我们理一理,java从书写到运行的整个流程。
开发的人根据java语言规范编写 .java代码 -> jdk自带指令javac 进行编译,生成jvm识别的.class文件 -> 运行 java 指令将刚刚写的代码跑起来,之后就是jvm的领域了。
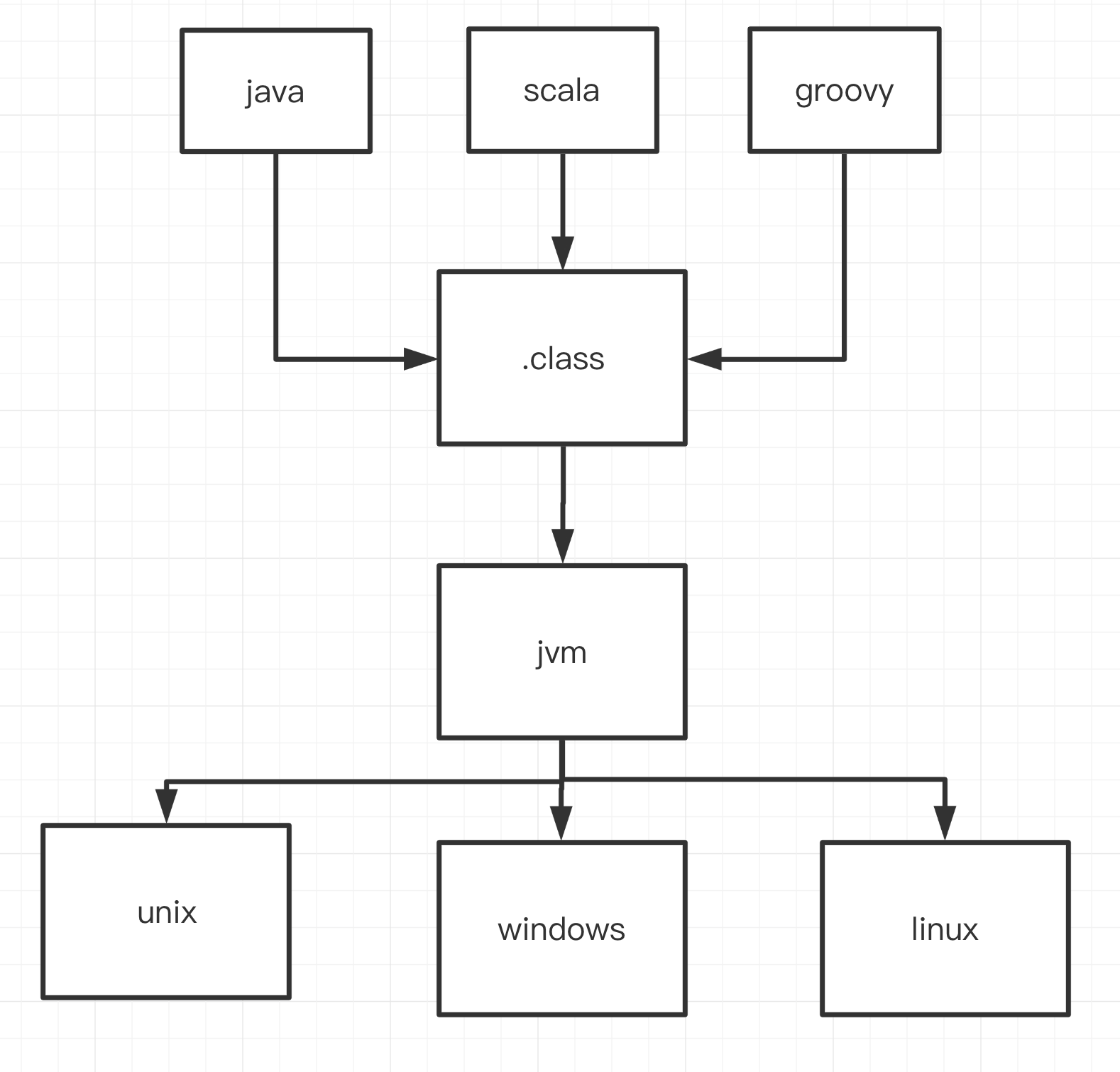
那么从上面的图中,我们就能看出来,理解字节码本身好处颇多。你可以知道你平时写java的背后都有些什么,有了这个基础之后,每行代码是怎么运行的,也是可以脑补出来的。同时思想上的补充也会弥补以前对jvm本身的认知。
以下是罗列出来的各项知识点:
- Class文件结构
- 从字节码角度看java代码
- 基本数据类型与运算符操作
- 流程控制
- 对象初始化
- 方法调用与多态原理
- 异常捕获与处理
- 并发关键字
- 字节码改写框架
- agent寄生插件
既然我们要深究字节码,那自然是需要知道字节码的结构的,在class文件结构设计上,你会学到很多思想
- 如何最小化表达大量信息
- 如何制造出一个稳定的,可支持扩展的文件格式
- 知道如何制造出可以尽可能向下兼容的字节码文件
之后我们就可以和java语言本身做一个对照,看看我们平时的java代码背后都发生了些什么,学的够深了,写起代码来就如有神灵加持。
字节码在一定程度上为开发的人开放了一个口子——在运行态动态修改字节码,完成一个又一个黑科技。skywalking就是这么来的,它相当于是在jvm最上面做了一个代理。背后用的就是agent插件,伴随着jvm运行而运行,因此叫做插件。插件的附着方式可以使用java运行指令携带,也可以使用socket连接,这就是arthas的连接方式。jdk里面的instrument包就是专门干这个事儿的。
因此,如果要玩这么一整套东西,就必须知道字节码指令本身,改写字节码可以借助与框架的力量,毕竟字节码的确复杂。那么这个改写字节码的框架的api就要尽可能熟悉。字节码改写框架又会有很多,挑一个自己熟悉的就可以。
逻辑上,如果要一个闭环,那么就需要知道class是怎么产生的,class文件是怎么在jvm里面运行的。
前者需要知道编译原理,再细节一点就是javac的编译原理,后者就更复杂了,需要知道jvm领域的大量知识进才能把这部分的知识产生一个闭环。
字节码的产生
当我们学习JVM,切入口会从JVM内部构造开始出发,知道JVM的一些行为来指导我们做各种优化。但是当不断深入,字节码的知识就逃不开。当学习完字节码之后,你会好奇字节码是怎么来的。兜兜转转又回到了最本质上的问题——java语言到底是怎么一步一步从低级语言成为当今IT里面的一束红花。
“编译原理”,大家应该都听过,it专业的基本课程之一。我不是it专业的,在不断学习过程中,我一直都想不明白很多事情,包括为什么我的鼠标移动一下,电脑上的鼠标小图标就会移动到我想移动到的位置上,java为什么那么写就能跑,我写成那样,我的机器就能明白我的意思。
编译原理概述
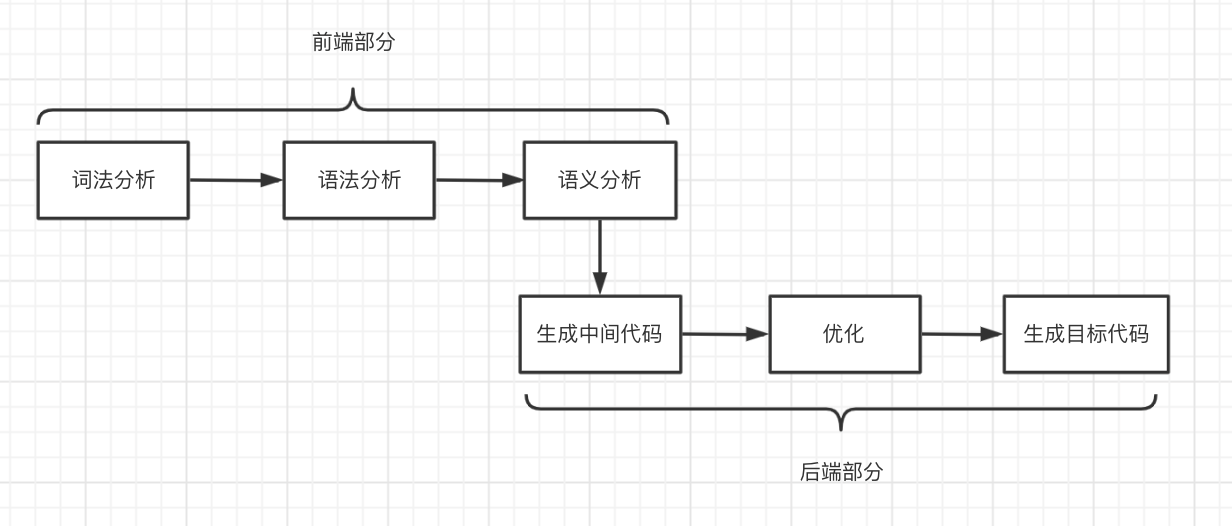
从上图上可以看到,编译原理可以大体上分为两个大部分:
- 前端部分
- 后端部分
前端部分搞定就已经可以制造出类似于python或者js的脚本语言,而后端部分就可以把语义树变成另外一种样子(更低级别的代码形式,例如机器码),然后在此基础上进行不断地优化优化优化,变成执行又快又稳的一种东西。
前端部分的三个概念在这里稍微描述一下,后端部分的步骤暂时就按字面意思理解就可以,问题不大,后面我们详细去说这个东西。
- 词法分析
指的是将你写的代码分割成各种有含义的片段,这种小片段称为token,执行完词法分析之后产生的是一连串的token,我们叫做token流。这是一个首尾相连的东西。例如,你的输入是age >= 45,那么产出就会是
(Identifier age) <-> (GE >= ) <-> (IntLiteral 45)
()括号里面的东西我们当成token,<->可以理解为链表的链,关联前后的token
- 语法分析
经过词法分析,我们得到token流,接下去语法分析就是将平铺开来的token转化为树状形式,树是按照语法规范走的,这棵树我们称为语法树,即AST树。例如你的输入是 2+3*5,输出就是一颗树一样的东西。这种结构,计算机很容易处理。
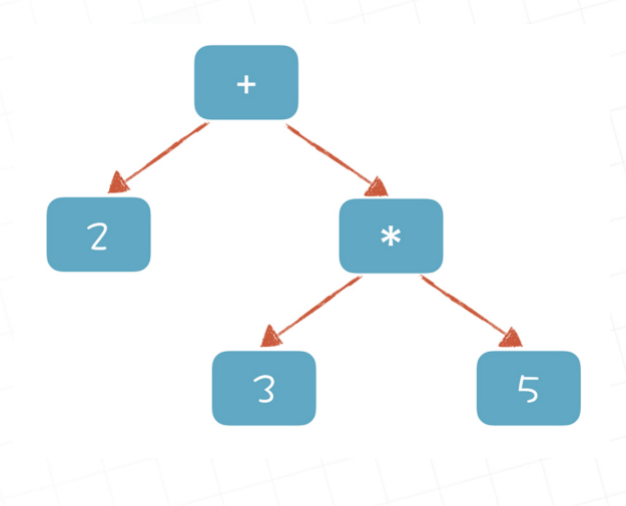
- 语义分析
语义分析里面的东西就多了,这是需要理解上下文的。比方说全局变量,引用变量进行计算,变量有效域之类的东西。当然,我们后面会详细描述。
Javac的编译过程
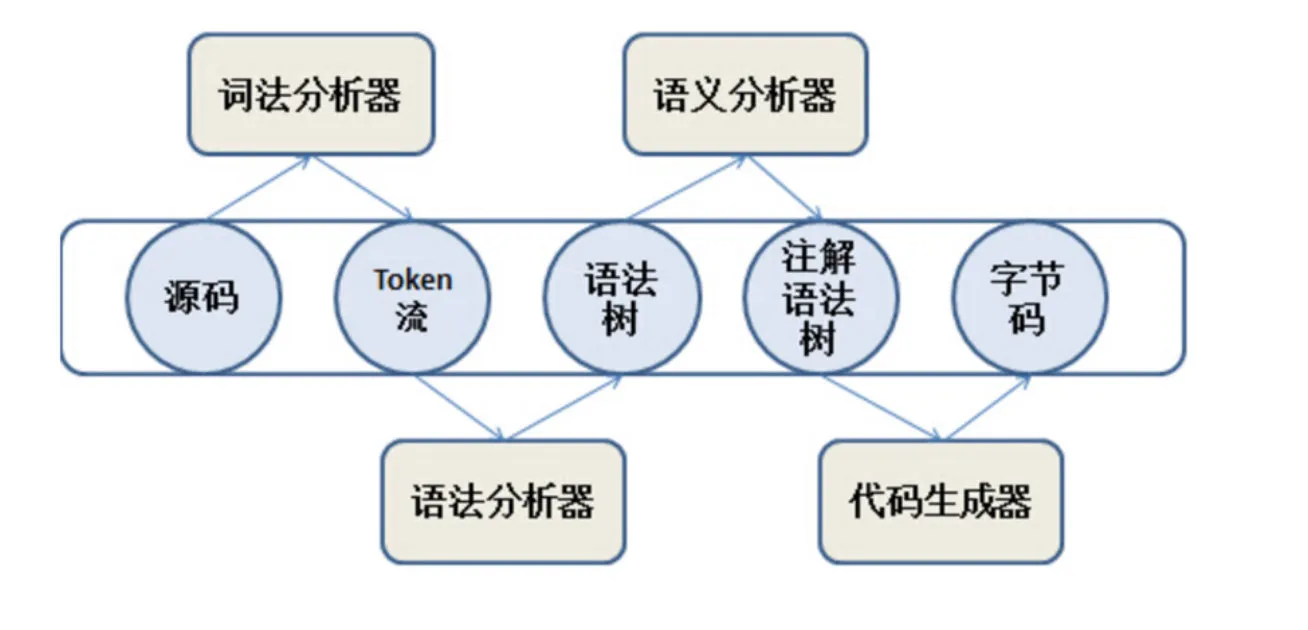
java编译过程需要经历4个组件
- 词法分析器 -> 生成token流
- 语法分析器 -> 生成语法树
- 语义分析器 -> 注解语法树
- 字节码生成器 -> 生成字节码
而对应的步骤事实上会很多:
- 词法分析: 把源代码中的字符(各个关键字、变量等)转为标记(Token)集合,单个字符的程序编写的最小单元,而token是编译过程的最小单元。
- 语法分析: 将标记(Token)集合构造为抽象语法树。语法树的每一个节点都代表代码中的一个语法结构(如包、类型、接口、修饰符等等)。
- 填充符号表:符号表是有一组符号地址和符号信息构成的表格。填充符号表的过程的出口是一个待处理列表,包含了每一个抽象语法树(和package-info.java)的顶级节点。
- 插入式注解处理器处理注解: 注解处理器可以增删改抽象语法树的任意元素。因此每当注解处理器对语法树进行修改时,都将重新执行1,2,3步,直到注解处理器不再对语法树进行修改为止。每一次的循环过程都称为一次Round。
- 语义分析:对语法树结构上正确的源程序进行上下文有关的审查。
- 标注检查:包括是否变量声明、变量和赋值类型是否匹配等、常量折叠。
- 数据和控制流分析:对程序上下文逻辑更进一步验证。包括变量使用前是否赋值、方法是否有返回值、异常是否被正确处理等。
- 解语法糖: 把高级语法(如:泛型、可变参数、拆箱装箱等)转为基础语法结构,虚拟机运行时不支持这些高级语法。
- 生成字节码:把语法树、符号表里的信息转为字节码写到磁盘,同时进行少量的代码添加和转换工作。
- 编译与反编译
- 什么是编译
- 前端编译
- 后端编译
- 什么是反编译
- jit优化
- 逃逸分析
- 栈上分配
- 标量替换
- 锁优化
- 编译工具
- 反编译工具
- 类加载机制
- classloader
- 类加载过程
- 双亲委派 如何破坏双亲委派
- 模块化 jboosmodule,osgi,jigsaw
编译与反编译相关指令
这部分我们要熟悉javac与javap指令
字节码的编译指令
回忆一波最开始学Java的时候,肯定书里会教你怎么在黑框框里执行你的"hello word",在此我们再详细地回顾一下HelloWorld是怎么玩的
- 我们写好的代码为xx.java格式
- 使用javac xx.java会在同级目录生成 xx.class文件
- 继续使用
java xx指令,就可以执行xx下的main函数。
以下是 javac 的编译指令参数
Usage: javac <options> <source files>
where possible options include:
-g Generate all debugging info
-g:none Generate no debugging info
-g:{lines,vars,source} Generate only some debugging info
-nowarn Generate no warnings
-verbose Output messages about what the compiler is doing
-deprecation Output source locations where deprecated APIs are used
-classpath <path> Specify where to find user class files and annotation processors
-cp <path> Specify where to find user class files and annotation processors
-sourcepath <path> Specify where to find input source files
-bootclasspath <path> Override location of bootstrap class files
-extdirs <dirs> Override location of installed extensions
-endorseddirs <dirs> Override location of endorsed standards path
-proc:{none,only} Control whether annotation processing and/or compilation is done.
