







论文链接
code暂时未开源
这是一篇异常检测方向的paper;ICCV2019已收录。

论文背景
目前视觉中基于无监督学习的异常检测主要为编码器-解码器结构,仅训练正常样本,希望测试阶段的正常样本有较低的reconstruction error,而输入的异常样本reconstruction error超过一定阈值。但是这样的假设实际工作中常常不work,因为AE(autoencoder)可能效果太好(sometimes the AE can “generalize” so well that it can also reconstruct the abnormal inputs well)导致输入异常样本后仍然能够很好地重建出异常样本,也就是说reconstruction error不会异常,即无法检测异常。
架构简介
简单地说,一个输入图像并不会直接经过encoder-decoder,而是利用encoder得到的潜在空间检索memory中最相关的项,这些项随后被整合并进入decoder。

MemAE总体思想原理呈现在上图中。图中encoder与decoder不是本文的讨论范围,根据实际情况自行选取。
在只对正常样本的数据集进行训练后,MemAE中的内存记录了典型的正常模式。给定异常输入,MemAE检索内存中最相关的正常模式进行重建,结果输出与异常输入显著不同。为了简化可视化,我们假设这里只处理一个内存项。
上述的处理过程实际上是使用了基于注意力机制的记忆处理(attention based memory addressing)。同时作者还提出了一种可微的难压缩操作(hard shrinkage operator) ,使得记忆处理权重有一定的稀疏性,从而记忆项接近特征空间中的query。
训练阶段:更新编解码器以及memory的内容,由于采用稀疏寻址策略,MemAE模型被鼓励以最优和有效的方式使用有限的内存槽,使得内存能够记录正常训练数据中的原型正常模式(prototypical normal patterns),从而获得较低的平均重建误差reconstruction error。
测试阶段:所学习的记忆内容是固定的,通过使用少量的正常记忆项(normal memory items)来进行重建,这些正常记忆项被选择为输入编码的邻域。由于重建是在内存中获得的正常模式,所以它往往接近于正常数据。
综上所述,本文模型总体pipeline为:
- encoder:由输入 x x x得到 z z z
- attention based memory addressing: z z z稀疏寻址得到 w w w
- hard shrinkage operator: w w w离散为 w ^ \hat{w} w^
- w ^ \hat{w} w^ 通过memory矩阵 M M M映射为与 z z z相同维度的 z ^ \hat{z} z^
- decoder
配上示意图:

下文就是解读中间这两部分。
Attention-based memory addressing
分为两部分:
- memory module:记录了有限个数的编码记忆原型
- Attention-based memory addressing:如何将encoder的结果映射到memory中
首先,memory存储在矩阵
M
M
M中, M的维度[N,C]。
m
i
m_{i}
mi代表
M
M
M的每一行,即每一个memory item。
要寻址,即将encoder的结果
Z
Z
Z映射到memory,变为
w
w
w,方法为:
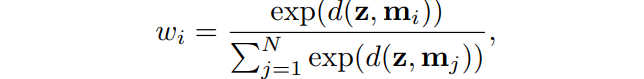
d
d
d表示余弦距离:
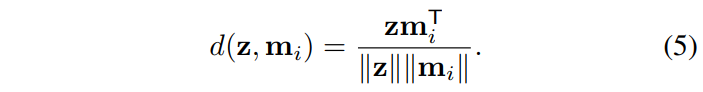
hard shrinkage operator
作者发现,一些异常可能仍然有机会通过memory items的复杂组合(也就是稠密的
w
w
w)很好地重建。为了缓解这个问题,作者采用了hard shrinkage operator来提高
w
w
w的稀疏性。进行了类似Relu的Hard Shrinkage约束,其实就是超过阈值才保留,不超过阈值就是0。
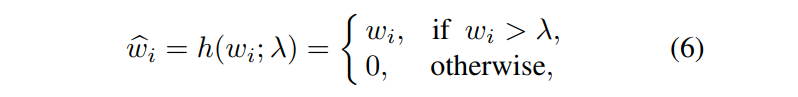
为了能够计算梯度,结合Relu做了一点调整。
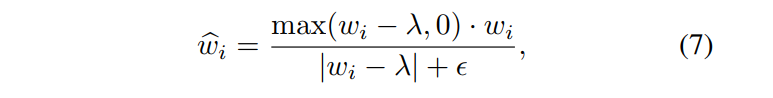
最后还要还原到与潜在空间(latent representation)
z
z
z维度相同的
z
^
\hat{z}
z^。
其中
z
^
=
w
^
M
\hat{z}=\hat{w}M
z^=w^M。














 318
318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









