







论文地址:
https://arxiv.org/abs/1611.07004v3
代码地址:
https://github.com/phillipi/pix2pix
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
https://github.com/TeeyoHuang/pix2pix-pytorch
补充材料:
https://phillipi.github.io/pix2pix/
https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/
https://people.eecs.berkeley.edu/~isola/
论文翻译

摘要
我们研究条件对抗网络作为image-to-image转义问题的通用解决方案。这个网络不仅从输入图片到输出图片中学习映射, 而且学习了一个损失函数来训练这个映射。我们证明了这个方法可以有效的在标签映射(label maps)中合成(synthesizing)图片,从边缘映射(edge maps)中重构(reconstructing)物体,并且能够在其它任务中对图片着色。自从与本文相关的pix2pix软件发布以来,大量互联网用户(其中许多是艺术家)已经在我们的系统中发布了自己的实验,进一步证明了其广泛的适用性和易于采用,而无需参数调整。作为一个社区,我们不再手工设计我们的绘图功能,这项工作表明我们可以在不手工设计损失函数的情况下获得合理的结果。
1. 介绍
将一个输入图片转化成对应的输出图片时,在图片处理、计算图和计算视觉上可以提出许多问题。比如一种观念可以通过英语或者法语表达,一个场景可以通过一个RGB图片,一个梯度领域,一个边缘映射,一个语义标签映射等表示出来。与自动的语言翻译类似,我们设计了图片到图片的转义,通过充足的训练数据,任务就是将一个场景翻译成另外一个可能表示的场景。传统意义上,他们的每一个任务都需要通过特定的机器分别进行处理,尽管他们的设置都是一样的:从一个像素预测另一个像素(predict pixels from pixels).本篇论文中我们的目标是开发一个共同的框架来解决上述问题。

Fig. 1: 图像处理,图形和视觉方面的许多问题都涉及将输入图像转换为相应的输出图像。即使设置始终相同,也通常使用特定于应用程序的算法来解决这些问题:将像素映射到像素。条件对抗网络是一种通用解决方案,似乎可以很好地解决这些问题。这里我们展示几种方法的结果。在每种情况下,我们都使用相同的体系结构和目标,并且仅对不同的数据进行训练。
这里开始讲CNNs,CNNs在各种各样的图片预测问题上发挥了很重要的作用。CNNs学习最小化损失函数(一种计算结果质量的计分方式),尽管CNN的学习过程是自动的,但是仍然需要人工的努力来使得loss更高效。换句话说,我们仍然需要告诉CNN我们想最小化什么。 如果我们采取一种天真的方式(naive approach)要求CNN最小化预测像素和ground truth像素之间的欧氏距离,他可能会趋向于产生模糊的结果(blurry results)。这是因为欧式距离是通过平均所有可能的输出来最小化的,而这就会造成blurring。提出一种能够迫使CNN做我们真正想要的(如输出真正的图片)损失函数,是一个公开的难题。
如果我们能够只设定一个高级目标,比如使输出和现实无法区分,然后自动地学习适合实现这一目标的损失函数,这是非常可取的。 幸运的是,最近提出的GAN已经做了这方面的工作。在GANs中学习的损失能够适应数据,他们可以被应用到多种不同的任务上,而如果使用传统的方法就需要各种不同的损失函数。
在这篇论文中,我们探讨了有条件设置的GANs。就像GANs学习数据的生成模型,cGANs学习有条件的生成模型(conditional generative model)。这就使得cGANs适用于图片到图片的转义任务,我们的条件就是一个输入的图片生成一个对应的输出图片。
GANs在最近两年蓬勃发展,并且本文中探索的一些技术之前已经被提及过。尽管如此,早期的论文关注于特定的应用,如何有效地使条件图片的GANs成为图片到图片转义的通用方法仍然是个问题。 我们的主要贡献就是证明了在多种不同的问题中,条件GANs产生了合理的结果。我们的第二个贡献就是展现了一个简单的框架并且有效的实现了不错的结果,并且分析了几个重要的结构选择。 代码开源在https://github.com/phillipi/pix2pix上面。
2. 相关工作
图像模型的结构化损失 图像到图像的转换问题通常被表示为每个像素分类或回归。这些表达式将输出空间视为非结构化,在某种意义上说,就是每个输出像素都是有条件的独立于所有其它给的输入图片。有条件的GANs会(instead)学习结构化损失。 结构化的损失惩罚输出的联合损失。大量的文献都考虑过这种损失,使用的方法包括条件随机字段[9],SSIM度量[53],特征匹配[13],非参数损失[34],卷积伪先验[54],基于匹配协方差统计的损失和损失[27]。cGAN是不同的,它的损失在理论上可以惩罚输出和目标之间不同的任何可能结构。
Conditional GANs 我们不是第一个在条件设置(conditional setting)中应用将GANs的人。先前和并行的工作已经将GAN置于离散标签[38、21、12],文本[43]以及实际图像上。每种方法都是针对特定应用量身定制的。我们的框架的不同之处在于,没有什么是特定于应用程序的。这使我们的设置比大多数其他设置简单得多。
在生成器和鉴别器的选择方面,我们的方法也不同于先前的工作。我们的生成器使用基于“ U-Net”的体系结构,我们的鉴别器使用的是一个卷积的 “PatchGAN” 分类器,它只惩罚图像补丁规模上(image patch scale)的结构。先前在[35]中提出了类似的PatchGAN架构,它用来捕捉局部特征的统计信息。在这里,我们证明了这种方法对更广泛的问题有效,而且我们调查(investigate)了改变补丁大小的影响。
3. 方法
GANs是一个生成网络,用来学习从随机噪声向量
z
z
z到输出图片
y
y
y的映射,
G
:
z
→
y
G:z\rightarrow y
G:z→y。对比之下,cGANs学习从获得的图片
x
x
x和随机噪声向量
z
z
z到输出图片
y
y
y的映射,
G
:
{
x
,
z
}
→
y
G:\{x, z\}\rightarrow y
G:{x,z}→y。训练流程如Fig. 2所示。


