







python-docx读取word字体信息为None
记录一下使用python-docx吧。
最近使用python-docx读取docx文件,想要读取文件的字体等信息。查到的资料有点杂,而且好多都是教你怎么写入一个docx文件的……
官方文档中说了关于样式继承的问题:
一个样式可以从另一个样式继承属性,有点类似于层叠样式表 (CSS) 的工作方式。base_style使用属性指定继承 。通过将一种风格建立在另一种风格上,可以形成任意深度的继承层次结构。没有基本样式的样式会从文档默认值继承属性。
许多字体属性是三态的,这意味着它们可以采用值 True、False和None。True表示该属性是“on”,False表示它是“off”。从概念上讲,None价值意味着“继承”。
也就是说,当文档中某些内容应用了样式时,一些信息返回的值为None。
接下来讲一下文档应用了样式,怎么得到paragraphs的字体信息。
首先,安装库:
在终端输入:(网速慢建议使用镜像源)
pip install python-docx
# 豆瓣镜像源
# pip install -i https://pypi.doubanio.com/simple python-docx
使用
加载相应的库
import docx
from docx.oxml import parse_xml
from docx.oxml.xmlchemy import serialize_for_reading
from docx.oxml.ns import nsmap, qn
# 读取docx文件
doc = docx.Document('test.docx')
将docx文件解析为xml文件,通过xml文件获取文档信息。文档解析后会有多个xml文件,一般是document.xml中获取文档信息,样式信息则会在style.xml中。因此可以通过解析样式信息来获取字体信息。
p.style.font.name有时也可以获取样式的英文字体名称。
获取中文字体名称
for p in doc.paragraphs:
# print("段落内容:", p.text)
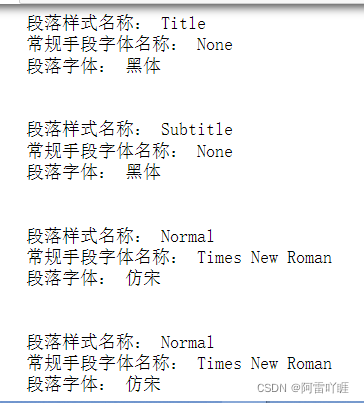
print("段落样式名称:", p.style.name)
print('常规手段字体名称:', p.style.font.name)
p_rpr = p.style.element.xpath('w:rPr')[0]
# print(p_rpr[0].xml)
if p_rpr.xpath('w:rFonts'):
try:
# 一般字体在w:ascii中,中文样式的字体可能在w:eastAsia
# 找不到的话print一下p_rpr[0].xml找找关于字体信息在哪
print("段落字体:", p_rpr.xpath('w:rFonts')[0].attrib[qn("w:eastAsia")])
except:
print("段落字体:", p_rpr.xpath('w:rFonts')[0].attrib[qn("w:ascii")])
得到的结果:

















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