-processor <class1>[,<class2>,<class3>...] Names of the annotation processors to run; bypasses default discovery process
-processorpath <path> Specify where to find annotation processors
-parameters Generate metadata for reflection on method parameters
-d <directory> Specify where to place generated class files
-s <directory> Specify where to place generated source files
-h <directory> Specify where to place generated native header files
-implicit:{none,class} Specify whether or not to generate class files for implicitly referenced files
-encoding <encoding> Specify character encoding used by source files
-source <release> Provide source compatibility with specified release
-target <release> Generate class files for specific VM version
-profile <profile> Check that API used is available in the specified profile
-version Version information
-help Print a synopsis of standard options
-Akey[=value] Options to pass to annotation processors
-X Print a synopsis of nonstandard options
-J<flag> Pass <flag> directly to the runtime system
-Werror Terminate compilation if warnings occur
@<filename> Read options and filenames from file
翻译过来就是:
-g 生成所有调试信息
-g:none 不生成任何调试信息
-g:{lines,vars,source} 只生成某些调试信息
-nowarn 不生成任何警告
-verbose 输出有关编译器正在执行的操作的消息
-deprecation 输出使用已过时的 API 的源位置
-classpath <路径> 指定查找用户类文件和注释处理程序的位置
-cp <路径> 指定查找用户类文件和注释处理程序的位置
-sourcepath <路径> 指定查找输入源文件的位置
-bootclasspath <路径> 覆盖引导类文件的位置
-extdirs <目录> 覆盖所安装扩展的位置
-endorseddirs <目录> 覆盖签名的标准路径的位置
-proc:{none,only} 控制是否执行注释处理和/或编译。
-processor[,,...] 要运行的注释处理程序的名称; 绕过默认的搜索进程
-processorpath <路径> 指定查找注释处理程序的位置
-d <目录> 指定放置生成的类文件的位置
-s <目录> 指定放置生成的源文件的位置
-implicit:{none,class} 指定是否为隐式引用文件生成类文件
-encoding <编码> 指定源文件使用的字符编码
-source <发行版> 提供与指定发行版的源兼容性
-target <发行版> 生成特定 VM 版本的类文件
-version 版本信息
-help 输出标准选项的提要
-A关键字[=值] 传递给注释处理程序的选项
-X 输出非标准选项的提要
-J<标记> 直接将 <标记> 传递给运行时系统
-Werror 出现警告时终止编译
@<文件名> 从文件读取选项和文件名
-g 需要注意,当在后面使用javap反编译的时候,使用javap -l 可以输出方法的变量表table,如果不使用-g指令编译,将得不到方法的变量列表
接下来仔细描述一下javac的一些重要参数的使用方法
-implicit选项
-implicit选项用来指定是否为隐式引用的文件生成字节码文件,默认生成;选项支持:
1、none:不为隐式引用的文件生成字节码文件;
2、class:为隐式引用的文件生成字节码文件,默认选项;
public class Main {
public static void main(String[] args) {
A a = new A();
a.func();
}
}
public class A {
public void func() {
System.out.println("Test Implicit.");
}
}
执行情况如下:
> javac Main.java # 默认生成A的字节码文件
> javac -implicit:none Main.java # 不会生成A的字节码文件
-g 选项
用于生成调试信息,调试信息有-bootclasspathlines、vars和source;
lines:字节码文件中对应源码的行号;字节码调试打断点时,无行号信息,无法打断点。
vars:字节码文件中对应源码的变量信息;字节码调试时,无该信息,无法查看变量信息。
source:字节码文件对应的源文件名,针对类似非public修饰类场景,举例如下:Main.java编译后生成两个字节码文件Main.class && Test.class,Test.class隶属于Main.java,而不是Test.java
| 不指定-g选项 | 生成lines和source调试信息 |
|---|---|
| -g | 生成lines、vars、source调试信息 |
| -g:none | 不生成任何调试信息 |
| -g:{lines,vars,source} | 指定生成哪些调试信息,可以指定多个用逗号隔开; |
-source/-target选项
-source:
用于指定编译源码时使用的JDK版本,例如:javac -source 1.7 TestSource.java 指定使用JDK1.4编译TestSource.java,
但是TestSource.java中使用了lamba表达式,因此编译报错,需要指定JDK版本为1.8;
-target:
用于指定生成的字节码文件要运行在哪个JDK版本,如指定target版本为1.8,则运行字节码文件的JDK版本必须大于等于1.8
编译时同时使用:
运行使用的JDK版本必须大于等于编译使用的JDK版本,即-target指定的版本必须大于等于-source,否则编译会有如下错误:
javac: 源发行版 1.8 需要目标发行版 1.8
public class TestSource {
public static void main(String[] args) {
List<String> stringList = Arrays.stream(new String[]{"hello", "hi", "how are you", "what?", "hi"})
.distinct()
.filter(word -> word.startsWith("h"))
.sorted(Comparator.reverseOrder())
.collect(Collectors.toList());
System.out.println(stringList);
}
}
-d/-sourcepath/-classpath选项
-d选项: 指定编译生成字节码文件路径
-classpath选项: 指定依赖类路径,这里的依赖类为字节码文件;用于指导编译器在编译时按照指定路径查找依赖类;可以指定多个classpath,linux用:分隔,windows用;分隔
-sourcepath选项: 指定依赖类源文件路径,并且要求源文件除CLASSPATH依赖外,无其他依赖;如果同时找到了源文件和字节码文件,两者一致,以字节码文件为准;不一致,以源文件为准,并编译源文件
-bootclasspath/-extdirs选项
这两选项是几乎不需要使用的选项,两个选项的作用如下:
-bootclasspath: 用来覆盖引导类文件路径,引导类文件路径为: jdk1.8.0_212\jre\lib\rt.jar
-extdirs: 用来覆盖扩展类文件路径,扩展文件路径为: jdk1.8.0_212\jre\lib\ext\
-Xlint选项
Java编译选项有标准选项和非标准选项之分,标准选项指的是当前版本支持的选项,后续版本也一定支持;非标准选项指的是当前版本支持的选项,后续版本不一定支持。
-Xlint选项用来启用建议的告警,有如下选项:
Java编译选项有标准选项和非标准选项之分,标准选项指的是当前版本支持的选项,后续版本也一定支持;非标准选项指的是当前版本支持的选项,后续版本不一定支持。
非标准选项是以-X开头的选项,但是-X选项则是一个标准选项,用来显示-X选项的帮助信息;有特例:-J选项
1、-Xlint
启用所有编译建议的警告;该选项等同于-Xlint:all,相反禁用所有警告的选项为:-Xlint:none;-Xlint:none并非不显示任何警告,而是会给出存在哪些类型的警告并建议使用-Xlint对应的选项
2、-Xlint:unchecked
启用未经检查的转换警告,JDK1.5泛型引入的,源码中的编译警告即属于该种类型
3、-Xlint:finally
finally语句无法正常结束的警告
4、-Xlint:serial
需要序列化的类,未指定序列化ID的警告
5、-Xlint:fallthrouth
switch case语句中,第一个case语句无break
-encoding指令
指定编译时编码格式,中文windows默认GBK编码,java文件一般使用UTF-8格式,因此常用命令为javac -encoding UTF-8 XXX.java
-verbose
输出编译时的详细信息,包括:classpath、加载的类文件信息。
@<文件名>
用来通经文件指定编译多个java源文件;比如,有如下的几个java源文件,我们希望编译这些源文件,一个一个编译?当然不,
我们可以通过将编译选项和源文件名以行为单位写入文件,然后通过-@标签编译。
javac @compile.cfg
-j <标记>
传递一些信息给 Java Launcher,例如
javac -J -Xms48m Xxx.java
字节码分析工具
javap
JDK 提供了专门用来分析类文件的工具:javap
其中-c -v -l -p -s是最常用的
Usage: javap <options> <classes>
where possible options include:
-help --help -? Print this usage message
-version Version information
-v -verbose Print additional information
-l Print line number and local variable tables
-public Show only public classes and members
-protected Show protected/public classes and members
-package Show package/protected/public classes
and members (default)
-p -private Show all classes and members
-c Disassemble the code
-s Print internal type signatures
-sysinfo Show system info (path, size, date, MD5 hash)
of class being processed
-constants Show final constants
-classpath <path> Specify where to find user class files
-cp <path> Specify where to find user class files
-bootclasspath <path> Override location of bootstrap class files
一般常用的是-v -l -c三个选项。
javap -v classxx,不仅会输出行号、本地变量表信息、反编译汇编代码,还会输出当前类用到的常量池等信息。
javap -l 会输出行号和本地变量表信息。
javap -c 会对当前class字节码进行反编译生成汇编代码。
javap -p 默认情况下,javap 会显示访问权限为 public、protected 和默认(包级 protected)级别的方法,加上 -p 选项以后可以显示 private 方法和字段
javap -v 参数的输出更多详细的信息,比如栈大小、方法参数的个数。
javap -s 可以输出签名的类型描述符。我们可以看下 xx.java 所有的方法签名
AsmTools
我们知道直接修改.class文件是很麻烦的,虽然有一些图形界面的工具,但还是很麻烦。在OpenJDK里有一个AsmTools项目,用来生成正确的或者不正确的java .class文件,主要用来测试和验证。AsmTools引入了两种表示.class文件的语法:
- JASM
用类似java本身的语法来定义类和函数,字节码指令则很像传统的汇编。 - JCOD
整个.class用容器的方式来表示,可以很清楚表示类文件的结构。
查看JASM语法结果
java -jar asmtools.jar jdis Test.class
查看JCOD语法结果
java -jar asmtools.jar jdec Test.class
从JASM/JCOD语法文件生成类文件
因为是等价表达,可以从JASM生成.class文件:
java -jar asmtools.jar jasm Test.jasm
同样可以从JCOD生成.class文件:
java -jar asmtools.jar jcoder Test.jasm
更多使用方法参考:
- https://wiki.openjdk.java.net/display/CodeTools/Chapter+2#Chapter2-Jasm.1
- https://wiki.openjdk.java.net/display/CodeTools/asmtools
idea插件
在插件商场里面找到jclassLib并安装show Bytecode With JclassLib,找到任意一个.class,然后点开show 的菜单。
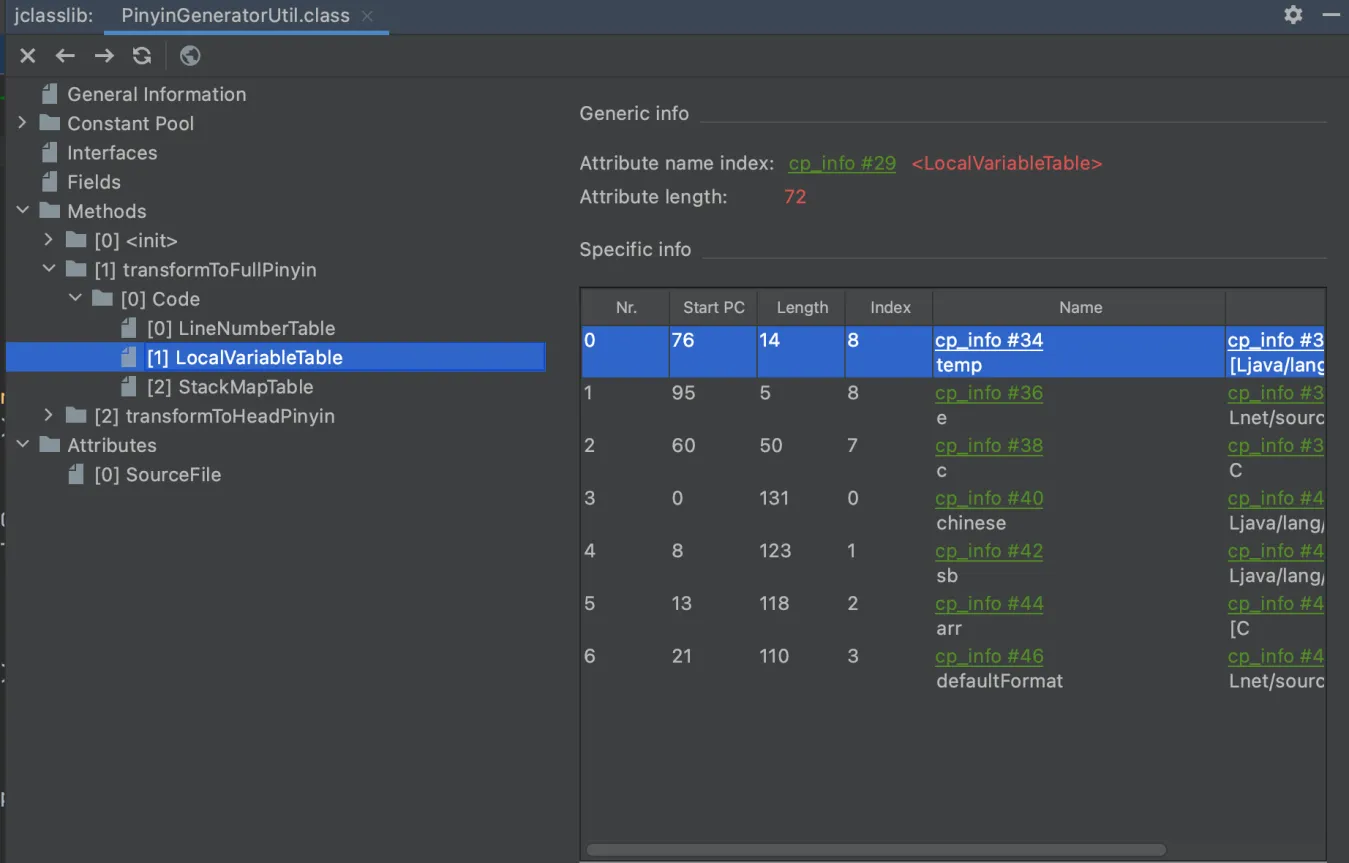
你就可以看到这个class文件的数据结构了,基本上你能想到的,这个插件都能帮你捞出来
jar指令
打包.class文件
jar -cvf Test.jar -C classes/ .
