







Kafka简介
Kafka是一个由Scala和Java编写的企业级的消息发布和订阅系统,最早是由Linkedin公司开发,最终开源到Apache软件基金会的项目。Kafka是一个分布式的,支持分区的,多副本的和多订阅者的高吞吐量的消息系统,被广泛应用在应用解耦、异步处理、限流削峰和消息驱动等场景。本文将针对Kafka的架构和相关组件进行简单的介绍。在介绍Kafka的架构之前,我们先了解一下Kafk的核心概念。
Kafka核心概念
在详细介绍Kafka的架构和基本组件之前,需要先了解一下Kafka的一些核心概念。
Producer:消息的生产者,负责往Kafka集群中发送消息;
Consumer:消息的消费者,主动从Kafka集群中拉取消息。
Consumer Group:每个Consumer属于一个特定的Consumer Group,新建Consumer的时候需要指定对应的Consumer Group ID。
Broker:Kafka集群中的服务实例,也称之为节点,每个Kafka集群包含一个或者多个Broker(一个Broker就是一个服务器或节点)。
Message:通过Kafka集群进行传递的对象实体,存储需要传送的信息。
Topic:消息的类别,主要用于对消息进行逻辑上的区分,每条发送到Kafka集群的消息都需要有一个指定的Topic,消费者根据Topic对指定的消息进行消费。
Partition:消息的分区,Partition是一个物理上的概念,相当于一个文件夹,Kafka会为每个topic的每个分区创建一个文件夹,一个Topic的消息会存储在一个或者多个Partition中。
Segment:一个partition当中存在多个segment文件段(分段存储),每个Segment分为两部分,.log文件和 .index 文件,其中 .index 文件是索引文件,主要用于快速查询.log 文件当中数据的偏移量位置;
.log文件:存放Message的数据文件,在Kafka中把数据文件就叫做日志文件。一个分区下面默认有n多个.log文件(分段存储)。一个.log文件大默认1G,消息会不断追加在.log文件中,当.log文件的大小超过1G的时候,会自动新建一个新的.log文件。
.index文件:存放.log文件的索引数据,每个.index文件有一个对应同名的.log文件。
后面我们会对上面的一些核心概念进行更深入的介绍。在介绍完Kafka的核心概念之后,我们来看一下Kafka的对外提供的基本功能,组件及架构设计。
Kafka API
如上图所示,Kafka主要包含四个主要的API组件:
-
Producer API