Fig. 2: 训练条件GAN来绘制edges→photo。鉴别器
D
D
D学习在伪造(由生成器合成)和真实
{
e
d
g
e
,
p
h
o
t
o
}
\{edge,photo\}
{edge,photo}元组之间进行分类。生成器
G
G
G学会欺骗鉴别器
D
D
D。与无条件GAN不同,生成器和鉴别器都是可以获得输入的边缘映射的。
3.1 评估
条件GAN的目标可以表示为
L G A N ( G , D ) = E x , y [ l o g D ( x , y ) ] + E x , z [ l o g ( 1 − D ( x , G ( x , z ) ) ) ] L_{GAN}(G, D)=E_{x, y}[logD(x,y)]+E_{x, z}[log(1-D(x, G(x,z)))] LGAN(G,D)=Ex,y[logD(x,y)]+Ex,z[log(1−D(x,G(x,z)))]
其中 G G G的目标是最小化这个目标,而 D D D的目标是最大化这个目标。
G ∗ = a r g min G max D L c G A N ( G , D ) G^*=arg\min_G\max_DL_{cGAN}(G, D) G∗=argGminDmaxLcGAN(G,D)
为了测试条件化鉴别器的重要性,我们还比较了非条件鉴别器,这个鉴别器不观察 x x x变量:
L G A N ( G , D ) = E y [ l o g D ( y ) ] + E x , z [ l o g ( 1 − D ( G ( x , z ) ) ) ] L_{GAN}(G, D)=E_{y}[logD(y)]+E_{x, z}[log(1-D( G(x,z)))] LGAN(G,D)=Ey[logD(y)]+Ex,z[log(1−D(G(x,z)))]
之前的方法已经发现将GAN的目标和一个传统的Loss结合(如 L 2 L_2 L2距离)是有好处的。鉴别器 D D D的工作保持不变,但是生成器 G G G的工作不仅仅是欺骗 D D D,而且在 L 2 L_2 L2-sense上接近ground truth的输出。我们也探索了这个选择,使用 L 1 L_1 L1距离而不是 L 2 L_2 L2距离,因为 L 1 L_1 L1能够减少模糊:
L L 1 ( G ) = E x , y , z [ ∥ y − G ( x , z ) ∥ 1 ] L_{L_1}(G)=E_{x, y, z}[\parallel y - G(x, z)\parallel_1] LL1(G)=Ex,y,z[∥y−G(x,z)∥1]
我们的最终目标是:
G ∗ = a r g min G max D L c G A N ( G , D ) + λ L L 1 ( G ) G^*=arg\min_G\max_DL_{cGAN}(G, D)+\lambda L_{L_1}(G) G∗=argGminDmaxLcGAN(G,D)+λLL1(G)
没有 z z z,网络仍然可以学习从 x x x到 y y y的映射,但是会产生确定性的输出,因此无法匹配除增量函数以外的任何分布。过去的cGANs已经证明这一点,并且提供了一个高斯噪声 z z z作为 G G G的输入,除了 x x x之外。 在最开始的试验中,我们并没有发现有效的策略, G G G只是简单的学会了忽略噪声。进一步,对于我们最后的模型,我们只在dropout结构上提供了噪声,在训练和测试时运用在 G G G的几个层上面。尽管存在dropout的噪声,在我们的网络输出中,只观察到了微弱的随机性(minor stochasticity)。 设计一个能够产生高度随机的cGANs,并且能够捕捉到这个模型状态分布(conditional distribution)的全熵值(full entropy),是当前工作遗留的一个重要问题。
3.2 网络结构
生成器 G G G和鉴别器 D D D都是使用Conv-BatchNorm-ReLu的模型。
3.2.1 Generator with skips
图像到图像转义问题的一个定义性的特征是它们要将一个高分辨率的输入网格映射到一个高分辨率的输出网格上。此外,我们考虑的问题是,输入和输出在表面显示上是不一样的,但是两者都呈现相同的底层结构。因此,输入结构和输出结构在大体上是对齐的。我们设计的 G G G结构就是基于上述考虑。
之前的解决方案大都是使用编码解码网络(encoder-decoder network)。在该网络中,输入通过一系列的层逐步进行下采样,直到进入瓶颈层。这样的网络要求所有的信息(information)通过所有的层,包括瓶颈(bottleneck)。对于许多图像转换问题,在输入和输出中都存在大量的低层次(low-level)信息分享。 直接通过这个网络来传输信息是可取的。比如说,对于图像着色这个例子,输入和输出分享突出边缘的位置(location of prominent edges)。
像这样,为了给
G
G
G一个均值(means)来规避(circumvent)信息瓶颈,我们添加了skip连接,和U-net的大体结构类似。 具体来说,我们在第
i
i
i层和第
n
−
i
n−i
n−i层添加了一个skip连接,
n
n
n是所有层的数量。每一个skip连接就是
i
i
i层和第
n
−
i
n−i
n−i层所有通道的连接。



