







压缩,是为了减少存储空间而把数据转换成比原始格式更紧凑形式的过程。数据压缩的概念相当古老,可以追溯到发明了摩尔斯码的19世纪中期。
摩尔斯码的发明,是为了使电报员能够通过电报系统,利用一系列可听到的脉冲信号传递字母信息,从而实现文字消息的传输。摩尔斯码的发明者意识到,某些字母比其他字母使用地更频繁(例如E比X更常见),因此决定使用短的脉冲信号来表示常用字母,而使用较长的脉冲信号表示非常用字母。这个基本的压缩方案有效地改善了系统的整体效率,因为它使电报员在更短的时间内传输了更多的信息。
虽然现代的压缩流程比摩尔斯码要复杂地多,但是它们仍然使用着相同的基本原理,也就是我们这篇文章中将要讲述的内容。这些概念对我们如今的计算机世界高效运行至关重要——互联网上从本地与云端存储到数据流的一切东西都严重依赖压缩算法,离开了它很可能会变得非常低效。
压缩管道
下图展示了压缩方案的通用流程。原始的输入数据包含我们需要压缩或减小尺寸的符号序列。这些符号被压缩器编码,输出结果是编码过的数据。需要注意的是,虽然通常编码后的数据要比原始输入数据小,但是也有例外情况(我们后面会讲到)。

