







继承体系
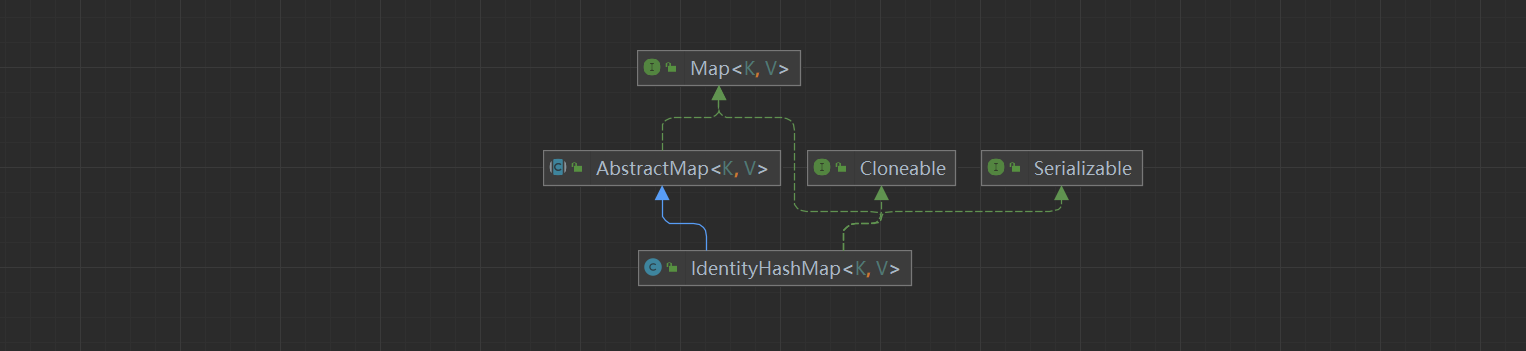
类似于HashMap,IdentityHashMap同样继承自AbstractMap,实现Map接口。
在底层实现方面是Java集合框架中的一个特殊的Map实现,它使用恒等比较来判断两个键是否相等。与其他Map实现类使用equals方法不同,IdentityHashMap会将同一对象的不同引用视为不同的键。
在底层存储方面同样比较特殊,他并非使用Entry进行存储KV,而是使用数组进行存储,如下图所示:
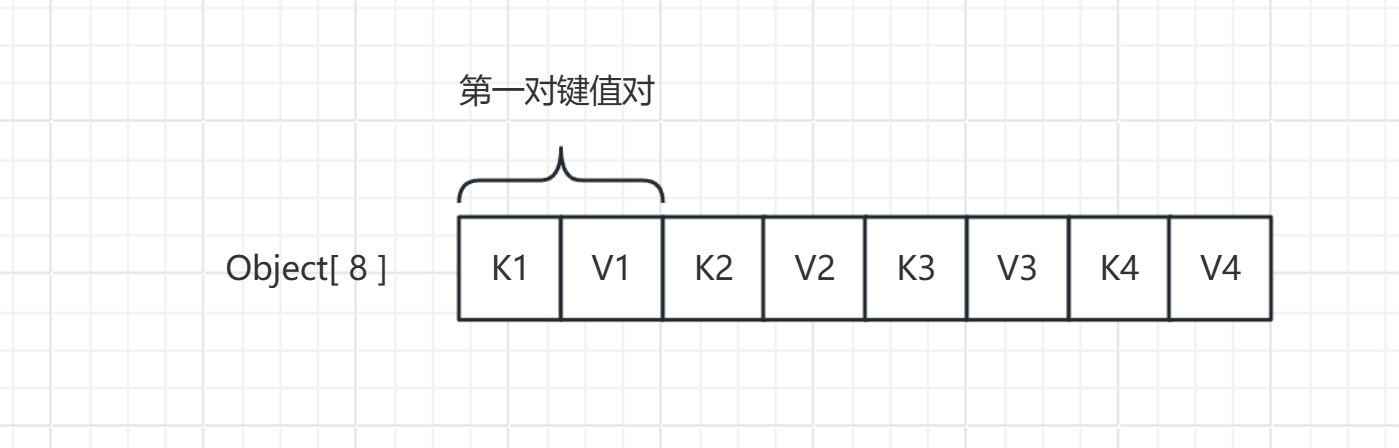
底层存在一个对象数组,而其K-V对是挨着存放的,分别占用数组的一个位置。
重要字段
// 默认容量
private static final int DEFAULT_CAPACITY = 32;
// 最小容量
private static final int MINIMUM_CAPACITY = 4;
// 最大容量
private static final int MAXIMUM_CAPACITY = 1 << 29;
// 存储K-V键值对的数组
transient Object[] table; // non-private to simplify nested class access
// 简直对数量
int size;
//修改次数
transient int modCount;
// 针对null的逻辑替代
static final Object NULL_KEY = new Object();
构造函数
IdentityHashMap的构造函数如下:
public IdentityHashMap() {
init(DEFAULT_CAPACITY);
}
public IdentityHashMap(int expectedMaxSize) {
if (expectedMaxSize < 0)
throw new IllegalArgumentException("expectedMaxSize is negative: "
+ expectedMaxSize);
init(capacity(expectedMaxSize));
}
public IdentityHashMap(Map<? extends K, ? extends V> m) {
// Allow for a bit of growth
this((int) ((1 + m.size()) * 1.1));
putAll(m);