3.2.2 Markovian discriminator (PatchGAN)
L 2 L_2 L2和 L 1 L_1 L1损失众所周知,它们在图片生成问题中会产生模糊的问题。尽管这些losses不能很好的用在高清晰度图片中,但他们仍然能够正确的捕捉到低频(low frequencies)。在这种情况下的问题,我们不需要整个网络来保证低频的正确性,这就是 L 1 L_1 L1在做的。
这个约束GAN的鉴别器只模拟高频结构,而依靠 L 1 L_1 L1项保证低频的正确性。 为了模拟高频,限制我们在局部图片补丁上的注意力是很有效的。因此,我们设计了一个分辨器结构,我们称之为PatchGAN ,它只惩罚Patch规模下的结构。这个鉴别器试着分辨每一个 N × N N\times N N×N的Patch是真的还是假的,然后平均所有的相应来得到最后的输出 D D D。
在Sec. 4.4中,我们证明了 N N N即使比整个图片的尺寸小很多,依然能够产生高质量的效果。这是一个很大的优点,因为一个更小的PatchGAN意味着更少的参数,更快的速度,以及能够应用到任意图片中。
这样的鉴别器有效地将一个图像建模成一个马尔可夫随机场,假设每个像素之间相互独立,通过一个以上的Patch直径分开。这种连接在论文[38]中有过探索,在texture和风格模型中也是一种通用的假设。因此,我们的PatchGAN也可以被理解成texture/style 损失的一种。
3.3 优化和推理
为了优化我们的网络,我们按照[24]的标准方法:我们选择 G G G和 D D D分开训练。在 G G G的训练中,选择训练最大化 l o g D ( x , G ( x , z ) ) logD(x,G(x,z)) logD(x,G(x,z))而不是最小化 l o g ( 1 − D ( x , G ( x , z ) ) ) log(1−D(x,G(x,z))) log(1−D(x,G(x,z)))。在优化 D D D的时候我们要对目标 ÷ 2 \div2 ÷2,这可以减缓 D D D相对于 G G G的学习率。使用 m i n i b a t c h S G D minibatchSGD minibatchSGD和 A d a m Adam Adam优化。
在验证时,我们采用和训练时一样的方法运行生成网络 G G G。这不同于一般的protocol,我们在测试时使用了 d r o p o u t dropout dropout。我们对测试的batch进行了BatchNorm,而不是对训练的Batch,这个方法中的BatchNorm,当Batch size=1时,被称之为 “instance normalization”,并且被证实能在图片生成任务中有效的工作。 在我们的试验中,我们会根据我们的实验情况在1-10之间设置batch size。
4. 实验
为了探索条件GAN的一般性,我们在各种任务和数据集上测试了该方法,包括图形任务(如照片生成)和视觉任务(如语义分割):