应用程序通过Producer API向Kafka集群发送一个或多个Topic的消息。 -
Consumer API
应用程序通过Consumer API,向Kafka集群订阅一个或多个Topic的消息,并处理这些Topic下接收到的消息。 -
Streams API
应用程序通过使用Streams API充当流处理器(Stream Processor),从一个或者多个Topic获取输入流,并生产一个输出流到一个或者多个Topic,能够有效地将输入流进行转变后变成输出流输出到Kafka集群。 -
Connect API
允许应用程序通过Connect API构建和运行可重用的生产者或者消费者,大数据培训能够把kafka主题连接到现有的应用程序或数据系统。Connect实际上就做了两件事情:使用Source Connector从数据源(如:DB)中读取数据写入到Topic中,然后再通过Sink Connector读取Topic中的数据输出到另一端(如:DB),以实现消息数据在外部存储和Kafka集群之间的传输。
Kafka架构
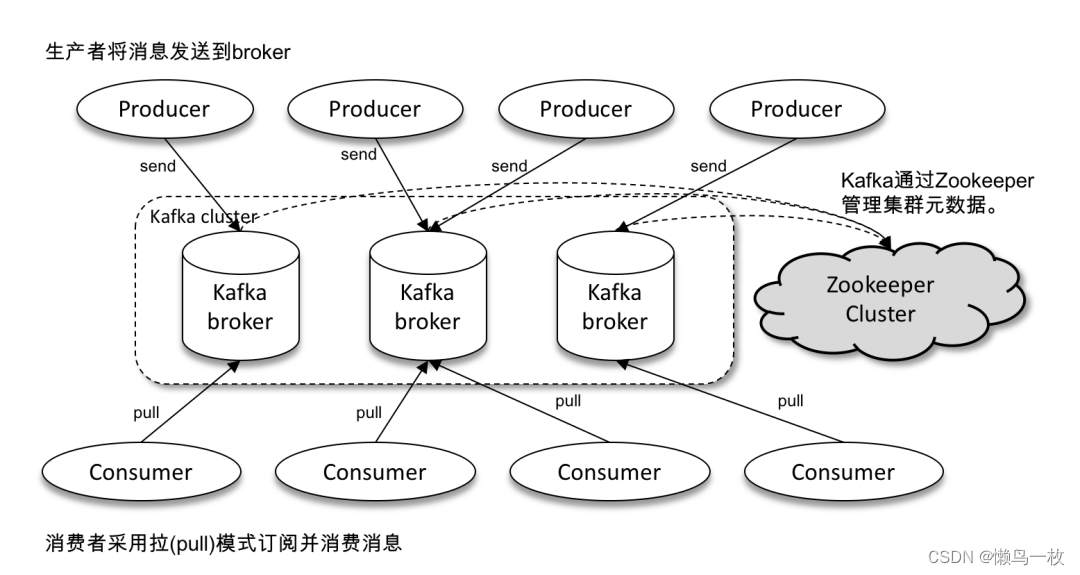
接下来我们将从Kafka的架构出发,重点介绍Kafka的主要组件及实现原理。Kafka支持消息持久化,消费端是通过主动拉取消息进行消息消费的,订阅状态和订阅关系由客户端负责维护,消息消费完后不会立刻删除,会保留历史消息,一般默认保留7天,因此可以通过在支持多订阅者时,消息无需复制多分,只需要存储一份就可以。下面将详细介绍每个组件的实现原理。
1. Producer
Producer是Kafka中的消息生产者,主要用于生产带有特定Topic的消息,生产者生产的消息通过Topic进行归类,保存在Kafka 集群的Broker上,具体的是保存在指定的partition 的目录下,以Segment的方式(.log文件和.index文件)进行存储。
2. Consumer
Consumer是Kafka中的消费者,主要用于消费指定Topic的消息,Consumer是通过主动拉取的方式从Kafka集群中消费消息,消费者一定属于某一个特定的消费组。
3. Topic
Kafka中的消息是根据Topic进行分类的**,Topic是支持多订阅的,一个Topic可以有多个不同的订阅消息的消费者。Kafka集群Topic的数量没有限制,同一个Topic的数据会被划分在同一个目录下,一个Topic可以包含1至多个分区,所有分区的消息加在一起就是一个Topic的所有消息**。
4. Partition