这个命令将会把classes下的所有文件(包括.class和文件夹等)打包为Test.jar文件。
上篇博客中,介绍了参数-C的意义:-C 更改为指定的目录并包含其中的文件,如果有任何目录文件, 则对其进行递归处理。它相当于使用 cd 命令转指定目录下。
注意后面的".“的用法,jar可以递归的打包文件夹,”."表示是当前文件夹。如果执行命令“jar -cvf Test.jar .”,表示将当前目录下的所有文件及文件夹打包。所以上面的命令的意思就是“将classes下的所有文件打包为Test.jar”。
生成可以运行的jar包
java -cp Test.jar Main
通过上面的命令就可以执行Test.jar中的Main.class。其中,cp指定了jar文件的位置。
需要指定jar包的应用程序入口点,用-e选项
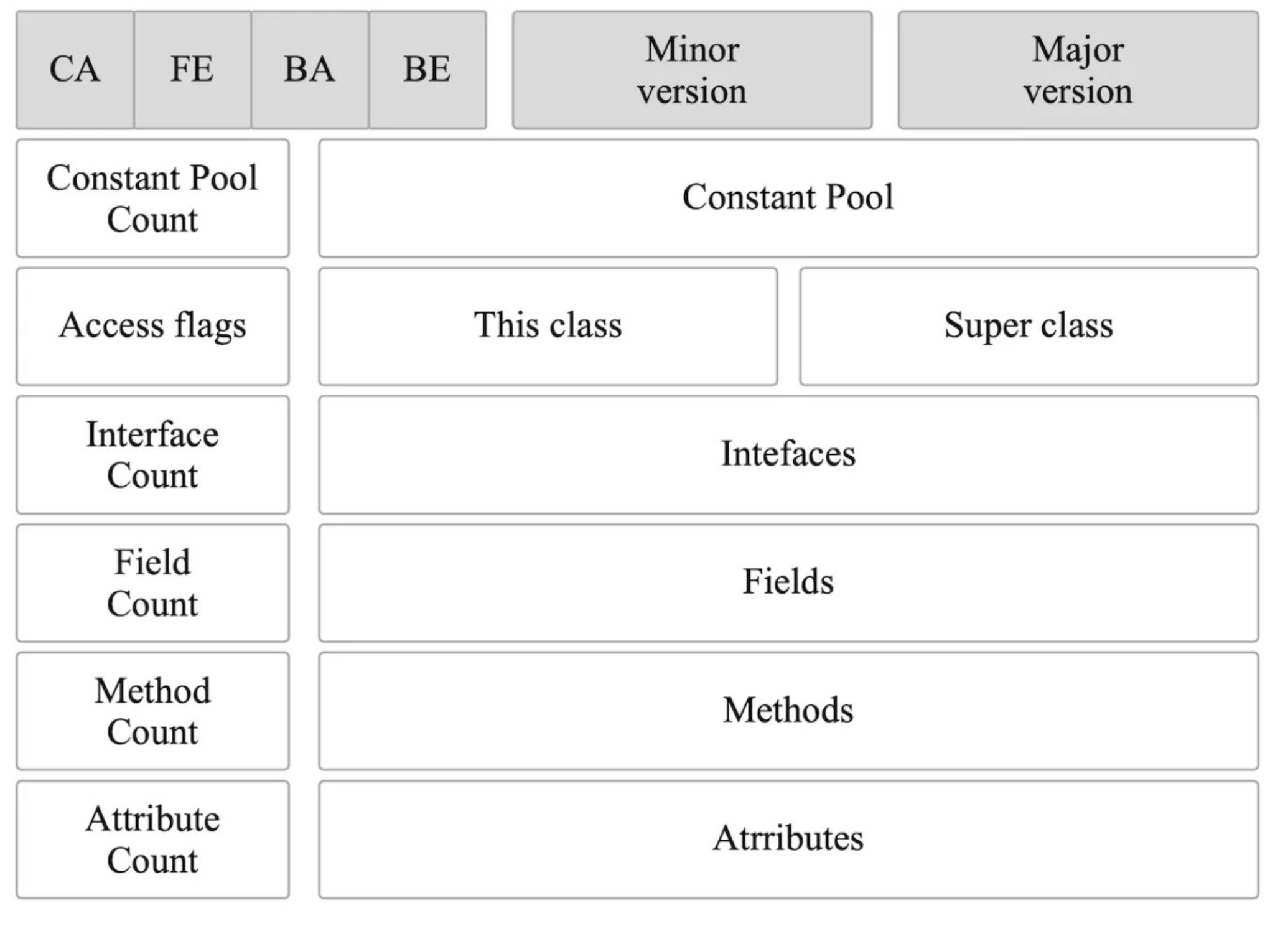
Class 文件结构
先整体看下class的文件结构
ClassFile {
u4 magic; // 魔数(Magic Number)
u2 minor_version; // 版本号(Minor&Major Version)
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1]; // 常量池(Constant Pool)
u2 access_flags; // 类访问标记(Access Flags)
u2 this_class; // 类索引(This Class)
u2 super_class; // 超类索引(Super Class)
u2 interfaces_count;
u2 interfaces[interfaces_count]; // 接口表索引(Interfaces)
u2 fields_count;
field_info fields[fields_count]; // 字段表(Fields)
u2 methods_count;
method_info methods[methods_count]; // 方法表(Methods)
u2 attributes_count;
attribute_info attributes[attributes_count]; // 属性表(Attributes)
}
Java虚拟机规定用u1、u2、u4三种数据结构来表示1、2、4字节无符号整数。上面的结构是采用类似c结构体的形式表达。
魔数
先造一个最简单的代码:
public class Hello {
public static void main(String[] args) {
System.out.println("Hello, World");
}
}
生成的class文件用工具打开是这样的(本身是一个二进制,里面都是01,用工具打开才会变成这个样子)
00000000: cafe babe 0000 0034 001d 0a00 0600 0f09 .......4........
00000010: 0010 0011 0800 120a 0013 0014 0700 1507 ................
00000020: 0016 0100 063c 696e 6974 3e01 0003 2829 .....<init>...()
00000030: 5601 0004 436f 6465 0100 0f4c 696e 654e V...Code...LineN
00000040: 756d 6265 7254 6162 6c65 0100 046d 6169 umberTable...mai
00000050: 6e01 0016 285b 4c6a 6176 612f 6c61 6e67 n...([Ljava/lang
00000060: 2f53 7472 696e 673b 2956 0100 0a53 6f75 /String;)V...Sou
00000070: 7263 6546 696c 6501 000a 4865 6c6c 6f2e rceFile...Hello.
00000080: 6a61 7661 0c00 0700 0807 0017 0c00 1800 java............
00000090: 1901 000c 4865 6c6c 6f2c 2057 6f72 6c64 ....Hello, World
000000a0: 0700 1a0c 001b 001c 0100 0548 656c 6c6f ...........Hello
000000b0: 0100 106a 6176 612f 6c61 6e67 2f4f 626a ...java/lang/Obj
000000c0: 6563 7401 0010 6a61 7661 2f6c 616e 672f ect...java/lang/
000000d0: 5379 7374 656d 0100 036f 7574 0100 154c System...out...L
000000e0: 6a61 7661 2f69 6f2f 5072 696e 7453 7472 java/io/PrintStr
000000f0: 6561 6d3b 0100 136a 6176 612f 696f 2f50 eam;...java/io/P
00000100: 7269 6e74 5374 7265 616d 0100 0770 7269 rintStream...pri
00000110: 6e74 6c6e 0100 1528 4c6a 6176 612f 6c61 ntln...(Ljava/la
00000120: 6e67 2f53 7472 696e 673b 2956 0021 0005 ng/String;)V.!..
00000130: 0006 0000 0000 0002 0001 0007 0008 0001 ................
00000140: 0009 0000 001d 0001 0001 0000 0005 2ab7 ..............*.
00000150: 0001 b100 0000 0100 0a00 0000 0600 0100 ................
00000160: 0000 0200 0900 0b00 0c00 0100 0900 0000 ................
00000170: 2500 0200 0100 0000 09b2 0002 1203 b600 %...............
00000180: 04b1 0000 0001 000a 0000 000a 0002 0000 ................
00000190: 0005 0008 0006 0001 000d 0000 0002 000e ................
可以看到,二进制的最开始就是 ca fe ba be,这四个字节相当于被认为是java代码编译之后的标记。不同种的文件都会有不同的标记,例如png文件,JPEG文件等等。
意味着文件如果不是以ca fe ba be开头的,将不被jvm承认。
主版本号与副版本号
依旧参考Hello.java反编译出来的二进制:
00000000: cafe babe 0000 0034 001d 0a00 0600 0f09 .......4........
00000010: 0010 0011 0800 120a 0013 0014 0700 1507 ................
00000020: 0016 0100 063c 696e 6974 3e01 0003 2829 .....<init>...()
00000030: 5601 0004 436f 6465 0100 0f4c 696e 654e V...Code...LineN
00000040: 756d 6265 7254 6162 6c65 0100 046d 6169 umberTable...mai
00000050: 6e01 0016 285b 4c6a 6176 612f 6c61 6e67 n...([Ljava/lang
00000060: 2f53 7472 696e 673b 2956 0100 0a53 6f75 /String;)V...Sou
00000070: 7263 6546 696c 6501 000a 4865 6c6c 6f2e rceFile...Hello.
00000080: 6a61 7661 0c00 0700 0807 0017 0c00 1800 java............
00000090: 1901 000c 4865 6c6c 6f2c 2057 6f72 6c64 ....Hello, World
000000a0: 0700 1a0c 001b 001c 0100 0548 656c 6c6f ...........Hello
000000b0: 0100 106a 6176 612f 6c61 6e67 2f4f 626a ...java/lang/Obj
000000c0: 6563 7401 0010 6a61 7661 2f6c 616e 672f ect...java/lang/
000000d0: 5379 7374 656d 0100 036f 7574 0100 154c System...out...L
000000e0: 6a61 7661 2f69 6f2f 5072 696e 7453 7472 java/io/PrintStr
000000f0: 6561 6d3b 0100 136a 6176 612f 696f 2f50 eam;...java/io/P
00000100: 7269 6e74 5374 7265 616d 0100 0770 7269 rintStream...pri
00000110: 6e74 6c6e 0100 1528 4c6a 6176 612f 6c61 ntln...(Ljava/la
00000120: 6e67 2f53 7472 696e 673b 2956 0021 0005 ng/String;)V.!..
00000130: 0006 0000 0000 0002 0001 0007 0008 0001 ................
00000140: 0009 0000 001d 0001 0001 0000 0005 2ab7 ..............*.
00000150: 0001 b100 0000 0100 0a00 0000 0600 0100 ................
00000160: 0000 0200 0900 0b00 0c00 0100 0900 0000 ................
00000170: 2500 0200 0100 0000 09b2 0002 1203 b600 %...............
00000180: 04b1 0000 0001 000a 0000 000a 0002 0000 ................
00000190: 0005 0008 0006 0001 000d 0000 0002 000e ................
紧跟着ca fe ba be的四个字节是,00 00 00 34
00 00表示副版本号(Minor Version),00 34(值是52)表示主版本号(Major Version)
| Java版本 | Major version |
|---|---|
| Java1.4 | 48 |
| Java5 | 59 |
| Java6 | 50 |
| Java7 | 51 |
| Java8 | 52 |
| Java9 | 53 |
JVM运行时向下兼容的,意味着比方1.8的jdk,一看到主版本是高于52的,就直接报出异常来
常量池
常量池是一个最复杂最复杂的数据结构了,还是一样的套路,我们制造一个代码出来
public class Hello1 {
public final boolean bool = true; // 1(0x01)
public final char c = 'A'; // 65(0x41)
public final byte b = 66; // 66(0x42)
public final short s = 67; // 67(0x43)
public final int i = 68; // 68(0x44)
public final long l = Long.MAX_VALUE;
public final double d = Double.MAX_VALUE;
public static void main(String[] args) {
System.out.println("Hello, World");
}
}
编译出来之后的二进制文件是
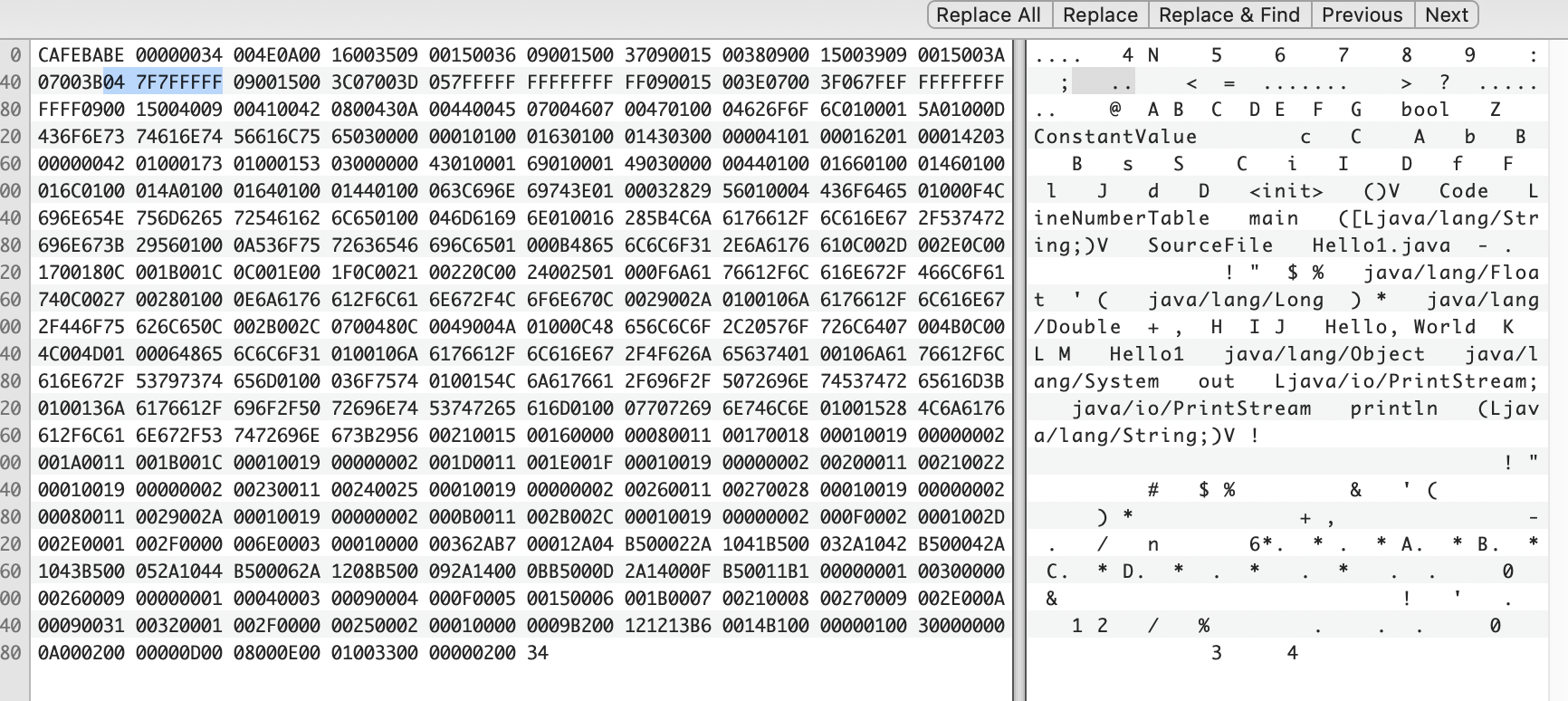
00000000: cafe babe 0000 0034 004e 0a00 1600 3509 .......4.N....5.