在线补充材料中提供了有关这些数据集的每个培训的详细信息。 在所有情况下,输入和输出都是1-3通道图像。 在线材料(https://phillipi.github.io/pix2pix/)中显示了其他结果和失败案例。
4.1 评估指标
评估合成图像的质量是一个开放性的难题。像MSE这种传统指标,无法评估结果的联合统计信息,因此无法测量结构Loss想要捕获的特定结构。
为了更加整体性的评估我们结果的视觉质量,我们使用两种策略。第一,我们在Amazon Mechanical Turk(AMT)平台上进行了 “真假判别” 的感知调查。对于像图像着色、照片生成这样的图形学问题,可信度通常是人类观察者的终极目标。因此,我们用这种方法测试了地图生成、航空图生成和图像着色任务。第二,我们用现有的对象识别系统测量了合成的街景是否足够真实。这个指标和文献[36]中的“Inception Score”、[39]中的对象检测评估、[46]中的“Semantic Interpretability”的概念比较相似。
- AMT 感知调查
我们的AMT实验使用了[46]中的方案:向Turkers提供一系列真实的图片和我们算法生成的“假冒”的图片。在每次试验中,每幅图片出现 1 s 1s 1s,图片消失后,Turkers需要在规定时间内指出哪一副图片是假的。每轮实验前10张图片用于练习,Turkers会得到正确答案。在主实验中的40次试验中,不会给出答案。每组实验只测试一种算法,Turkers只允许完成一组实验。每个算法大约50个Turkers来测试,所有图像均为 256 × 256 256\times 256 256×256大小。和[46]不同,我们没有包括警惕性测试。对于图片上色实验,真实图片和假冒图片均源自同一张灰度图;对于地图 ↔ \leftrightarrow ↔航空照片,为了提高分辨难度,真实图片和假冒图片不是源自同一输入。
- FCN分数
因为生成模型定量评估的困难性,最近许多工作尝试使用已训练好的语义分类器来测量生成图片的可分辨度。从直观上理解,用真实图片训练的分类器有能力对合成的图片进行正确的分类。为了达到这个目的,我们使用流行的FCN-8s[26]结构做语义分割,并在CityScapes数据集上训练,然后我们根据这些照片合成的标签,通过合成图片的分类准确性为合成照片进行评分。
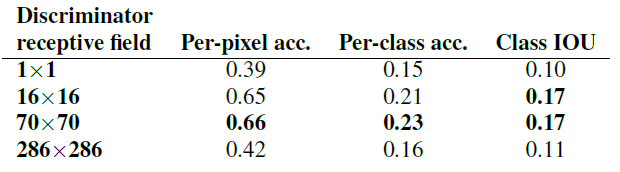
Table 2: 在Cityscapes标签上对鉴别器的不同接收场大小的FCN分数进行了评估。 请注意,输入图像的大小为
256
×
256
256\times256
256×256像素,较大的接收场用零填充。
4.2 目标函数分析