在Kafka中,为了提升消息的消费速度,可以为每个Topic分配多个Partition,这也是就之前我们说到的,Kafka是支持多分区的。默认情况下,一个Topic的消息只存放在一个分区中。Topic的所有分区的消息合并起来,就是一个Topic下的所有消息。每个分区都有一个从0开始的编号,每个分区内的数据都是有序的,但是不同分区直接的数据是不能保证有序的,大数据培训因为不同的分区需要不同的Consumer去消费,每个Partition只能分配一个Consumer,但是一个Consumer可以同时一个Topic的多个Partition。
Replica机制
Kafka 为分区引入了多副本(Replica)机制,通过增加副本数量可以提升容灾能力。同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中 leader 副本负责处理读写请求,follower 副本只负责与 leader 副本的消息同步。当 leader 副本出现故障时,从 follower 副本中重新选举新的 leader 副本对外提供服务。
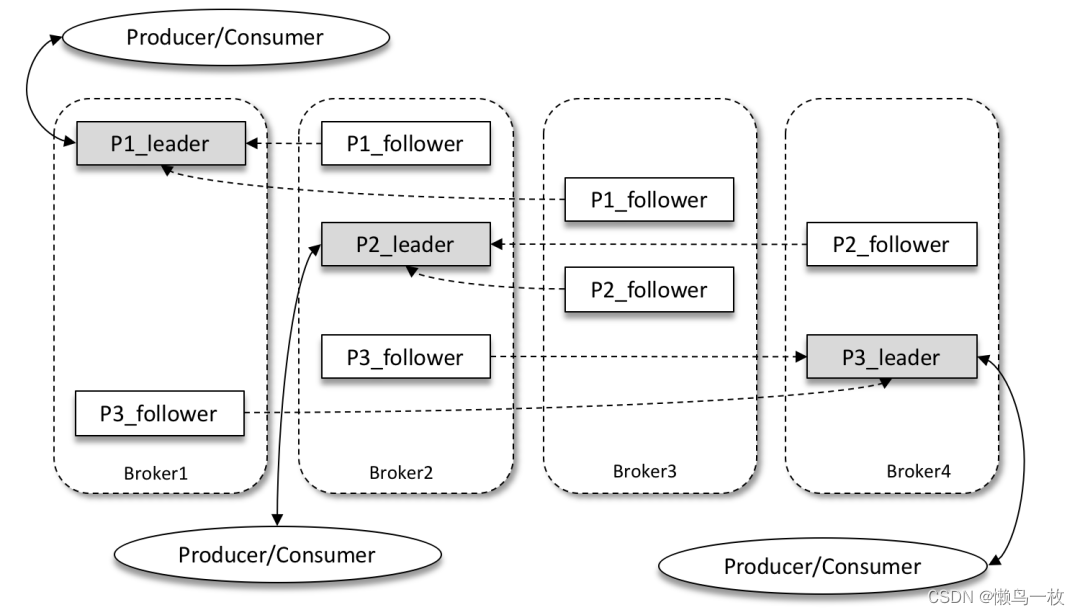
如上图所示,Kafka 集群中有4个 broker,某个主题中有3个分区,且副本因子(即副本个数)也为3,如此每个分区便有1个 leader 副本和2个 follower 副本。
5. Consumer Group
Kafka中的每一个Consumer都归属于一个特定的Consumer Group,如果不指定,那么所有的Consumer都属于同一个默认的Consumer Group。Consumer Group由一个或多个Consumer组成,同一个Consumer Group中的Consumer对同一条消息只消费一次。每个Consumer Group都有一个唯一的ID,即Group ID,也称之为Group Name。Consumer Group内的所有Consumer协调在一起订阅一个Topic的所有Partition,且每个Partition只能由一个Consuemr Group中的一个Consumer进行消费,但是可以由不同的Consumer Group中的一个Consumer进行消费。如下图所示:
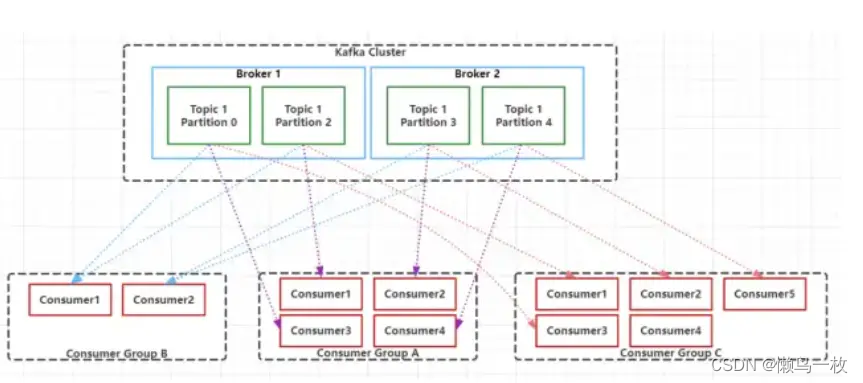
