







学习笔记

fputc或者read函数完成拷贝,拷贝就是完成向磁盘写东西。
由用户空间进入内核空间,借助驱动去驱动磁盘工作。
fputc的话,没有办法直接进入内核,应该向下调用write,因为只用系统调用才能进入系统内核空间,进入内核以后,才有办法去调用驱动层,最终驱动硬件工作。
如果直接通过write进内核,再去调用驱动,写磁盘,从这种角度看,write似乎比fputc效率更高。
使用系统函数read/write 完成拷贝的程序如下:
$cat read_cmp_getc.c
#include<stdio.h>
#include<unistd.h>
#include<fcntl.h>
#include<stdlib.h>
#define N 1
int main(void)
{
int fd, fd_out;
int n;
char buf[n];
fd = open("dict.txt",O_RDONLY);
if(fd < 0)
{
perror("open dict.txt error");
exit(1);
}
fd_out = open("dict.cp",O_WRONLY|O_CREAT|O_TRUNC,0664);
if(fd<0)
{
perror("open dict.cp error");
exit(1);
}
while((n = read(fd,buf,N)))
{
if(n ==-1)
{
perror("read error");
exit(1);
}
write(fd_out,buf,n);
}
close(fd);
close(fd_out);
return 0;
}使用库函数fputc/fgetc完成拷贝的程序如下:
$cat getc_cmp_read.c
#include<stdio.h>
#include<stdlib.h>
int main(void)
{
FILE *fp,*fp_out;
int n;
fp = fopen("dict.txt","r");
if(NULL== fp)
{
perror("fopen dict.txt error");
exit(1);
}
fp_out = fopen("dict.cp","w");
if(fp_out == NULL)
{
perror("fopen dict.cp error");
exit(1);
}
while((n = fgetc(fp)) != EOF)
{
fputc(n,fp_out);
}
fclose(fp);
fclose(fp_out);
return 0;
}
后面实际发现使用fputc/fgetc完成拷贝的时间比系统调用函数read/read要短的多
(判断方法:执行各自可执行文件的时候,光标闪烁的时间)
为什么?
strace命令
通过该命令跟踪程序执行的时候,调用的系统调用
同过read/write的系统调用的函数
$strace ./read_cmp_getc
write(4, "o", 1) = 1
read(3, "o", 1) = 1
write(4, "o", 1) = 1
read(3, "o", 1) = 1
可以发现都是读一个字节写一个字节。
通过fputc/fgetc的
$strace ./getc_cmp_readread(3, "hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh"..., 4096) = 4096
write(4, "dskhjfdsfsdaofsdkhfhsdfllkjdsgjl"..., 4096) = 4096
read(3, "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"..., 4096) = 4096
write(4, "hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh"..., 4096) = 4096
read(3, "pppppppppppppppppppppppppppppppp"..., 4096) = 4096
write(4, "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"..., 4096) = 4096
read(3, "dddddddddddddddddddddddddddddddd"..., 4096) = 4096
write(4, "pppppppppppppppppppppppppppppppp"..., 4096) = 4096
read(3, "uuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu"..., 4096) = 4096
write(4, "dddddddddddddddddddddddddddddddd"..., 4096) = 4096
一次读写4K.
所以速度快很多。
为什么会这样?
预读入缓输出

用户程序:read/write fputc/fgetc
都有一个buffer,read/write指定为1个字节
write的时候,会一个一个字节的写入内核buf
内核buf默认大小为4K.内存缓存满了,就一次性写入磁盘。
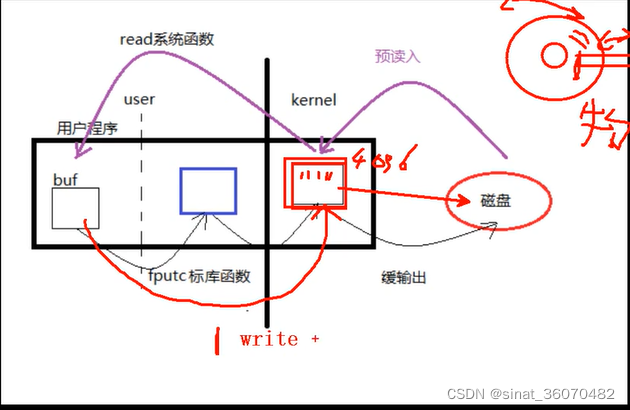
中间黑线代表内核区和用户区的隔分,要向跨越这条线,必须要系统调用完成。
每一次跨越(进入),相当耗时。当然比磁盘访问(物理操作)时间要短。
所以read/write慢,是慢在要反复在用户区和内核区来回跳。
且每次一个字节。
但是fputc/fgetc虽然也要从用户区和内核区来回跳,但是不是一次往里写一个字节。
相当于说在fputc函数内部有一个buff(蓝色)大小默认也是4K,所以要满4K后,然后再进内核。
缓冲区:
read/write函数常常被称为Unbuffered I/O(就是蓝色框框的意思)。指的是无用户级缓冲区。但是不保证不使用内核缓冲区。
当然我们也可以重新制定read/write的大小,那个是最左边黑色的框框。
刚才讲的是缓输出。
现在说预读入:
比如从磁盘读取数据到内核空间buff,也不是只读一个字节。操作系统会尽可能多的从磁盘到达
内核缓冲区里面。
摒除误区:系统函数比库函数高大上。系统函数的效率一定比库函数效率高。
结论:即使我们学了系统调用,但是如果能使用库函数的地方,尽量使用库函数。
但是如果有不想用缓输出的机制的时候(比如即时消息的时候),不要使用库函数。
要根据实际情况而定。















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