}
private static int capacity(int expectedMaxSize) {
// assert expectedMaxSize >= 0;
return
(expectedMaxSize > MAXIMUM_CAPACITY / 3) ? MAXIMUM_CAPACITY :
(expectedMaxSize <= 2 * MINIMUM_CAPACITY / 3) ? MINIMUM_CAPACITY :
Integer.highestOneBit(expectedMaxSize + (expectedMaxSize << 1));
}
private void init(int initCapacity) {
// assert (initCapacity & -initCapacity) == initCapacity; // power of 2
// assert initCapacity >= MINIMUM_CAPACITY;
// assert initCapacity <= MAXIMUM_CAPACITY;
table = new Object[2 * initCapacity];
}
其中capacity方法具体逻辑如下:
- 判断目标数值 > 2^29 / 3
a) 如果是则取 2^29
b) 如果否则判断 目标数值是否 <= 2 * 4 / 3 = 2 - 如果是则使用4
2)否则使用 >= 3*目标值的最小2的幂
重要方法
put方法
public V put(K key, V value) {
final Object k = maskNull(key);
retryAfterResize: for (;;) {
final Object[] tab = table;
final int len = tab.length;
int i = hash(k, len);
for (Object item; (item = tab[i]) != null;
i = nextKeyIndex(i, len)) {
if (item == k) {
@SuppressWarnings("unchecked")
V oldValue = (V) tab[i + 1];
tab[i + 1] = value;
return oldValue;
}
}
final int s = size + 1;
// Use optimized form of 3 * s.
// Next capacity is len, 2 * current capacity.