在层级关系上来说Consumer好比是跟Topic对应的,而Consumer就对应于Topic下的Partition。Consumer Group中的Consumer数量和Topic下的Partition数量共同决定了消息消费的并发量,且Partition数量决定了最终并发量,因为一个Partition只能由一个Consumer进行消费。当一个Consumer Group中Consumer数量超过订阅的Topic下的Partition数量时,Kafka会为每个Partition分配一个Consumer,多出来的Consumer会处于空闲状态。当Consumer Group中Consumer数量少于当前定于的Topic中的Partition数量是,单个Consumer将承担多个Partition的消费工作。如上图所示,Consumer Group B中的每个Consumer需要消费两个Partition中的数据,而Consumer Group C中会多出来一个空闲的Consumer4。总结下来就是:同一个Topic下的Partition数量越多,同一时间可以有越多的Consumer进行消费,消费的速度就会越快,吞吐量就越高。同时,Consumer Group中的Consumer数量需要控制为小于等于Partition数量,且最好是整数倍:如1,2,4等。
6. Segment
考虑到消息消费的性能,Kafka中的消息在每个Partition中是以分段的形式进行存储的,即每1G消息新建一个Segment,每个Segment包含两个文件:.log文件和.index文件。之前我们已经说过,.log文件就是Kafka实际存储Producer生产的消息,而.index文件采用稀疏索引的方式存储.log文件中对应消息的逻辑编号和物理偏移地址(offset),以便于加快数据的查询速度。.log文件和.index文件是一一对应,成对出现的。下图展示了.log文件和.index文件在Partition中的存在方式。
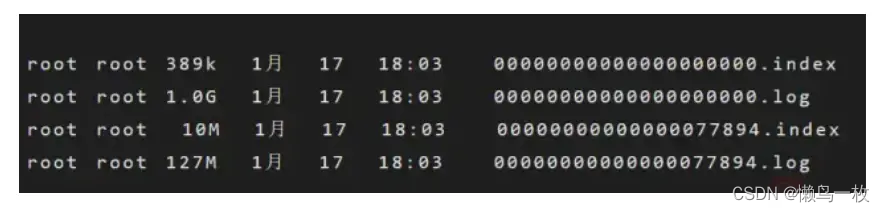
Kafka里面每一条消息都有自己的逻辑offset(相对偏移量)以及存在物理磁盘上面实际的物理地址便宜量Position,也就是说在Kafka中一条消息有两个位置:offset(相对偏移量)和position(磁盘物理偏移地址)。在kafka的设计中,将消息的offset作为了Segment文件名的一部分。Segment文件命名规则为:Partition全局的第一个Segment从0开始,后续每个segment文件名为上一个Partition的最大offset(Message的offset,非实际物理地偏移地址,实际物理地址需映射到.log中,后面会详细介绍在.log文件中查询消息的原理)。数值最大为64位long大小,由20位数字表示,前置用0填充。

上图展示了.index文件和.log文件直接的映射关系,通过上图,我们可以简单介绍一下Kafka在Segment中查找Message的过程:
