







前言
今天开个新坑,从0开始学习Kafka系列,力求以最精炼易懂的方式,将Kafka基础完成,最终能够具备基础的Kafka实践研究能力。
那么第一阶段完成后,你将会获得:了解Kafka基本运行原理以及核心概念的基本架构。话不多说,我们直接开始。
公众号:青鸟瞰滨 欢迎关注
基本运行模式
kafka首先定位是一个消息中间件,主要功能是作为消息引擎传递消息数据。
如下图所示,消息的传递简单概括为下面的步骤:
1、生产者生产了消息后,将消息A放入Kafka集群中;
2、消费者从Kafka集群中读取到消息A

有上面两个步骤,Kafka消息传递的一个完整流程就结束了。
基本概念
从上面的过程中可以看出,Kafka核心涉及几个概念:生产者、消费者、Kafka集群。这些都是最简单概括下涉及到的核心概念,下面我们将分别从这三个点出发,逐层将Kafka消息的结构和具体运行细节进行剖析。
生产者
顾名思义是作为生产消息的源头,那么将消息发送到Kafka集群这个过程,需要解决以下几个基础问题:
1、发送消息数据到集群哪里
2、什么才算发送完成
3、发送失败如何处理
要回答这几个问题,首先要知道:生产者底层在网络上通过TCP协议以Socket的方式与Kafka集群进行通信。
那么第二个问题也就迎刃而解:当Kafka集群回复相应信息就能够让生产判断是否发送成功或是失败。
发送到集群首先集群里某一个节点负责接收消息,并将其存储起来以备消费者消费。先抛开主从、备份等诸多集群问题,我们暂时将集群看做一个整体,此时只有一个节点接收到消息,那么消息应该被存储到哪里。答案是:文件里。那么又是如何组织的呢。答案是:通过主题(Topic)和分区(Partition)在内存中组织。

总结一下:生产者通过TCP协议将消息发送到Kafka集群的某一个节点上,并以Topic-Partition-Message(类似于“省-市-区”)的组织形式存储在集群机器的文件系统里。
到这里,对于生产者要做的事情,你有了一个初步的认识。后续将逐步深入理解其中的各种原理和实现。
消费者
2022年11月15日更新
消费者与上面的生产者是相对应的,接收生产者发送的消息并进行相应业务操作的部分。和前面一样,依然需要解决以下几个基础问题:
1、如何获取到消息
2、怎么确定需要接收哪些消息
3、接收的模式是什么样的
要回答如何获取到消息,首先要明确,与生产者一样,消费者也是Kafka的客户端,因此消费者需要消费消息也是发送相应的请求到Kafka集群来获取消息。
由生产者生产的消息格式可以推断出,消费者消费时,通过指定主题+分区的方式来确定接收对应的数据。
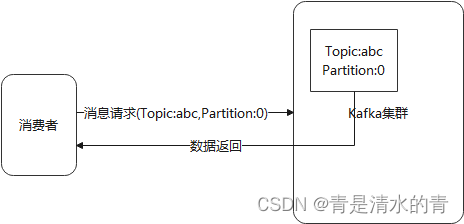
一般来说,从远处获取消息的方式无外乎两种:1、消息代理分派消息到下游消费者;2、消费者从消息代理主动拉取消息。

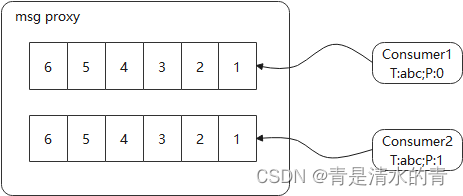
细心的朋友已经发现,其实消费者发送请求和获取消息是由消息代理进行完成的,具体消息消费者要从消息代理获取。而Kafka选择的是第二种拉取方式进作为具体的消息接收模式。
总结一下:消费者同样通过TCP协议从Kafka集群获取消息并在内部通过消费者向消息代理拉取的方式获取消息,通过主题和分区确定具体拉取的消息集合。
到这里,对于消费者要做的事情,你有了一个初步的认识。后续将逐步深入理解其中的各种原理和实现。
服务端(Kafka集群)
2022年11月16日更新
了解了消费者和生产者之后,最终还需要知道作为中转站的Kafka集群是如何将消息传递的。依然是以下几个问题需要弄清楚:
1、消息中转的过程是什么样的流程
2、消息是如何被存储的
3、集群是如何管理的
其实经过上面两个过程的了解,消息中转的过程已经基本清晰:生产者通过网络请求将数据发送到Kafka集群,Kafka集群将消息存储在本地文件中,当有消费者同样通过网络请求获取消息时,集群再将数据返回给消费者。
消息的存储介质是文件,那么既然是集群,集群上如何存储这些文件呢,其实简单讲就是将数据分散在不同的节点上,并且在不同节点上同时存储这些文件的备份文件作为故障恢复。而这些数据同样是以Topic-Partition方式进行组织的。组织形式我们后续具体深入了解,这里先暂时理解为数据块即可。
最后再来看看集群是如何管理的,设想下一个群体需要做一件事时,需要一个领导者带领。Kafka集群同样有一个领导者(Controller),负责接收客户端的请求并处理、集群的管理以及数据的存储。

总结一下:Kafka集群作为客户端的对端服务端,提供数据存储和中转的功能;内部是通过一个控制器和若干节点共同实现数据存储和请求响应。
到这里,整个Kafka的组织架构轮廓就基本呈现出来了,你所要知道的就是,这是一个由生产者、消费者以及Kafka集群服务端构成的消息传播组件。
后续将从生产者、消费者、服务端、消息、集群等多个方面进行深入研究。
感谢支持!
转载请注明出处















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