00000010: 0015 0036 0900 1500 3709 0015 0038 0900 ...6....7....8..
00000020: 1500 3909 0015 003a 0700 3b04 7f7f ffff ..9....:..;.....
00000030: 0900 1500 3c07 003d 057f ffff ffff ffff ....<..=........
00000040: ff09 0015 003e 0700 3f06 7fef ffff ffff .....>..?.......
00000050: ffff 0900 1500 4009 0041 0042 0800 430a ......@..A.B..C.
00000060: 0044 0045 0700 4607 0047 0100 0462 6f6f .D.E..F..G...boo
00000070: 6c01 0001 5a01 000d 436f 6e73 7461 6e74 l...Z...Constant
00000080: 5661 6c75 6503 0000 0001 0100 0163 0100 Value........c..
00000090: 0143 0300 0000 4101 0001 6201 0001 4203 .C....A...b...B.
000000a0: 0000 0042 0100 0173 0100 0153 0300 0000 ...B...s...S....
000000b0: 4301 0001 6901 0001 4903 0000 0044 0100 C...i...I....D..
000000c0: 0166 0100 0146 0100 016c 0100 014a 0100 .f...F...l...J..
000000d0: 0164 0100 0144 0100 063c 696e 6974 3e01 .d...D...<init>.
000000e0: 0003 2829 5601 0004 436f 6465 0100 0f4c ..()V...Code...L
000000f0: 696e 654e 756d 6265 7254 6162 6c65 0100 ineNumberTable..
00000100: 046d 6169 6e01 0016 285b 4c6a 6176 612f .main...([Ljava/
00000110: 6c61 6e67 2f53 7472 696e 673b 2956 0100 lang/String;)V..
00000120: 0a53 6f75 7263 6546 696c 6501 000b 4865 .SourceFile...He
00000130: 6c6c 6f31 2e6a 6176 610c 002d 002e 0c00 llo1.java..-....
00000140: 1700 180c 001b 001c 0c00 1e00 1f0c 0021 ...............!
00000150: 0022 0c00 2400 2501 000f 6a61 7661 2f6c ."..$.%...java/l
00000160: 616e 672f 466c 6f61 740c 0027 0028 0100 ang/Float..'.(..
00000170: 0e6a 6176 612f 6c61 6e67 2f4c 6f6e 670c .java/lang/Long.
00000180: 0029 002a 0100 106a 6176 612f 6c61 6e67 .).*...java/lang
00000190: 2f44 6f75 626c 650c 002b 002c 0700 480c /Double..+.,..H.
000001a0: 0049 004a 0100 0c48 656c 6c6f 2c20 576f .I.J...Hello, Wo
000001b0: 726c 6407 004b 0c00 4c00 4d01 0006 4865 rld..K..L.M...He
000001c0: 6c6c 6f31 0100 106a 6176 612f 6c61 6e67 llo1...java/lang
000001d0: 2f4f 626a 6563 7401 0010 6a61 7661 2f6c /Object...java/l
000001e0: 616e 672f 5379 7374 656d 0100 036f 7574 ang/System...out
000001f0: 0100 154c 6a61 7661 2f69 6f2f 5072 696e ...Ljava/io/Prin
00000200: 7453 7472 6561 6d3b 0100 136a 6176 612f tStream;...java/
00000210: 696f 2f50 7269 6e74 5374 7265 616d 0100 io/PrintStream..
00000220: 0770 7269 6e74 6c6e 0100 1528 4c6a 6176 .println...(Ljav
00000230: 612f 6c61 6e67 2f53 7472 696e 673b 2956 a/lang/String;)V
00000240: 0021 0015 0016 0000 0008 0011 0017 0018 .!..............
00000250: 0001 0019 0000 0002 001a 0011 001b 001c ................
00000260: 0001 0019 0000 0002 001d 0011 001e 001f ................
00000270: 0001 0019 0000 0002 0020 0011 0021 0022 ......... ...!."
00000280: 0001 0019 0000 0002 0023 0011 0024 0025 .........#...$.%
00000290: 0001 0019 0000 0002 0026 0011 0027 0028 .........&...'.(
000002a0: 0001 0019 0000 0002 0008 0011 0029 002a .............).*
000002b0: 0001 0019 0000 0002 000b 0011 002b 002c .............+.,
000002c0: 0001 0019 0000 0002 000f 0002 0001 002d ...............-
000002d0: 002e 0001 002f 0000 006e 0003 0001 0000 ...../...n......
000002e0: 0036 2ab7 0001 2a04 b500 022a 1041 b500 .6*...*....*.A..
000002f0: 032a 1042 b500 042a 1043 b500 052a 1044 .*.B...*.C...*.D
00000300: b500 062a 1208 b500 092a 1400 0bb5 000d ...*.....*......
00000310: 2a14 000f b500 11b1 0000 0001 0030 0000 *............0..
00000320: 0026 0009 0000 0001 0004 0003 0009 0004 .&..............
00000330: 000f 0005 0015 0006 001b 0007 0021 0008 .............!..
00000340: 0027 0009 002e 000a 0009 0031 0032 0001 .'.........1.2..
00000350: 002f 0000 0025 0002 0001 0000 0009 b200 ./...%..........
00000360: 1212 13b6 0014 b100 0000 0100 3000 0000 ............0...
00000370: 0a00 0200 0000 0d00 0800 0e00 0100 3300 ..............3.
00000380: 0000 0200 34 ....4
二进制看上去就复杂很多。
常量池的基本结构是这个样子的
struct {
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
}
意味着紧跟着主版本号的两个字节表达了常量池长度是多少,查看二进制,可以看到,两个字节是00 4e,意味着我们当前的class文件的constant_pool_count=78,但是真正的常量池条目录数最大是77。
这里有两个含义:
- 为什么是77
- 为什么最大是77
因为常量池是1开始的,0位有特殊含义,表达什么都没有的状态。因此总数是77,那为什么最大是77呢?因为类似long,double事实上是占用两个常量池位置的,因此真正的常量池条目数是<= 77的
而cp_info的结构可以用下面的伪代码表达
cp_info {
u1 tag;
u1 info[];
}
tag指的是常量条目的类型,我在这里列一下:
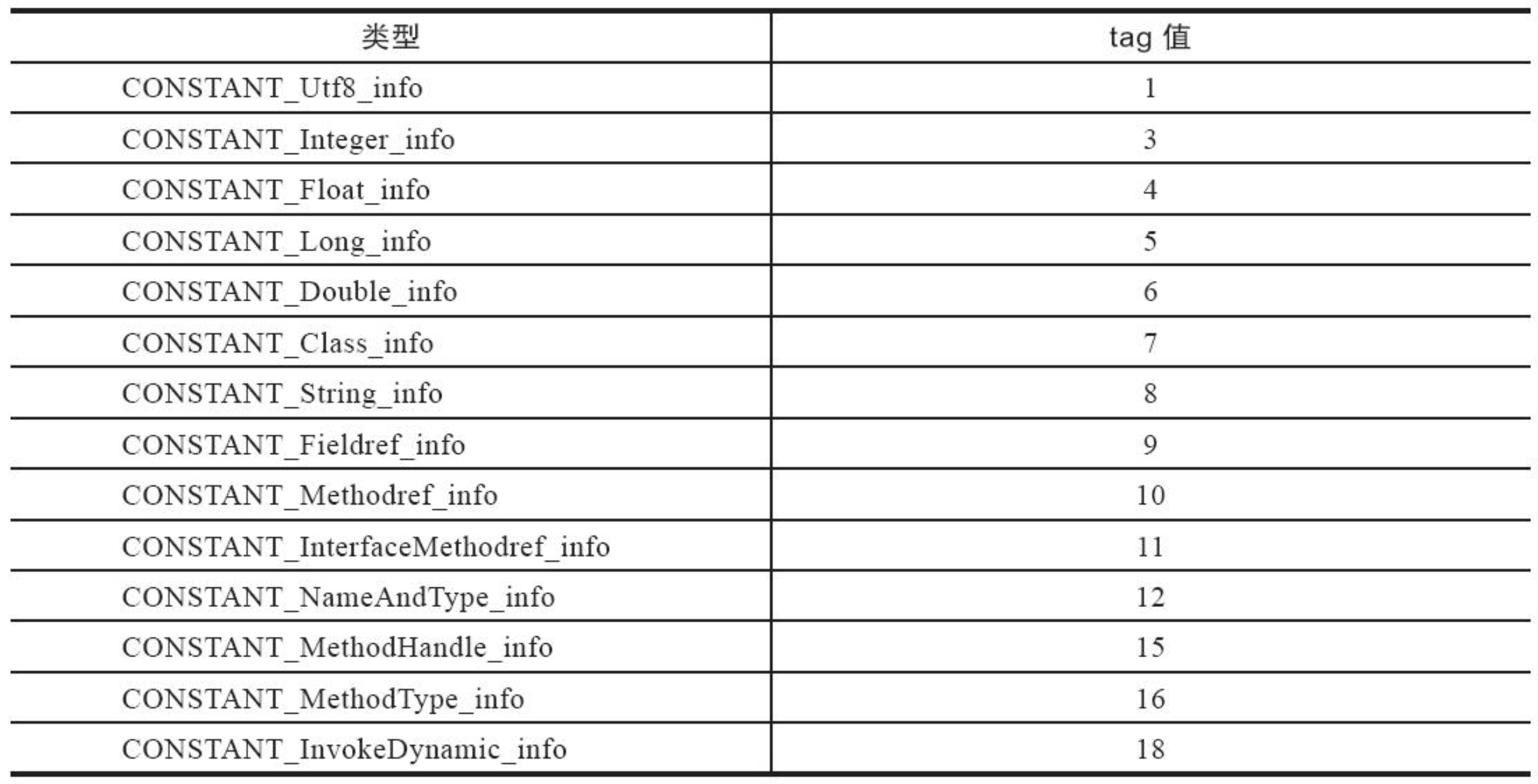
不同的类型会有不同的tag值,u1 info[] 相当于和这个tag值绑定,有些tag值固定是2个字节,那么在解析class文件的时候就自动往后扣两个字节。接下来,我们分析一下所有的数据类型tag。
数值类型的常量
我们java领域内,所拥有的数值类型有 bool,byte, short, char, int, long, float, long
而在上图中可以看到,bool,byte, short, char类型是没有对应的tag的,那是因为在常量池里面统一使用int操作了。
2.3.1.1 CONSTANT_Integer_info类型
CONSTANT_Integer_info 结构可以使用下面的结构表示
CONSTANT_Integer_info {
u1 tag;
u4 bytes;
}
因为这里已经确定了是CONSTANT_Integer_info,所以这里的tag是03,后面四个字节表达数值本身。
那么人肉翻译一下代码里面定义的常量:
public final boolean bool = true; // 1(0x01)
public final char c = 'A'; // 65(0x41)
public final byte b = 66; // 66(0x42)
public final short s = 67; // 67(0x43)
public final int i = 68; // 68(0x44)
bool = 03 00 00 00 01
c = 03 00 00 00 41
b = 03 00 00 00 42
s = 03 00 00 00 43
i = 03 00 00 00 44
使用hex Fiend软件圈选出来

2.3.1.2 CONSTANT_Float_info类型
CONSTANT_Float_info类型的数据结构和CONSTANT_Integer_info数据是差不多的
CONSTANT_Float_info {
u1 tag;
u4 bytes;
}
意味着,tag值是4,然后后面跟着4个字节表达数据,即 04 7F 7F FF FF
2.3.1.3 CONSTANT_Long_info类型
以下是 CONSTANT_Long_info数据类型
CONSTANT_Long_info {
u1 tag;
u4 high_bytes;
u4 low_bytes;
}
可以看到数据本身会被切分为两个四字节存储,分别叫高位值与低位值
2.3.1.4 CONSTANT_Double_info类型
以下是 CONSTANT_Double_info 类型
CONSTANT_Double_info {
u1 tag;
u4 high_bytes;
u4 low_bytes;
}
可以看到和CONSTANT_Long_info的存储结构一毛一样,只不过存储的数据本身格式会有很大区别。
字符串类型常量
这里将会涉及到两种类型的数据CONSTANT_String_info与个CONSTANT_Utf8_info
CONSTANT_Utf8_info存储了字符串真正的内容,而CONSTANT_String_info仅仅包含一个指向常量池中CONSTANT_Utf8_info常量类型的索引。
还是一样的套路,我们制造出用于说明的java代码
public class Hello2{
public final String hello = "hello";
public final String x = "\0";
public final String y = "\uD83D\uDE02";// emoji 😂
public static void main(String[] args) {
System.out.println("Hello, World");
}
}
反编译出来的数据为
00000000: cafe babe 0000 0034 002d 0a00 0c00 1a08 .......4.-......
00000010: 000d 0900 0b00 1b08 001c 0900 0b00 1d08 ................
00000020: 001e 0900 0b00 1f09 0020 0021 0800 220a ......... .!..".