不同的损失导致不同的结果质量。 每列显示在不同损失下训练的结果。 https://phillipi.github.io/pix2pix/了解更多示例。
从上图的结果可以看出,只使用
L
1
L_1
L1 Loss会产生图片模糊的问题。只使用cGAN(
λ
=
0
\lambda=0
λ=0)的情况下,生成的图片细节确实更好,但是在一些情况下会有不自然的问题。将两种Loss结合起来(方程4中
λ
=
100
\lambda=100
λ=100)能够减轻这种现象。

我们使用FCN分数来评价街景标签
↔
\leftrightarrow
↔相片的任务(上表所示)。基于GAN的loss函数得到了更高的分数,这表明合成出来的图像包含更多可识别的结构。我们也测试了移除判别器上条件(标记为GAN)的影响。这种情况下。loss没有惩罚输入和输出中不匹配的地方,它只关心生成的图片是否真实,所以结果非常差。而且不论输入图片,生成器生成几乎一样的图片,在这项任务中这是非常不好的现象,明显cGAN表现比GAN优秀。然后
L
1
L_1
L1 loss项也鼓励输出尊重输入,因为
L
1
L_1
L1会对预测输出和真值输出之间的距离进行惩罚,所以L1加上GAN之后同样可以产生真实且尊重输入的结果,
L
1
L_1
L1+cGAN得分和
L
1
L_1
L1+GAN的情况差不多。

色度: 条件GAN一个显著的优点是甚至能够合成在标签输入中不存在空间结构,并且产生清晰的图像。我们猜想cGANs在光谱域内也有相似的效果,即使图像色彩更丰富。就像当无法确定边界的时候,
L
1
L_1
L1 loss会造成模糊的结果,当像素点无法确定颜色的时候,
L
1
L_1
L1 loss会促使生成平均、灰色调的颜色。特别的,
L
1
L_1
L1将会通过选择各种可能颜色的条件概率中位数来使loss最小。另一方面,对抗loss大体上能够判断灰色的输出是不符合真实情况的,会鼓励生成符合真实颜色分布的色彩。在上图中我们研究了cGANs在Cityscapes数据集中达到的实际效果。曲线描述了在Lab空间中输出色彩的边缘分布。真实分布用点线表示。显然
L
1
L_1
L1导致比真实情况更窄的分布,证明了
L
1
L_1
L1鼓励平均,灰度化的颜色。另一方面,使用cGAN使输出的分布更加贴合真实分布。

Fig. 4: 将跳跃连接添加到编码器-解码器以创建 “U-Net” 可以得到更高质量的结果。
Fig. 4 将 “U-Net” 与生成城市景观的 “编码器/解码器网络” 进行了比较。只需通过切断 “U-Net” 中的跳过连接skip connection即可创建 “编码器/解码器网络” 。在我们的实验中,编解码器无法学习生成逼真的图像。
4.3 生成器结构分析
U-Net结构允许低级信息直接在网络中传递。这会导致更好的结果吗?上图比较了有无U-Net结构的效果。单纯的encoder-decoder在我们的实验中无法学会生成真实的图像,对于每个输入标签,生成了几乎一样的图像(朦朦胧胧一片)。U-Net结构并没有依赖于条件GAN结构:加和不加U-Net结构的网络分别在
L
1
L_1
L1和
L
1
L_1
L1+cGAN条件下进行了训练,两种情况下U-Net结构都达到了更好的效果。