if (s + (s << 1) > len && resize(len))
continue retryAfterResize;
modCount++;
tab[i] = k;
tab[i + 1] = value;
size = s;
return null;
}
}
private static int hash(Object x, int length) {
int h = System.identityHashCode(x);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}
private static int nextKeyIndex(int i, int len) {
return (i + 2 < len ? i + 2 : 0);
}
首先使用key与列表长度计算key所应该存放的索引,查看该位置是否已经有数据,存在数据就开始比对是否是和put的数据相等,相等则替换其对应的数据。如果不想等则调用nextKeyIndex方法不断往后跳两个位置直到找到一个空的位置。找到之后需要判断是否需要扩容,由于扩容会引发所有的数据迁移会再次进行查找目标位置的逻辑。找到之后才会真正将数据填写到对应的index中。
上述逻辑中涉及到扩容,源码如下。先确定扩充后的数据量,判定是否超出极限。然后遍历旧数据不断填入新数组。在选定index的时候,当访问到数组位置上已经有数据的场合下将向后移动两个位置(移动到末尾会移动到数组头部继续移动),不断移动直到找到对应的null的位置作为填充位置。
private boolean resize(int newCapacity) {
// assert (newCapacity & -newCapacity) == newCapacity; // power of 2
int newLength = newCapacity * 2;
Object[] oldTable = table;
int oldLength = oldTable.length;
if (oldLength == 2 * MAXIMUM_CAPACITY) { // can't expand any further
if (size == MAXIMUM_CAPACITY - 1)
throw new IllegalStateException("Capacity exhausted.");
return false;
}
if (oldLength >= newLength)
return false;
Object[] newTable = new Object[newLength];
for (int j = 0; j < oldLength; j += 2) {
Object key = oldTable[j];
if (key != null) {
Object value = oldTable[j+1];
oldTable[j] = null;
oldTable[j+1] = null;
int i = hash(key, newLength);
while (newTable[i] != null)
i = nextKeyIndex(i, newLength);
newTable[i] = key;
newTable[i + 1] = value;
}
}
table = newTable;
return true;
}
get方法
get方法较为简单,计算出hash之后定位到数组位置,如果该位置存在数据则判断是否和目标key相等,如果相等则返回数据否则移动到下一个存储数据的位置。
public V get(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true) {
Object item = tab[i];
if (item == k)
return (V) tab[i + 1];
if (item == null)
return null;
i = nextKeyIndex(i, len);
}
}
remove方法
remove方法较为麻烦,主要原因是当两个计算hash一样的key先后进入容器之后,后者会继续向后进行跳跃找到null的位置尽心填写,在删除第一个key之后,第一个位置上的数据就会成为null,当进行get第二个key的时候,查找逻辑会止步在null的index上。意味着删除之后如果不做任何处理,第二个同hashKey是get不出来的。因此删除后需要规整,所有与当前删除的key同hash的key将往前挪动,这部分逻辑在closeDeletion内体现。
public V remove(Object key) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);
while (true) {
Object item = tab[i];
// 如果找到了需要被删除的key
if (item == k) {
modCount++;
size--;
@SuppressWarnings("unchecked")
V oldValue = (V) tab[i + 1];
tab[i + 1] = null;
tab[i] = null;
closeDeletion(i);
return oldValue;
}
// 如果找到的位置上是null,意味着容器内不存在这个key
if (item == null)
return null;
// 当前index数据存在,但是并不是目标数据的情况下将继续往后找
i = nextKeyIndex(i, len);
}
}
private void closeDeletion(int d) {
// Adapted from Knuth Section 6.4 Algorithm R
Object[] tab = table;
int len = tab.length;
// Look for items to swap into newly vacated slot
// starting at index immediately following deletion,
// and continuing until a null slot is seen, indicating
// the end of a run of possibly-colliding keys.
Object item;
// 不断遍历目标index的数据,直到对应的index位置上的数据是null
for (int i = nextKeyIndex(d, len); (item = tab[i]) != null;
i = nextKeyIndex(i, len) ) {
// The following test triggers if the item at slot i (which
// hashes to be at slot r) should take the spot vacated by d.
// If so, we swap it in, and then continue with d now at the
// newly vacated i. This process will terminate when we hit
// the null slot at the end of this run.
// The test is messy because we are using a circular table.
int r = hash(item, len);
// 不断找到后续的同hash的键值对,并和当前的节点进行替换,实现迁移
if ((i < r && (r <= d || d <= i)) || (r <= d && d <= i)) {
tab[d] = item;
tab[d + 1] = tab[i + 1];
tab[i] = null;
tab[i + 1] = null;
d = i;
}
}
总结
IdentityHashMap还是比较简单的,相比HashMap使用hash/equals来判断key是否相等,它用的是引用相等进行判断,这是它的特色。除此之外底层使用数组来存储数据,k-v分别占用数组内的一个位置,当往容器添加数据的时候,当感知到数组的位置上已经存在数据的时候将向后继续查找可以存入数据的位置,以达到解决冲突的效果。















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