00000030: 0023 0024 0700 2507 0026 0100 0568 656c .#.$..%..&...hel
00000040: 6c6f 0100 124c 6a61 7661 2f6c 616e 672f lo...Ljava/lang/
00000050: 5374 7269 6e67 3b01 000d 436f 6e73 7461 String;...Consta
00000060: 6e74 5661 6c75 6501 0001 7801 0001 7901 ntValue...x...y.
00000070: 0006 3c69 6e69 743e 0100 0328 2956 0100 ..<init>...()V..
00000080: 0443 6f64 6501 000f 4c69 6e65 4e75 6d62 .Code...LineNumb
00000090: 6572 5461 626c 6501 0004 6d61 696e 0100 erTable...main..
000000a0: 1628 5b4c 6a61 7661 2f6c 616e 672f 5374 .([Ljava/lang/St
000000b0: 7269 6e67 3b29 5601 000a 536f 7572 6365 ring;)V...Source
000000c0: 4669 6c65 0100 0b48 656c 6c6f 322e 6a61 File...Hello2.ja
000000d0: 7661 0c00 1200 130c 000d 000e 0100 02c0 va..............
000000e0: 800c 0010 000e 0100 06ed a0bd edb8 820c ................
000000f0: 0011 000e 0700 270c 0028 0029 0100 0c48 ......'..(.)...H
00000100: 656c 6c6f 2c20 576f 726c 6407 002a 0c00 ello, World..*..
00000110: 2b00 2c01 0006 4865 6c6c 6f32 0100 106a +.,...Hello2...j
00000120: 6176 612f 6c61 6e67 2f4f 626a 6563 7401 ava/lang/Object.
00000130: 0010 6a61 7661 2f6c 616e 672f 5379 7374 ..java/lang/Syst
00000140: 656d 0100 036f 7574 0100 154c 6a61 7661 em...out...Ljava
00000150: 2f69 6f2f 5072 696e 7453 7472 6561 6d3b /io/PrintStream;
00000160: 0100 136a 6176 612f 696f 2f50 7269 6e74 ...java/io/Print
00000170: 5374 7265 616d 0100 0770 7269 6e74 6c6e Stream...println
00000180: 0100 1528 4c6a 6176 612f 6c61 6e67 2f53 ...(Ljava/lang/S
00000190: 7472 696e 673b 2956 0021 000b 000c 0000 tring;)V.!......
000001a0: 0003 0011 000d 000e 0001 000f 0000 0002 ................
000001b0: 0002 0011 0010 000e 0001 000f 0000 0002 ................
000001c0: 0004 0011 0011 000e 0001 000f 0000 0002 ................
000001d0: 0006 0002 0001 0012 0013 0001 0014 0000 ................
000001e0: 003b 0002 0001 0000 0017 2ab7 0001 2a12 .;........*...*.
000001f0: 02b5 0003 2a12 04b5 0005 2a12 06b5 0007 ....*.....*.....
00000200: b100 0000 0100 1500 0000 1200 0400 0000 ................
00000210: 0100 0400 0300 0a00 0400 1000 0500 0900 ................
00000220: 1600 1700 0100 1400 0000 2500 0200 0100 ..........%.....
00000230: 0000 09b2 0008 1209 b600 0ab1 0000 0001 ................
00000240: 0015 0000 000a 0002 0000 0008 0008 0009 ................
00000250: 0001 0018 0000 0002 0019 ..........
2.3.2.1 CONSTANT_Utf8_info类型常量池
以下是CONSTANT_Utf8_info类型数据的结构
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length]
}
tag必然是1,
length表达bytes的长度是多少
bytes存储字符串的真正的二进制数据(使用MUTF-8)
这样我们就可以推导,这个字符串最多就只能存放多少个字节了。可以看到 length是u2,是两个字节,两个字节就是 2^16次,即65536,意味着我们的常量池里面的字符串最多最多可以存放65536。我们的方法名也是个字符串,也是需要存储在常量池中的,意味着方法名的字节长度是有限制的,不然就会编译报错,因为class规范上不允许存储那么长的字符串。
这里又有个小点,class里面的byte是使用MUTF-8进行存储的,那么MUTF-8是个什么东西?这个东西看起来有点像UTF-8,那么我们先了解一把UTF-8。UTF-8是一种变长编码方式,使用1~4个字节表示一个字符,规则如下。
- 对于传统的ASCII编码字符(0x0001~0x007F),UTF-8用一个字节来表示,如下所示。
00 00 00 01 ~ 00 00 00 7F -> 0x xx xx xx
因此英文字母的ASCII编码和UTF-8编码的结果一样。 - 对于0080~07FF范围的字符,UTF-8用2个字节来表示,如下所示。
0000 0080 ~ 0000 07FF -> 11 0x xx xx 10 xx xx xx
程序在遇到这种字符的时候,会把第一个字节的110和第二个字节的10去掉,再把剩下的bit组成新的两字节数据。 - 对于0000 0800~0000 FFFF范围的字符,UTF-8用3个字节表示,如下所示。
0000 0800 ~ 0000 FFFF -> 11 10 xx xx 10 xx xx xx 10 xx xx xx
程序在遇到这种字符的时候,会把第一个字节的1110、第二和第三个字节的10去掉,再把剩下的bit组成新的3字节数据。 - 对于0001 0000~0010 FFFF范围的字符,UTF-8用4个字节表示,如下所示。
0001 0000-0010 FFFF -> 11 11 0x xx 10 xx xx xx 10 xx xx xx 10 xx xx xx
因此在碰到编码之后的二进制之后,你可以用下面的方式进行转码,当然肯定先会读取第一个字节
- 当二进制 是 0x xx xx xx 意味着,这是使用1个字节存储的数据,接下来将会一口气读取1个字节
- 当二进制 是 11 0x xx xx 意味着,这是使用2个字节存储的数据,接下来将会一口气读取2个字节
- 当二进制 是 11 10 xx xx 意味着,这是使用3个字节存储的数据,接下来将会一口气读取3个字节
- 当二进制 是 11 11 0x xx 意味着,这是使用4个字节存储的数据,接下来将会一口气读取4个字节
MUTF-8的编码格式与UTF-8的编码有什么不一样呢?
- MUTF-8里用两个字节表示空字符(“\0”),把前面介绍的双字节表示格式110xxxxx 10xxxxxx中的x全部填0,也即0xC080,而在标准UTF-8编码中只用一个字节0x00表示
- MUTF-8只用到了标准UTF-8编码中的单字节、双字节、三字节表示方式,没有用到4字节表示方式。编码在U+FFFF之上的字符,Java使用“代理对”(surrogate pair)通过2个字符表示。

‘\0’使用双字节编码,双字节表示格式110xxxxx 10xxxxxx,x位全部填充为0,则有
11 00 00 00 10 00 00 00 -> 01 00 02 C0 80
而四字节的表情为:01 00 06 ed a0 bd ed b8 82
01表达utf-8格式,06表达后面使用6字节表达数据。则有:
ed a0 bd -> 1110 1101 1010 0000 1011 1101 -> 1101 10 0000 11 1101 -> D83D
ed b8 82 -> 1110 1101 1011 1000 1000 0010 -> 1101 11 1000 00 0010 -> DE02
这么一来就刚好凑上了。
2.3.2.2 CONSTANT_String_info 类型
CONSTANT_String_info类型表达如下
CONSTANT_String_info {
u1 tag;
u2 string_index;
}
tag写死了是08,StringIndex表达常量池的第几号位置,这个index必然指向CONSTANT_Utf8_info类型的常量池对项。
上文中,我们写了
public final String hello = "hello";
Utf8_info的数据在这里

借助javap的力量看看,这个hello是常量池的第几项:
Constant pool:
#1 = Methodref #12.#26 // java/lang/Object."<init>":()V
#2 = String #13 // hello
#3 = Fieldref #11.#27 // Hello2.hello:Ljava/lang/String;
#4 = String #28 //
#5 = Fieldref #11.#29 // Hello2.x:Ljava/lang/String;
#6 = String #30 // 😂
#7 = Fieldref #11.#31 // Hello2.y:Ljava/lang/String;
#8 = Fieldref #32.#33 // java/lang/System.out:Ljava/io/PrintStream;
#9 = String #34 // Hello, World
#10 = Methodref #35.#36 // java/io/PrintStream.println:(Ljava/lang/String;)V
#11 = Class #37 // Hello2
#12 = Class #38 // java/lang/Object
#13 = Utf8 hello
#14 = Utf8 Ljava/lang/String;
#15 = Utf8 ConstantValue
#16 = Utf8 x
#17 = Utf8 y
#18 = Utf8 <init>
#19 = Utf8 ()V
#20 = Utf8 Code
#21 = Utf8 LineNumberTable
#22 = Utf8 main
#23 = Utf8 ([Ljava/lang/String;)V
#24 = Utf8 SourceFile
#25 = Utf8 Hello2.java
#26 = NameAndType #18:#19 // "<init>":()V
#27 = NameAndType #13:#14 // hello:Ljava/lang/String;
#28 = Utf8
#29 = NameAndType #16:#14 // x:Ljava/lang/String;
#30 = Utf8 😂
#31 = NameAndType #17:#14 // y:Ljava/lang/String;
#32 = Class #39 // java/lang/System
#33 = NameAndType #40:#41 // out:Ljava/io/PrintStream;
#34 = Utf8 Hello, World
#35 = Class #42 // java/io/PrintStream
#36 = NameAndType #43:#44 // println:(Ljava/lang/String;)V
#37 = Utf8 Hello2
#38 = Utf8 java/lang/Object