4.3 从PixelGANs到PatchGANs到ImageGANs
我们测试了判别器接收域使用不同patch size N的效果:从 1 × 1 1\times1 1×1的 “PixelGANs” 到整张图像 256 × 256 256\times256 256×256的 “ImageGANs”。上图图呈现了定性结果,上表呈现了FCN分数的定量结果。请注意本文其他地方,如果没有特别指明,均使用的是 70 × 70 70\times70 70×70的 “PatchGANs”,本节所有实验都使用 L 1 L_1 L1+cGAN的loss。
PixelGAN对于空间清晰度没有帮助,但是提升了结果的色彩效果。比如图中的巴士,在 L 1 L_1 L1 loss下是灰色的,在PixelGAN下变成了橘红色。颜色直方图匹配在图像处理中一个很常见的问题,PixelGANs或许能成为一个解决方法。
使用 16 × 16 16\times16 16×16的PatchGAN进一步提升了输出的清晰度,但是出现了一些不自然的纹理。 70 × 70 70\times70 70×70(最work) 则减轻了这种效果。如果进一步提高N,使用 256 × 256 256\times256 256×256并没有提升效果,实际上FCN得分还下降了。这也许是因为ImageGAN相比 70 × 70 70\times70 70×70的patch拥有更多的参数和更深的深度,导致难以训练。
全卷积翻译 PatchGANs的一个优点是,一个固定大小的Patch判别器可以应用于任意大小的图像。我们也可以利用生成器卷积,并应用于比它所训练的图像更大的图像上。我们在地图-航拍图上测试这个任务。在对256x256个图像上的生成器进行了训练之后,我们在512x512个图像上对其进行了测试。图8中的结果证明了这种方法的有效性。

4.5 感知验证
我们在地图转航空卫星图和灰度图转彩色图的任务中验证了我们的结果的感知现实性。我们对地图转航空卫星图的AMT实验结果如表4所示。我们的方法生成的航拍照片的真实性欺骗了18.9%的试验参与者,明显高于结果模糊、几乎无法欺骗实验参与者的L1的基线。相反,在照片转地图方向图实验中,我们的方法在欺骗了6.1%的试验参与者,这与L1基线的性能(基于引导测试)没有显著差异。这可能是因为较小的结构误差在具有刚性几何图形的地图中比在更杂乱的航空照片中更明显。


我们在ImageNet[51]上训练了着色能力,并在[62,35]引入的测试分割上进行了测试。我们的方法是在L1+cGAN损失的情况下,欺骗了22.5%的试验参与者(表5)。我们还测试了[62]的结果及其使用L2损失的方法变体(详情请参见[62])。条件GAN的得分类似于[62]的L2变种(bootstrap测试的差异不显著),但低于[62]的完整方法,这在我们的实验中欺骗了27.8%的试验参与者。我们注意到他们的方法是专门设计的,可以更好地进行着色。

4.6 语义分割
有条件GANs似乎是有效的解决问题的方法,可在常规的图像处理和图形任务中,输出的充满细节或类似于摄影作品的图像。那么对于图像视觉问题,如,输入比输出复杂的语义分割问题,那该怎么办?
在开始测试之前,我们训练了CGAN(有/没有L1丢失)!由城市风景图片转换为标签图。图10展示了定性结果,定量分类精度见表6。有趣的是,经过训练的没有L1损失的cGAN,能够在合理的精度范围解决这个问题。据我们所知,这是GAN第一次生成离散标签图而不是拥有连续值变量的图像的成功演示。虽然cGAN取得了一些成功,但它们远不是解决这个问题的最佳方法:简单地使用L1回归比使用cGAN能获得更好的分数,如表6所示。我们认为,对于视觉问题,目标(即预测接近地面的真实图像的输出)可能比图形任务更具体,像L1这样的重构损失基本上是足够的。