1.根据需要消费的下一个消息的offset,这里假设是7,使用二分查找在Partition中查找到文件名小于(一定要小于,因为文件名编号等于当前offset的文件里存的都是大于当前offset的消息)当前offset的最大编号的.index文件,这里自然是查找到了00000000000000000000.index。
2.在.index文件中,使用二分查找,找到offset小于或者等于指定offset(这里假设是7)的最大的offset,这里查到的是6,然后获取到index文件中offset为6指向的Position(物理偏移地址)为258。
3.在.log文件中,从磁盘位置258开始顺序扫描,直到找到offset为7的Message。
至此,我们就简单介绍完了Segment的基本组件.index文件和.log文件的存储和查询原理。但是我们会发现一个问题:.index文件中的offset并不是按顺序连续存储的,为什么Kafka要将索引文件设计成这种不连续的样子?这种不连续的索引设计方式称之为稀疏索引,Kafka中采用了稀疏索引的方式读取索引,kafka每当.log中写入了4k大小的数据,就往.index里以追加的写入一条索引记录。使用稀疏索引主要有以下原因:
(1)索引稀疏存储,可以大幅降低.index文件占用存储空间大小。
(2)稀疏索引文件较小,可以全部读取到内存中,可以避免读取索引的时候进行频繁的IO磁盘操作,以便通过索引快速地定位到.log文件中的Message。
7. Message
Message是实际发送和订阅的信息是实际载体,Producer发送到Kafka集群中的每条消息,都被Kafka包装成了一个Message对象,之后再存储在磁盘中,而不是直接存储的。Message在磁盘中的物理结构如下所示。
On-disk format of a message
offset : 8 bytes
message length : 4 bytes (value: 4 + 1 + 1 + 8(if magic value > 0) + 4 + K + 4 + V)
crc : 4 bytes
magic value : 1 byte
attributes : 1 byte
timestamp : 8 bytes (Only exists when magic value is greater than zero)
key length : 4 bytes
key : K bytes
value length : 4 bytes
value : V bytes