#39 = Utf8 java/lang/System
#40 = Utf8 out
#41 = Utf8 Ljava/io/PrintStream;
#42 = Utf8 java/io/PrintStream
#43 = Utf8 println
#44 = Utf8 (Ljava/lang/String;)V
可以看到 #2与#13是我们的目标,人肉一把这个string类型的二进制:
08 00 0D
那么我们就找到对应的二进制了

CONSTANT_Class_info类型
CONSTANT_Class_info结构用来表示类或接口,结构上和与CONSTANT_String_info类似
CONSTANT_Class_info {
u1 tag;
u2 name_index;
}
tag是固定值7,name_index指向常量池索引,必然指向CONSTANT_Utf8_info,存储类或接口的全限定名
使用javap把常量池抠出来
#11 = Class #37 // Hello2
#37 = Utf8 Hello2
相当于#37存储了当前类的名字,而#11是个class_info类型,指向#37的utf-info类型
CONSTANT_NameAndType_info类型
CONSTANT_NameAndType_info结构用来表示字段或者方法,使用以下的格式进行存储
CONSTANT_NameAndType_info{
u1 tag;
u2 name_index;
u2 descriptor_index;
}
tag值固定12,name_index指向存储方法名字的utf-info,descriptor_index指向了入参描述的utf-info
我们制造一个新的java类
public class Hello3{
public static void testMethod(int id, String name) {
}
public static void main(String[] args) {
testMethod(1,"吃饭");
}
}
编译后得到常量池为
Constant pool:
#1 = Methodref #5.#16 // java/lang/Object."<init>":()V
#2 = String #17 // 吃饭
#3 = Methodref #4.#18 // Hello3.testMethod:(ILjava/lang/String;)V
#4 = Class #19 // Hello3
#5 = Class #20 // java/lang/Object
#6 = Utf8 <init>
#7 = Utf8 ()V
#8 = Utf8 Code
#9 = Utf8 LineNumberTable
#10 = Utf8 testMethod
#11 = Utf8 (ILjava/lang/String;)V
#12 = Utf8 main
#13 = Utf8 ([Ljava/lang/String;)V
#14 = Utf8 SourceFile
#15 = Utf8 Hello3.java
#16 = NameAndType #6:#7 // "<init>":()V
#17 = Utf8 吃饭
#18 = NameAndType #10:#11 // testMethod:(ILjava/lang/String;)V
#19 = Utf8 Hello3
#20 = Utf8 java/lang/Object
可以看到#18的NameAndType类型指向#10与#11,后面的"testMethod:(ILjava/lang/String;)V"看上去就是#10与#11的字符串拼接。
descriptor_index会比较难理解,这个本质上是字段描述符+返回。字段描述符是有规则的:
- 原始类型,byte、int、char、float等这些简单类型使用一个字符来表示,比如J对应long类型,B对应byte类型。
- 引用类型使用L;的方式来表示,为了防止多个连续的引用类型描述符出现混淆,引用类型描述符最后都加了一个“;”作为结束,比如字符串类型String的描述符为“Ljava/lang/String;”。
- JVM使用一个前置的“[”来表示数组类型,如int[]类型的描述符为“[I”,字符串数组String[]的描述符为“[Ljava/lang/String;”。而多维数组描述符只是多加了几个“[”而已,比如Object[][][]类型的描述符为“[[[Ljava/lang/Object;”
例如
- void test(int,Integer,int[],Integer[])就可以写成(ILjava/lang/Integer[I[Ljava/lang/Integer;)V,这里的V表达void
- Object test(int,Integer,int[],Integer[])就可以写成(ILjava/lang/Integer[I[Ljava/lang/Integer;)Ljava/lang/Object
CONSTANT_Fieldref_info
这三个结构差不多,含义分别是:
- CONSTANT_Fieldref_info 字段的符号引用
- CONSTANT_Methodref_info 类方法的符号引用
- CONSTANT_InterfaceMethodref_info 接口中方法的符号引用
结构表示如下
CONSTANT_Fieldref_info {
u1 tag;
u2 class_index;
u2 name_and_type_index;
}
CONSTANT_Methodref_info {
u1 tag;
u2 class_index;
u2 name_and_type_index;
}
CONSTANT_InterfaceMethodref_info {
u1 tag;
u2 class_index;
u2 name_and_type_index;
}
以上的name_and_type_index都将指向 nameAndType_info的索引
以methodRef_info举例,参考Hello3的反编译结果
Constant pool:
#1 = Methodref #5.#16 // java/lang/Object."<init>":()V
#2 = String #17 // 吃饭
#3 = Methodref #4.#18 // Hello3.testMethod:(ILjava/lang/String;)V
#4 = Class #19 // Hello3
#5 = Class #20 // java/lang/Object
#6 = Utf8 <init>
#7 = Utf8 ()V
#8 = Utf8 Code
#9 = Utf8 LineNumberTable
#10 = Utf8 testMethod
#11 = Utf8 (ILjava/lang/String;)V
#12 = Utf8 main
#13 = Utf8 ([Ljava/lang/String;)V
#14 = Utf8 SourceFile
#15 = Utf8 Hello3.java
#16 = NameAndType #6:#7 // "<init>":()V
#17 = Utf8 吃饭
#18 = NameAndType #10:#11 // testMethod:(ILjava/lang/String;)V
#19 = Utf8 Hello3
#20 = Utf8 java/lang/Object
#3 引用了#4的class_info信息与#18的NameAndType信息,成为一个Methodref信息。剩下两种机制一样
2.3.7 CONSTANT_Methodref_info类型
CONSTANT_Methodref_info {
u1 tag;
u2 class_index;
u2 name_and_type_index;
}
CONSTANT_InterfaceMethodref_info类型
表示方法引用信息:
CONSTANT_InterfaceMethodref_info {
u1 tag;
u2 class_index;
u2 name_and_type_index;
}
CONSTANT_MethodType_info类型
从JDK1.7开始,为了更好地支持动态语言调用,增加以下3种常量池类型,但是java7没用用上,但是就因为这个东西的出现,使各种其他语言可以跑在我们的java虚拟机上。
- CONSTANT_MethodType_info
- CONSTANT_MethodHandle_info
- CONSTANT_InvokeDynamic_info
CONSTANT_MethodType_info表示方法类型,可以使用这样的描述:
CONSTANT_MethodType_info {
u1 tag;
u2 descriptor_index;
}
CONSTANT_MethodHandle_info类型
这个结构表达方法句柄,其结构可以这样描述:
CONSTANT_MethodHandle_info {
u1 tag;
u1 reference_kind;
u2 reference_index;
}
reference_kind项的值必须在1至9之间(包括1和9),它决定了方法句柄的类型。
- 如果reference_kind项的值为1(REF_getField)、2(REF_getStatic)、3(REF_putField)或4(REF_putStatic),那么常量池在reference_index索引处的项必须是CONSTANT_Fieldref_info结构,表示由一个字段创建的方法句柄。
- 如果reference_kind项的值是5(REF_invokeVirtual)、6(REF_invokeStatic)、7(REF_invokeSpecial)或8(REF_newInvokeSpecial),那么常量池在reference_index索引处的项必须是CONSTANT_Methodref_info结构,表示由类的方法或构造函数创建的方法句柄。
- 如果reference_kind项的值是9(REF_invokeInterface),那么常量池在reference_index索引处的项必须是CONSTANT_InterfaceMethodref_info结构,表示由接口方法创建的方法句柄。
- 如果reference_kind项的值是5(REF_invokeVirtual)、6(REF_invokeStatic)、7(REF_invokeSpecial)或9(REF_invokeInterface),那么方法句柄对应的方法不能为实例初始化()方法或类初始化方法()。
- 如果reference_kind项的值是8(REF_newInvokeSpecial),那么方法句柄对应的方法必须为实例初始化()方法。
CONSTANT_InvokeDynamic_info类型
表示invokedynamic指令所使用到的引导方法(Bootstrap Method)、引导方法使用到动态调用名称(Dynamic Invocation Name)、参数和请求返回类型、以及可以选择性的附加被称为静态参数(Static Arguments)的常量序列。
CONSTANT_InvokeDynamic_info {
u1 tag;
u2 bootstrap_method_attr_index;
u2 name_and_type_index;
}
bootstrap_method_attr_index项的值必须是对当前Class文件中引导方法表的bootstrap_methods[]数组的有效索引。
name_and_type_index项的值必须是对当前常量池的有效索引,常量池在该索引处的项必须是CONSTANT_NameAndType_info结构,表示方法名和方法描述符。
类访问标记(Access flags)
总共四个字节,用来描述当前class前面的标记的。
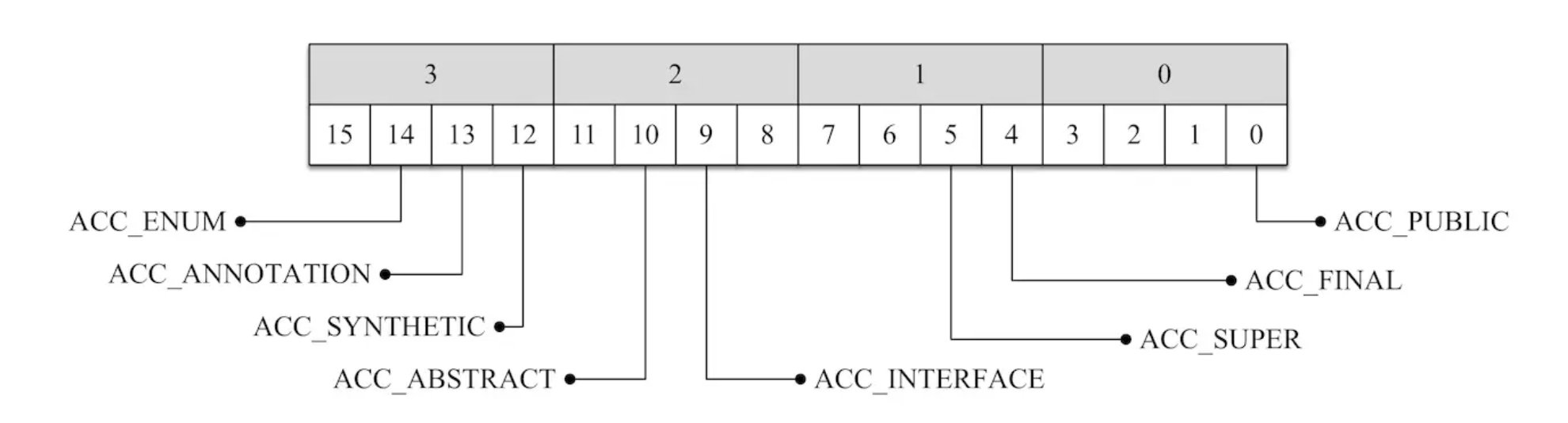
| Flag Name | Value | Interpretation |
|---|---|---|
| ACC_PUBLIC | 1 | 标识是否是 public |
| ACC_FINAL | 10 | 标识是否是 final |
| ACC_SUPER | 20 | 使用新的invokespecial语义,已经不用了 |
| ACC_INTERFACE | 200 | 标识是类还是接口 |
| ACC_ABSTRACT | 400 | 标识是否是 abstract |
| ACC_SYNTHETIC | 1000 | 编译器自动生成,不是用户源代码编译生成 |
| ACC_ANNOTATION | 2000 | 标识是否是注解类 |
| ACC_ENUM | 4000 | 标识是否是枚举类 |