通常在之后的某个时间,编码后的数据会被输入到一个解压缩器,在这里数据被解码、重建,并以符号序列的形式输出原始数据。注意,本文我们会交替地使用“序列”和“串”来指一个符号序列集。
如果输出数据和输入数据始终完全相同,那么这个压缩方案被称为无损的,也称无损编码器。否则,它就是一个有损的压缩方案。
- 无损压缩方案通常被用来压缩文本,可执行程序,或者其他任何需要完全重建数据的地方。
- 有损压缩方案在图像,音频,视频,或者其他为了提高压缩效率而可以接受某些程度信息丢失的场合很有用处。
数据模型
信息的定义是度量一个数据片段复杂度的量。一个数据集拥有越多的信息,它就越难被压缩。稀有的概念和信息的概念是相关的,因为稀有符号的出现比常见符号的出现提供了更多的信息。
例如,“日本的一次地震”的出现比“月球的一次地震”提供的信息号少,因为月球上的地震很不常见。我们可以预期,大多数压缩算法在压缩一个符号时,能够仔细地考虑它出现的频率或几率。
我们把压缩算法降低信息负载的有效性,称为它的效率。一个效率更高的压缩算法相比效率低的压缩算法,能够更多地降低特定数据集的大小。
概率模型
设计一个压缩方案的最重要一步,是为数据创建一个概率模型。这个模型允许我们测量数据的特征,达到有效的适应压缩算法的目的。为了使它更加清晰一些,让我们浏览一下建模过程的部分环节。
假设我们有一个字母表G,它由数据集中所有可能出现的字符组成。在我们的例子中,G包含4个字符:从A到D。
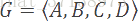
我们还有一个概率统计函数P,它定义了在输入数据串中,G中每个字符出现的概率。在输入数据串中,概率高的符号比概率低的符号更有可能出现。
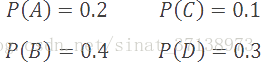
在这个例子中,我们假定符号是独立同分布的。在源数据串中,一个符号的出现与其他任何符号没有相关性。
最小编码率
B是最常见的符号,出现的概率是40%;而C是最不常见的符号,它的出现概率只有10%。我们的目标是设计一个压缩方案,它对于常见符号使所需存储空间最小化,同时它支持使用更多的必要空间来存储不常见符号。这个折衷是压缩的基本原理,并且已经存在于几乎所有的压缩算法中。
有了字母表,我们可以小试身手,来定义一个基本的压缩方案。如果我们简单地把一个符号编码为8比特的ASCII值,那么我们的压缩效率,即编码率,将是8比特/符号。假定我们对只包含4个符号的字母表改进这个方案。如果我们为每个符号分配2个比特,我们仍然能够完全重建编码过的数据串,而只需要1/4的空间。
ASCII
在计算机中,所有的数据在存储和运算时都要使用二进制数表示(因为计算机用高电平和低电平分别表示1和0),例如,像a、b、c、d这样的52个字母(包括大写)、以及0、1等数字还有一些常用的符号(例如*、#、@等)在计算机中存储时也要使用二进制数来表示,而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码,统一规定了上述常用符号用哪些二进制数来表示。
它是现今最通用的单字节编码系统。
这时候,我们已经显著地提升了编码率(从8到2比特/符号),但是完全忽视了我们的概率模型。正如前面提到的,我们可以结合模型发明一个策略,通过对常见符号(B和D)使用更少的比特,对不常见符号(A和C)使用更多的比特,以提高编码效率。
这提出了一个在香农开创性论文中描述的重要观点——我们可以简单地基于符号(或事件)的概率,定义它的理论最小存储空间。我们如下定义一个符号的最小编码率:
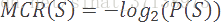
例如,如果一个符号出现的概率是50%,那么它绝对最少需要一个字节来存储。
熵和冗余
更进一步,如果我们为字母表中的字符计算最小编码率的加权平均值,我们得到一个被称作香农熵的值,简单地称作模型的熵。熵被定义为给定模型的最小编码率。它建立在字母表和它的概率模型之上,如下描述。
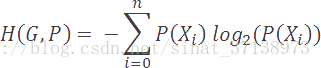
正如你预料的一样,拥有更多罕见符号的模型,比拥有较少并且常见符号的模型的熵要高。更进一步,熵值更高的模型比熵值低的模型更难压缩。
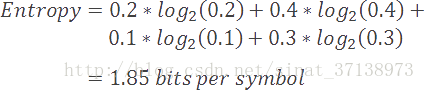
在我们当前的例子中,我们模型的熵值是1.85比特/符号。编码率(2)和熵值(1.85)的差值被称作压缩方案的冗余。
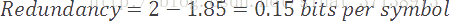
在众多诸如加密和人工智能等不同的子领域,熵都是一个非常有用的话题。
编码模型
到目前为止,我们采取了一点点自由措施:自动地给出了我们符号的概率。在现实中,模型通常并不是容易得到的,我们可能通过分析源数据串(如在样例数据汇总统计符号概率),或者在压缩过程中自适应地学习,以得到这些概率值。不管是哪种情形,真实数据串的概率值不会完美地与模型匹配,而且我们会与这个差别正比例地损失压缩效率。基于这个原因,推导出(或恒定地保持)一个尽可能精确的模型是至关重要的。
常见算法
当我们为数据集定义了概率模型之后,我们就能够适当地利用这个模型设计出一个压缩方案。虽然开发一个新压缩算法的过程超出了本文的范围,但是我们可以利用已经存在的算法。下面我们回顾一些最流行的算法。
下面的每一个算法都是一个顺序处理器,这就是说如果要重建已编码序列的第n个符号,必须先对第0..(n-1)个符号进行解码。由于编码后数据的不定长特性,寻找操作是不可能的——解码器在不解码前面的符号的情况下,无法直接跳转到符号n的正确偏移位置。另外,一些编码方案依赖于顺序处理每个符号时保持的内部历史状态。
霍夫曼编码
这是一个最为广泛知晓的压缩方案。它能够追溯到19世纪50年代,David Huffman在他的论文“一种构建极小多余编码的方法”中第一次描述了这种方法。霍夫曼编码通过得到给定字母表的最优前缀码工作。
一个前缀码代表一个数值,并使字母表中的每个符号的前缀码不会成为另一个符号前缀码的前缀。例如,如果0是我们第一个符号A的前缀码,那么字母表中的其他符号都不能以0开始。由于前缀码使比特流解码变得清晰明确,因此很有用。
字典方法
这种类型的编码器使用一个字典来保存最近发现的符号。当遇到一个符号时,首先会在字典中查找它,检查是否已经存储过了。如果是,那么输出将只包含字典入口的引用(通常是一个偏移量),而不是整个符号。
使用字典方法的压缩方案包括LZ77 and LZ78,它们是很多不同的无损压缩方案的基础。
在一些情况下,会使用一个滑动窗口来自适应地追踪最近发现的符号。这种情况下,一个符号只在相对较近发现时才会保存在字典中。否则,符号被剔除(之后再出现可能会重新加入字典)。这个过程防止符号字典变得过大,并利用了一个事实,即序列中的符号会在相对短的窗口内重复出现。
哥伦布指数编码
假设你有一个由0到255范围内的整数组成的字母表,并且一个符号的出现概率与它到0的距离有关。这样,比较小的值是最常见的,而值越大出现的概率越小。
和大多数压缩方案一样,哥伦布编码的效率非常依赖于输入序列中的特定符号。包含很多大值的序列与包含较少大值的序列相比,压缩效果更差一些;在某些情况下,经过哥伦布编码后的序列甚至可能比原始输入串的尺寸更大。
算数编码
算数编码是一个比较新的压缩算法,在最近(过去的15年里)得到了极大的普及,特别是媒体压缩方面。算数编码器是一种高效率,计算密集型,具有时序性的编码器。
一个常见的算数编码变种,二进制算数编码,使用只包含两个符号(0和1)的字母表。这个变种特别有用处,因为它简化了编码器的设计,降低了运行时的计算代价,并且在编码器和解码器处理一个字母表和模型时,不需要任何显式的通讯。
行程长度编码
到现在为止,我们已经假设源符号是独立同分布的。我们的概率模型和编码率与熵的计算方法都依赖于这个事实。但是,如果我们的符号序列不满足这个要求呢?
假设我们序列中符号的重复度很高,并且一个特定符号的出现有力地表明,它的重复实例即将跟随出现。这种情况下,我们可以选择使用另一个称作行程长度编码的编码方案。这种技术在符号重复度很高时表现良好,而在重复度低时表现较差。
行程长度编码器预测数据串中连续重复符号的长度,并使用这个符号和重复次数来替代它们。















 5795
5795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