其中key和value存储的是实际的Message内容,长度不固定,而其他都是对Message内容的统计和描述,长度固定。因此在查找实际Message过程中,磁盘指针会根据Message的offset和message length计算移动位数,以加速Message的查找过程。之所以可以这样加速,因为Kafka的.log文件都是顺序写的,往磁盘上写数据时,就是追加数据,没有随机写的操作。
8.Partition Replicas
最后我们简单聊一下Kafka中的Partition Replicas(分区副本)机制,0.8版本以前的Kafka是没有副本机制的。创建Topic时,可以为Topic指定分区,也可以指定副本个数。kafka 中的分区副本如下图所示:
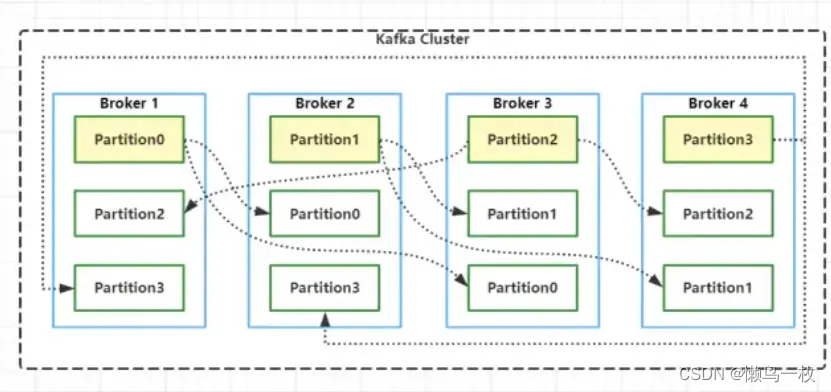
Kafka通过副本因子(replication-factor)控制消息副本保存在几个Broker(服务器)上,一般情况下副本数等于Broker的个数,且同一个副本因子不能放在同一个Broker中。副本因子是以分区为单位且区分角色;主副本称之为Leader(任何时刻只有一个),从副本称之为 Follower(可以有多个),处于同步状态的副本叫做in-sync-replicas(ISR)。Leader负责读写数据,Follower不负责对外提供数据读写,只从Leader同步数据,消费者和生产者都是从leader读写数据,不与follower交互,因此Kafka并不是读写分离的。同时使用Leader进行读写的好处是,降低了数据同步带来的数据读取延迟,因为Follower只能从Leader同步完数据之后才能对外提供读取服务。
如果一个分区有三个副本因子,就算其中一个挂掉,那么只会剩下的两个中,选择一个leader,如下图所示。但不会在其他的broker中,另启动一个副本(因为在另一台启动的话,必然存在数据拷贝和传输,会长时间占用网络IO,Kafka是一个高吞吐量的消息系统,这个情况不允许发生)。如果指定分区的所有副本都挂了,Consumer如果发送数据到指定分区的话,将写入不成功。Consumer发送到指定Partition的消息,会首先写入到Leader Partition中,写完后还需要把消息写入到ISR列表里面的其它分区副本中,写完之后这个消息才能提交offset。
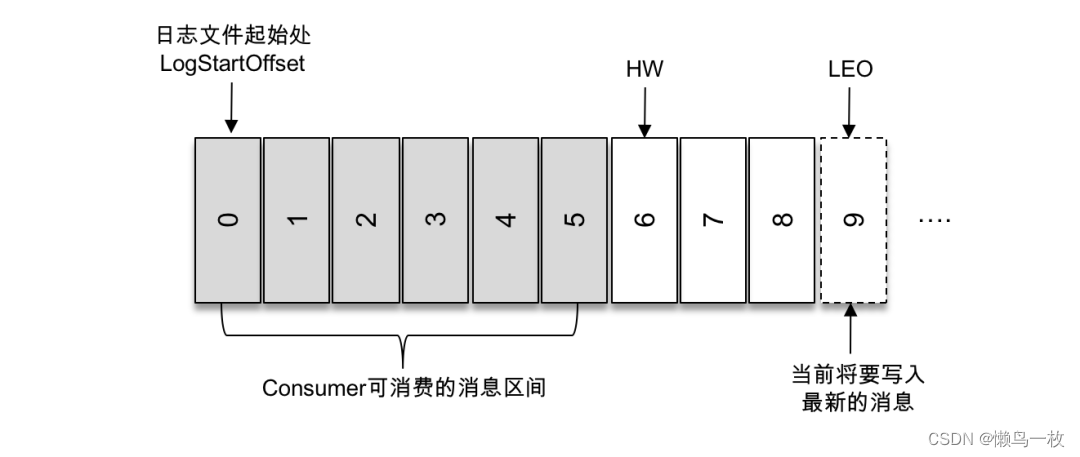
如上图所示,第一条消息的 offset(LogStartOffset)为0,最后一条消息的 offset 为8,offset 为9的消息用虚线框表示,代表下一条待写入的消息。日志文件的 HW 为6,表示消费者只能拉取到 offset 在0至5之间的消息,而 offset 为6的消息对消费者而言是不可见的。