其他标志就不做介绍了, 这些标志都很简单。 比较陌生的可能是ACC_SUPER这个标志,明明类型不能被super关键字修饰啊, 那这个ACC_SUPER是做什么的呢?表中可以看出,它的含义是:使用新的invokespecial语义 。 invokespecial是一个字节码指令, 用于调用一个方法, 一般情况下, 调用构造方法或者使用super关键字显示调用父类的方法时, 会使用这条字节码指令。 这正是ACC_SUPER这个名字的由来。 在java 1.2之前, invokespecial对方法的调用都是静态绑定的, 而ACC_SUPER这个标志位在java 1.2的时候加入到class文件中, 它为invokespecial这条指令增加了动态绑定的功能。
还有一点需要说明, 既然access_flags 出现在class文件中的类的层面上, 那么它只能描述类型的修饰符, 而不能描述字段或方法的修饰符, 不能将这里的access_flags 和后面要介绍的方法表和字段表中的访问修饰符相混淆。
此外, 在Java 5 的中, 引入和注解和枚举的新特性, 那么可以推测, ACC_ANNOTATION 和 ACC_ENUM是在Java 5版本中加入的。 class文件虽然总体上保持前后一致性, 但他也不是一成不变的, 也会跟着Java版本的提升而有所改变, 但是总体来说, class文件格式还是相对稳定的, 变动的地方不是很多。
ACC_SYNTHETIC的标记号在java语言里不常用到。我们看下官方解释:
Any constructs introduced by a Java compiler that do not have a corresponding construct in the source code must be marked as synthetic, except for default constructors, the class initialization method, and the values and valueOf methods of the Enum class.
大意为:由java编译器生成的(除了像默认构造函数这一类的)方法,或者类
import static java.lang.System.out;
public final class DemonstrateSyntheticMethods {
public static void main(final String[] arguments) {
DemonstrateSyntheticMethods.NestedClass nested =
new DemonstrateSyntheticMethods.NestedClass();
out.println("String: " + nested.highlyConfidential);
}
private static final class NestedClass {
private String highlyConfidential = "Don't tell anyone about me";
private int highlyConfidentialInt = 42;
private Calendar highlyConfidentialCalendar = Calendar.getInstance();
private boolean highlyConfidentialBoolean = true;
}
}
编译后会生成内部类,
javap DemonstrateSyntheticMethods\$NestedClass.class
Compiled from "DemonstrateSyntheticMethods.java"
final class DemonstrateSyntheticMethods$NestedClass {
DemonstrateSyntheticMethods$NestedClass(DemonstrateSyntheticMethods$1);
static java.lang.String access$100(DemonstrateSyntheticMethods$NestedClass);
}
这个方法就是编译器生成的synthetic方法。编译器为了方便内部类的私有成员被外部类引用,生成了一个get方法,这可以被理解为一个trick,绕开了private成员变量的限制。
编译器通过生成一些在源代码中不存在的synthetic方法和类的方式,实现了对private级别的字段和类的访问,从而绕开了语言限制,这可以算是一种trick。
在实际生产和应用中,基本不存在程序员需要考虑synthetic的地方。
PS: 在此提一个的常见的存在synthetic的案例。
如果同时用到了Enum和switch,如先定义一个enum枚举,然后用switch遍历这个枚举,java编译器会偷偷生成一个synthetic的数组,数组内容是enum的实例。
可供参考:
this_class,super_name,interfaces
这三部分用来确定类的继承关系,this_class表示类索引,super_name表示直接父类的索引。
分别使用两个字节表达,this_class与super_name都将指向CONSTANT_Class_info类型的字符串常量
interfaces表示类或者接口的直接父接口。class文件里面使用interfaces_count 与 interfaces[interfaces_count]共同表达。其中interfaces的结构指向CONSTANT_Class_info常量池
字段表
描述完类继承关系之后就是描述字段数据了,字段表表达当前的类内都有哪些field,基本结构长这样
{
u2 fields_count;
field_info fields[fields_count];
}
使用两个字节的fields_count表达字段表的容量,field_info的结构是这样的:
field_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
字段结构分为4个部分:
第一部分access_flags表示字段的访问标记,用来标识是public、private还是protected,是否是static,是否是final等;
第二部分name_index用来表示字段名,指向常量池的字符串常量;
第三部分descriptor_index是字段描述符的索引,指向常量池的字符串常量;
第四部分attributes_count、attribute_info表示属性的个数和属性集合
字段表访问标志
我们知道,一个字段可以被各种关键字去修饰,比如:作用域修饰符(public、private、protected)、static修饰符、final修饰符、volatile修饰符等等。因此,其可像类的访问标志那样,使用一些标志来标记字段。字段的访问标志有如下这些:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 1 | 字段是否为public |
| ACC_PRIVATE | 2 | 字段是否为private |
| ACC_PROTECTED | 4 | 字段是否为protected |
| ACC_STATIC | 8 | 字段是否为static |
| ACC_FINAL | 10 | 字段是否为final |
| ACC_VOLATILE | 40 | 字段是否为volatile |
| ACC_TRANSTENT | 80 | 字段是否为transient |
| ACC_SYNCHETIC | 1000 | 字段是否为由编译器自动产生 |
| ACC_ENUM | 4000 | 字段是否为enum |
字段描述符
前文介绍过,使用更加精简的方式表达类型,如
- String -> (Ljava/lang/String;)
- Integer[] -> ([Ljava/lang/String;)
字段属性
与字段相关的属性包括ConstantValue、Synthetic、Signature、Deprecated、Runtime-Visible-Annotations和RuntimeInvisibleAnnotations这6个,比较常见的是ConstantValue属性,用来表示一个常量字段的值,这个将在后面描述attribute_info结构时候具体介绍。
方法表
字段定义完成之后,就开始定义方法了。与字段表类似,使用以下结构存储:
{
u2 methods_count;
method_info method_infos[fields_count];
}
fields_count表达将会有几个方法。field_info将会存储和方法相关的全量信息。field_info结构如下
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}
方法method_info结构分为四部分:
第一部分access_flags表示方法的访问标记,用来标记是public、private还是protected,是否是static,是否是final等;
第二部分name_index、descriptor_index分别表示方法名和方法描述符的索引值,指向常量池的字符串常量;
第三部分attributes_count和attribute_info表示方法相关属性的个数和属性集合,包含了很多有用的信息,比如方法内部的字节码就存放在Code属性中。
方法表访问标志
类似于字段表,也会有个方法访问标志挂在method_info上的,如下表,
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 方法是否为public |
| ACC_PRIVATE | 0x0002 | 方法是否为private |
| ACC_PROTECTED | 0x0004 | 方法是否为protected |
| ACC_STATIC | 0x0008 | 方法是否为static |
| ACC_FINAL | 0x0010 | 方法是否为final |
| ACC_SYHCHRONRIZED | 0x0020 | 方法是否为synchronized |
| ACC_BRIDGE | 0x0040 | 方法是否是有编译器产生的方法 |
| ACC_VARARGS | 0x0080 | 方法是否接受参数 |
| ACC_NATIVE | 0x0100 | 方法是否为native |
| ACC_ABSTRACT | 0x0400 | 方法是否为abstract |
| ACC_STRICTFP | 0x0800 | 方法是否为strictfp |
| ACC_SYNTHETIC | 0x1000 | 方法是否是有编译器自动产生的 |
有些flag是可以同时存在的,只需要 x|y 再赋予给方法表访问标志即可
方法名与描述符
紧随方法访问标记的是方法名索引name_index,指向常量池中CONSTANT_Utf8_info类型的字符串常量。
比如有这样一个方法定义为private void foo(),编译器会生成一个类型为CONSTANT_Utf8_info的字符串常量项,里面存储了“foo”,方法名索引name_index指向了这个常量项。
方法描述符(descriptor_index)用来表示一个方法所需的参数和返回值,格式为:(参数1类型 参数2类型 参数3类型 …)返回值类型。方法描述符索引也是指向常量池中类型为CONSTANT_Utf8_info的字符串常量项。
- Object foo(int i,double d,Thread t)—描述符—> (IDLjava/lang/Thread;)Ljava/lang/Object;”
方法属性表
方法属性表是method_info结构的最后一部分。前面介绍了方法的访问标记和方法签名,还有一些重要的信息没有出现,如方法声明抛出的异常,方法的字节码,方法是否被标记为deprecated等,属性表就是用来存储这些信息的。与方法相关的属性有很多,其中比较重要的是Code和Exceptions属性,其中Code属性存放方法体的字节码指令,Exceptions属性用于存储方法声明抛出的异常。详细我们之后描述。
注意事项
- 如果父类方法在子类中没有被重写(Override),方法表集合中就不会出现父类的方法。
- 编译器可能会自动添加方法,最典型的便是类构造方法(静态构造方法)
<client>方法和默认实例构造方法<init>方法。 - 在Java语言中,要重载(Overload)一个方法,除了要与原方法具有相同的简单名称之外,还要求必须拥有一个与原方法不同的特征签名,特征签名就是一个方法中各个参数在常量池中的字段符号引用的集合,也就是因为返回值不会包含在特征签名之中,因此Java语言里无法仅仅依靠返回值的不同来对一个已有方法进行重载。
属性表
属性表可以说是除了常量池之外最复杂的一个属性,里面的内容会很多,很多地方都使用的上。而且这部分是可以由不通虚拟机厂商自定义的,非常灵活。以下是属性表结构
{
u2 attributes_count;
attribute_info attributes[attributes_count];
}
attribute_info{
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}
attribute_name_index是指向常量池的索引,根据这个索引可以得到attribute的名字,接下来的两部分表示info数组的长度和具体byte数组的内容。虚拟机预定义了20多种属性,如下表:
| 属性名称 | 使用位置 | 含义 |
|---|---|---|
| Code | 方法表 | Java代码编译成的字节码指令 |
| ConstantValue | 字段表 | final关键字定义的常量池 |
| Deprecated | 类,方法,字段表 | 被声明为deprecated的方法和字段 |
| Exceptions | 方法表 | 方法抛出的异常 |
| EnclosingMethod | 类文件 | 仅当一个类为局部类或者匿名类是才能拥有这个属性,这个属性用于标识这个类所在的外围方法 |
| InnerClass | 类文件 | 内部类列表 |
| LineNumberTable | Code属性 | Java源码的行号与字节码指令的对应关系 |
| LocalVariableTable | Code属性 | 方法的局部变量描述 |
| StackMapTable | Code属性 | JDK1.6中新增的属性,供新的类型检查检验器检查和处理目标方法的局部变量和操作数有所需要的类是否匹配 |
| Signature | 类,方法表,字段表 | 用于支持泛型情况下的方法签名 |
| SourceFile | 类文件 | 记录源文件名称 |
| SourceDebugExtension | 类文件 | 用于存储额外的调试信息 |
| Synthetic | 类,方法表,字段表 | 标志方法或字段为编译器自动生成的 |
| LocalVariableTypeTable | 类 | 使用特征签名代替描述符,是为了引入泛型语法之后能描述泛型参数化类型而添加 |
| RuntimeVisibleAnnotations | 类,方法表,字段表 | 为动态注解提供支持 |
| RuntimeInvisibleAnnotations | 表,方法表,字段表 | 用于指明哪些注解是运行时不可见的 |
| RuntimeVisibleParameterAnnotation | 方法表 | 作用与RuntimeVisibleAnnotations属性类似,只不过作用对象为方法 |
| RuntimeInvisibleParameterAnnotation | 方法表 | 作用与RuntimeInvisibleAnnotations属性类似,作用对象哪个为方法参数 |
| AnnotationDefault | 方法表 | 用于记录注解类元素的默认值 |
| BootstrapMethods | 类文件 | 用于保存invokeddynamic指令引用的引导方式限定符 |
这会儿我们分析一把最复杂也是最常用的几个属性。其他的都是一样的套路,偷个懒,以后再在这儿描述一把。
ConstantValue属性
ConstantValue属性是定长属性,位于field_info结构的属性表中。如果该字段为静态类型(即field_info结构的access_flags项设置了ACC_STATIC标志),则说明这个field_info结构表示的常量字段值将被分配为它的ConstantValue属性表示的值,这个过程也是类或接口申明的常量字段(Constant Field)初始化的一部分。这个过程发生在引用类或接口的类初始化方法执行之前。结构为:
ConstantValue_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 constantvalue_index;
}
其中attribute_name_index是指向常量池中值为“ConstantValue”的字符串常量项,attribute_length值固定为2,因为接下来的具体内容只会有两个字节大小。constantvalue_index指向常量池中具体的常量值索引,根据变量的类型不同,constantvalue_index指向不同的常量项。如果变量为long类型,则constantvalue_index指向CONSTANT_Long_info类型的常量项。
我们造一个java文件
import java.io.IOException;
public class Helllo4 {
public static final String aaaaa = "干饭人万岁!";
public static int foo(int i, int j) throws IOException {
int c = i + j + 1;
return c;
}
public static void testException(String a, Integer b){
try {
foo(1,2);
} catch (IOException e){
e.printStackTrace();
} catch (NullPointerException exception){
System.out.println("干饭人万万岁@@@@!!!!!");
}
}
public static void main(String[] args) {
testException("吃饭",100);
}
}
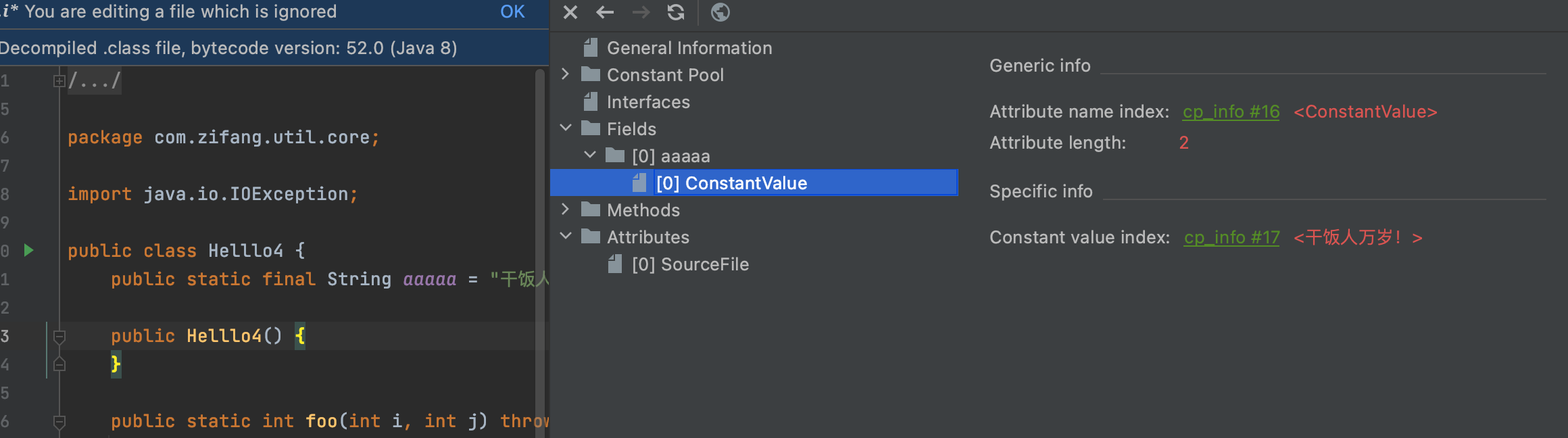
使用工具查看,可以看到与前面的分析一致。
Code属性
Code属性可以说是一个类里面的最重要的组成部分,方法的所有源码
Code_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 max_stack;
u2 max_locals;
u4 code_length;
u1 code[code_length];
u2 exception_table_length;
exception_table[exception_table_length];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
exception_table {
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
}
接下来解释一把这些属性都是干啥的
- 属性名索引(attribute_name_index)占2个字节,指向常量池中CONSTANT_Utf8_info常量,表示属性的名字,这里对应的常量池的字符串常量“Code”。
- 属性长度(attribute_length)占用2个字节,表示属性值长度大小。
- max_stack表示操作数栈的最大深度,方法执行的任意期间操作数栈的深度都不会超过这个值。
它的计算规则是:有入栈的指令stack增加,有出栈的指令stack减少,在整个过程中stack的最大值就是max_stack的值,增加和减少的值一般都是1,但也有例外:LONG和DOUBLE相关的指令入栈stack会增加2,VOID相关的指令则为0。 - max_locals表示局部变量表的大小,但是这个值不等于方法中所有局部变量的数量之和。当一个局部作用域结束,它内部的局部变量占用的位置就可以被接下来的局部变量复用了。
- code_length和code用来表示字节码相关的信息。其中,code_length表示字节码指令的长度,占用4个字节;code是一个长度为code_length的字节数组,存储真正的字节码指令。
- exception_table_length和exception_table用来表示代码内部的异常表信息,如我们熟知的try-catch语法就会生成对应的异常表。exception_table_length表示接下来exception_table数组的长度,每个异常项包含四个部分,可以用下面的结构表示。
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
}
其中start_pc、end_pc、handler_pc都是指向code字节数组的索引值,start_pc和end_pc表示异常处理器覆盖的字节码开始和结束的位置,是左闭右开区间[start_pc,end_pc),包含start_pc,不包含end_pc。handler_pc表示异常处理handler在code字节数组的起始位置,异常被捕获以后该跳转到何处继续执行。 catch_type表示需要处理的catch的异常类型是什么,它用两个字节表示,指向常量池中类型为CONSTANT_Class_info的常量项。如果catch_type等于0,则表示可处理任意异常,可用来实现finally语义。
当JVM执行到这个方法[start_pc,end_pc)范围内的字节码发生异常时,如果发生的异常是这个catch_type对应的异常类或者它的子类,则跳转到code字节数组handler_pc处继续处理。
- attributes_count和attributes[]用来表示Code属性相关的附属属性,Java虚拟机规定Code属性只能包含这四种可选属性:LineNumberTable、LocalVariableTable、LocalVariableTypeTable、StackMapTable。
例如LineNumberTable,它用来存放源码行号和字节码偏移量之间的对应关系,属于调试信息,不是类文件运行的必需属性,默认情况下都会生成。如果没有这个属性,那么在调试时就没有办法在源码中设置断点,也没有办法在代码抛出异常时在错误堆栈中显示出错的行号信息。
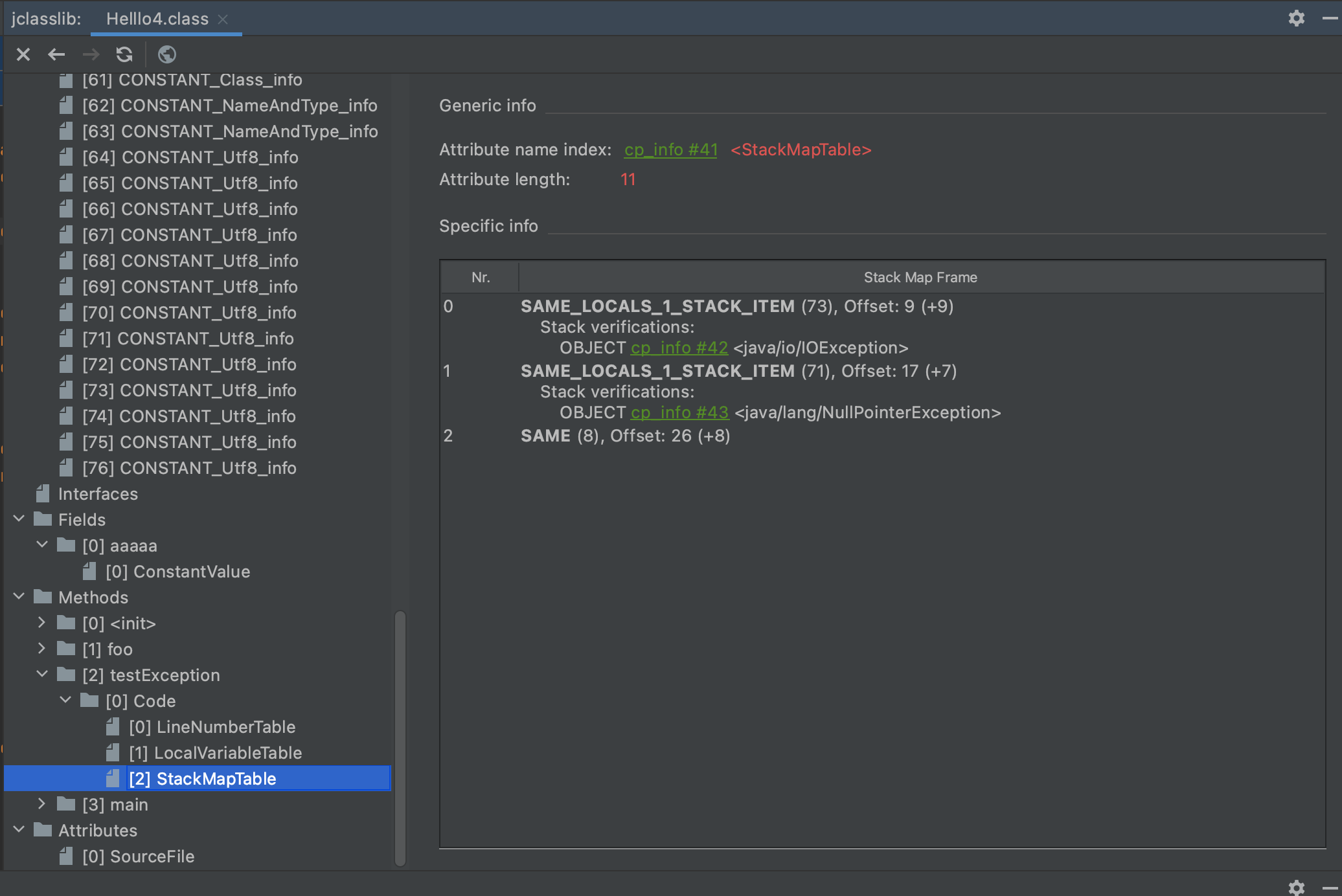
StackMapTable:
StackMapTable属性是一个变长属性,位于Code属性的属性表中。这个属性会在虚拟机类加载的类型阶段被使用。
StackMapTable_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 number_of_entries;
stack_map_frame entries[number_of_entries];
}
attribute_name_index项的值必须是对常量池的有效索引 attribute_length项的值表示当前属性的长度,不包括开始的6个字节。 number_of_entries项的值给出了entries表中的成员数量。Entries表的每个成员是都是一个stack_map_frame结构的项。 entries表给出了当前方法所需的stack_map_frame结构。
我们偷个懒,用jclassLib查看Helllo4的结构体
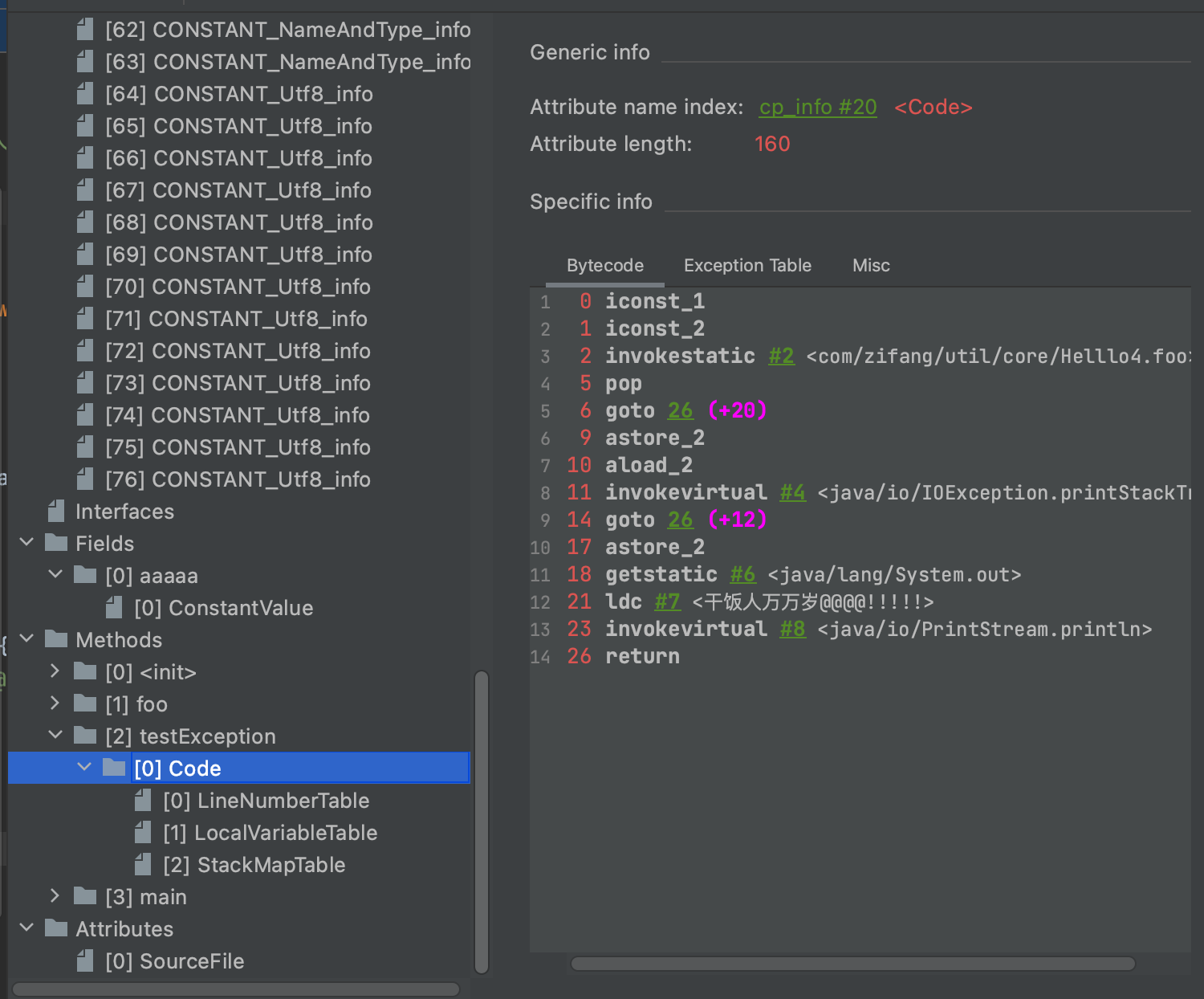
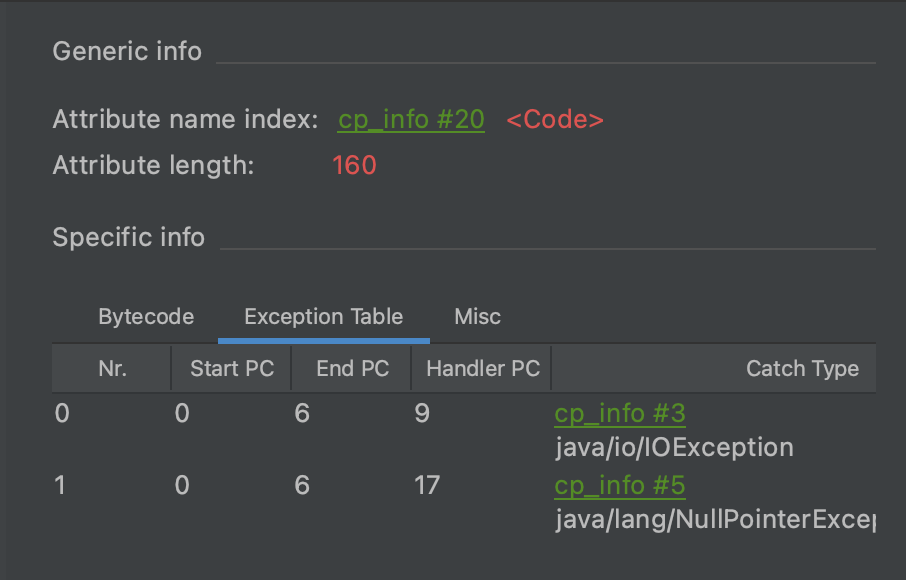
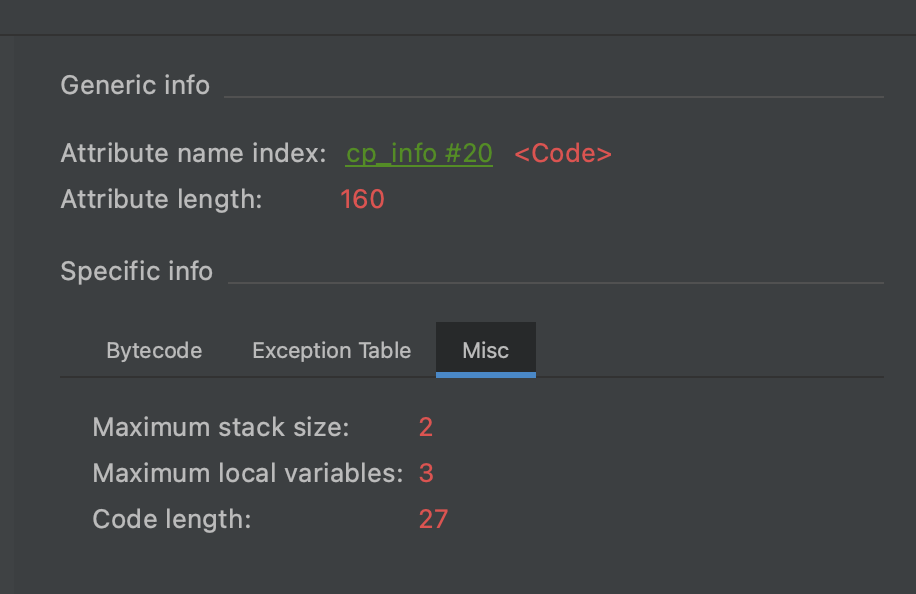
max_stack,max_locals,code_lengh在上图中都能找到对应的图。
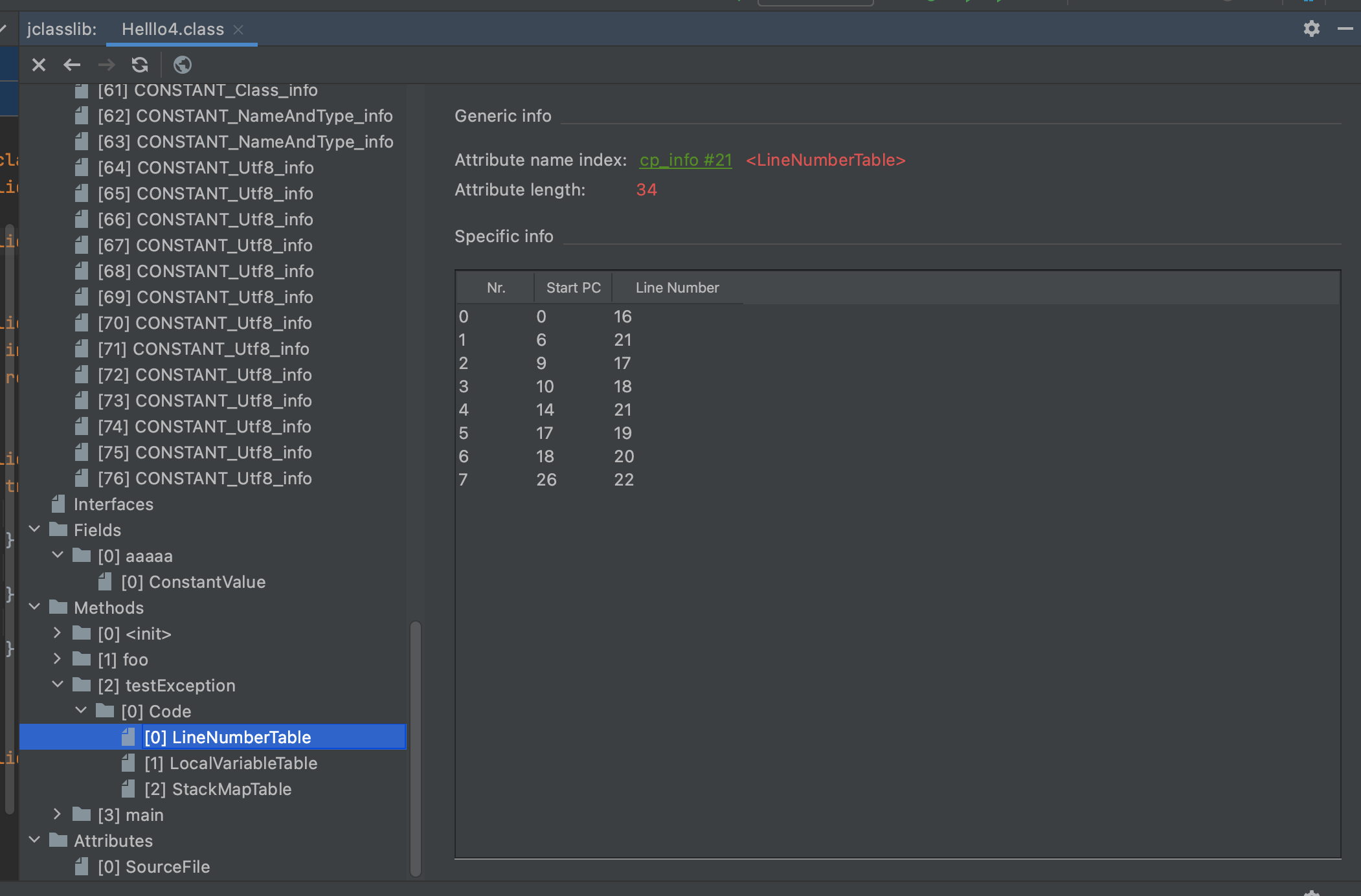
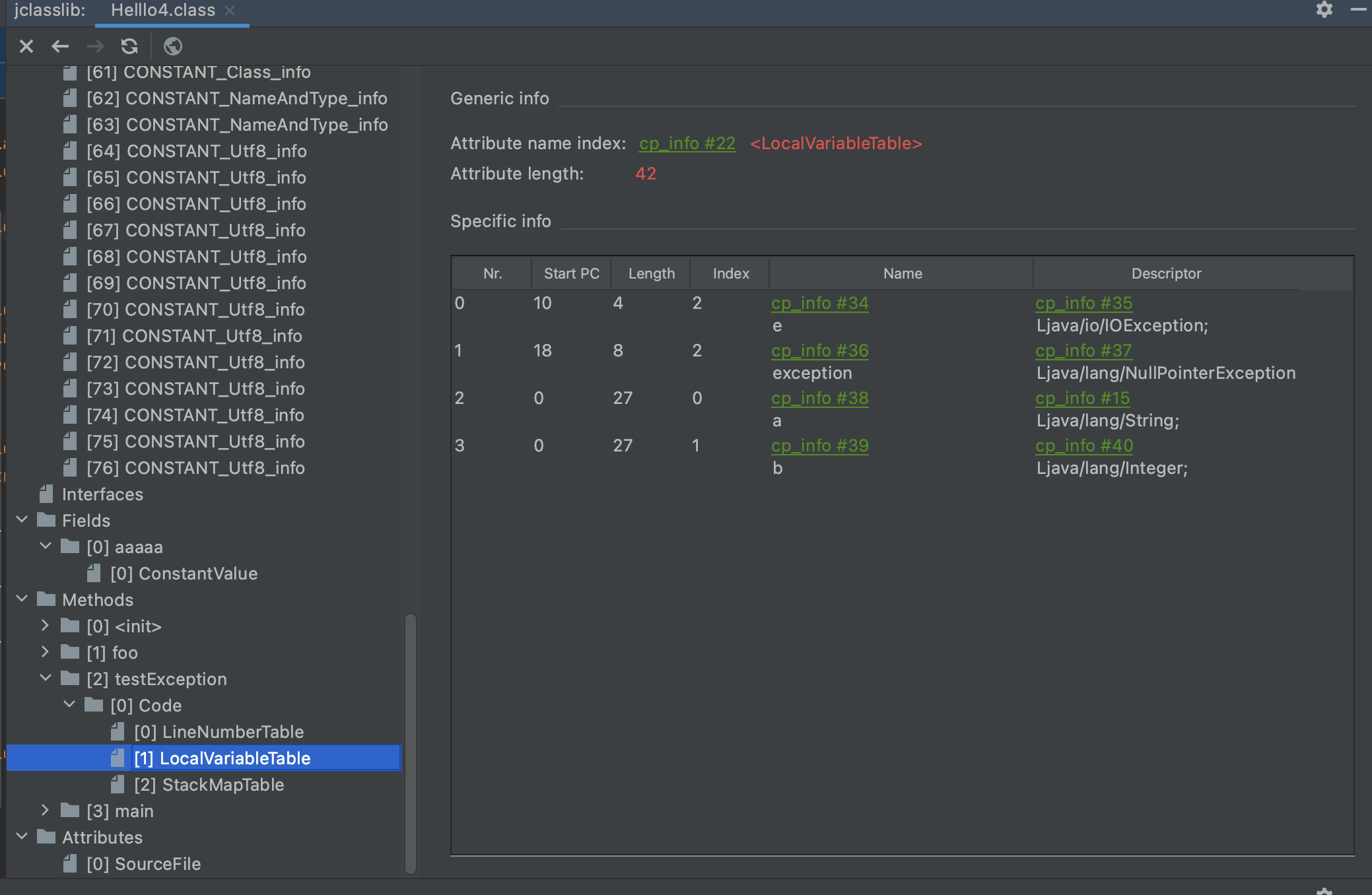
小结
我们整体上分析了class文件的格式,并且介绍了多种方式查看结构的方式。乍一看知识量还是有点多的,而且初看字节码的知识没什么用。其实不然,这个东西学了之后,你的这个世界的认知就广泛了很多。
附录
使用到的java代码demo:
public class Hello {
public final boolean bool = true; // 1(0x01)
public final char c = 'A'; // 65(0x41)
public final byte b = 66; // 66(0x42)
public final short s = 67; // 67(0x43)
public final int i = 68; // 68(0x44)
public static void main(String[] args) {
System.out.println("Hello, World");
}
public void testMethod(int id, String name) {
}
public void foo() {
new Thread (()-> {
System.out.println("hello");
}).start();
}
}
public class TestUser {
private int count;
public void test(int a){
count = count + a;
}
public User initUser(int age,String name){
User user = new User();
user.setAge(age);
user.setName(name);
return user;
}
public void changeUser(User user,String newName){
user.setName(newName);
}
}
public class User {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