数据同步
分区中的所有副本统称为 AR(Assigned Replicas)。所有与 leader 副本保持一定程度同步的副本(包括 leader 副本在内)组成ISR(In-Sync Replicas),ISR 集合是 AR 集合中的一个子集。
与 leader 副本同步滞后过多的副本(不包括 leader 副本)组成 OSR(Out-of-Sync Replicas),由此可见,AR=ISR+OSR。在正常情况下,所有的 follower 副本都应该与 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合为空。
Leader 副本负责维护和跟踪 ISR 集合中所有 follower 副本的滞后状态,当 follower 副本落后太多或失效时,leader 副本会把它从 ISR 集合中剔除。默认情况下,当 leader 副本发生故障时,只有在 ISR 集合中的副本才有资格被选举为新的 leader。
HW 是 High Watermark 的缩写,俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息。
LEO 是 Log End Offset 的缩写,它标识当前日志文件中下一条待写入消息的 offset。
linux 服务下创建分区
去服务器kafka文件夹下创建相应的kafka topic,创建命令如下:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor ${n} --partitions ${m} --topic ${topic},
其中:
${n}→副本个数,kafka单机情况下为1,集群一般为3;
${m}→分区个数,一般为10;
${topic}→需要创建的topic:(BAYONET_VEHICLEPASS_NOTIFY_JSON_TOPIC、XSINK_PLATE_ALARM_NOTIFY、XSINK_PERSON_NOTIFY_ALARM、ORIGIN_BAYONET_VEHICLEPASS_NOTIFY_JSON_TOPIC)
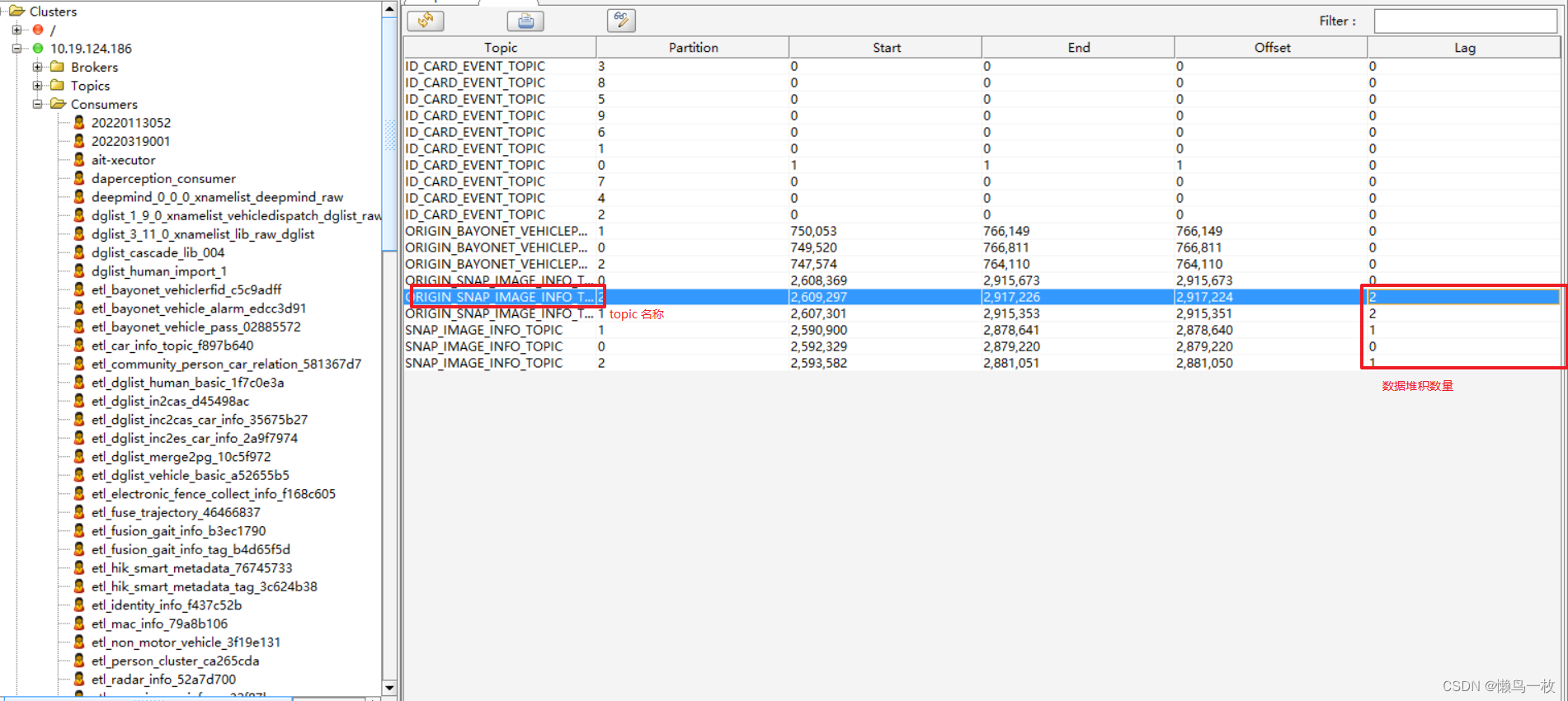
Kafka Tool 简单使用
在这里插入图片描述














 1976
1976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