4.7 社区驱动研究
自从Pix2Pix的论文和代码库首次发布以来,Twitter社区,包括计算机视觉和图形从业者以及视觉艺术家,已经成功地将我们的框架应用于各种新颖的图像到图像翻译任务,远远超出了原始论文的范围。图11和图12显示了Pix2Pix标签中的几个示例,包括背景移除、调色板生成和草图转换肖像图,素描转换口袋妖怪,“照我做”的姿势转换,视觉学习:阴沉的星期天,以及新奇的话题#edges2cats和#fotogenerator。请注意,这些应用程序是创造性的项目,不是在受控的科研环境下产生的,部分依赖于我们发布的pix2pix代码做的一些改进。尽管如此,它们证明了我们的方法具有作为图像到图像翻译问题的通用商品工具的发展前景。
5. 结论
本论文的研究结果表明,条件对抗网络是一种很有前途的图像到图像的转义方法,尤其是那些涉及高度结构化图形输出的任务。这些网络基于当前的数据学习到一种自适应的损失函数,这使它们适用于各种设定。
内容总结

cGAN Loss
L
G
A
N
(
G
,
D
)
=
E
y
[
l
o
g
D
(
y
)
]
+
E
x
,
z
[
l
o
g
(
1
−
D
(
G
(
x
,
z
)
)
)
]
L_{GAN}(G, D)=E_{y}[logD(y)]+E_{x, z}[log(1-D( G(x,z)))]
LGAN(G,D)=Ey[logD(y)]+Ex,z[log(1−D(G(x,z)))]
L
L
1
(
G
)
=
E
x
,
y
,
z
[
∥
y
−
G
(
x
,
z
)
∥
1
]
L_{L_1}(G)=E_{x, y, z}[\parallel y - G(x, z)\parallel_1]
LL1(G)=Ex,y,z[∥y−G(x,z)∥1]
G
∗
=
a
r
g
min
G
max
D
L
c
G
A
N
(
G
,
D
)
+
λ
L
L
1
(
G
)
G^*=arg\min_G\max_DL_{cGAN}(G, D)+\lambda L_{L_1}(G)
G∗=argGminDmaxLcGAN(G,D)+λLL1(G)
G G G 代表生成器, D D D 代表判别器, G G G 使目标函数最小化, D D D 使目标函数最大化。
- 站在 G G G 的角度分析, G G G 作为生成器, G ( x , z ) G(x,z) G(x,z) 生成的图像尽可能逼真,那么 D D D 判别器会认为 G ( x , z ) G(x,z) G(x,z) 为真的图像,则 D ( x , G ( x , z ) ) D(x,G(x,z)) D(x,G(x,z)) 的值尽可能大,接近 1 1 1,则 1 − D ( x , G ( x , z ) ) 1-D(x,G(x,z)) 1−D(x,G(x,z)) 的值变小,目标函数变小。
- 站在 D D D 的角度分析, D D D 作为判别器, D D D 会识别出 G ( x , z ) G(x,z) G(x,z) 为假的图像,则 D ( x , G ( x , z ) ) D(x,G(x,z)) D(x,G(x,z)) 的值尽可能小,则 1 − D ( x , G ( x , z ) ) 1-D(x,G(x,z)) 1−D(x,G(x,z)) 的值变大,由于 y y y 表示真实图像,则 D ( x , y ) D(x, y) D(x,y) 值也变大,最终目标函数变大。
Generator(U-Net based)
使用skip-connection将下采样层与上采样层相连,使得下采样层提取到的特征可以直接传递到上采样层,共享更多的信息。 和U-net的大体结构类似,具体来说,我们在第 i i i层和第 n − i n−i n−i层添加了一个skip连接, n n n是所有层的数量。每一个skip连接就是 i i i层和第 n − i n−i n−i层所有通道的连接。
l
a
y
e
r
i
→
l
a
y
e
r
n
−
i
layer_i\rightarrow layer_{n−i}
layeri→layern−i
U-Net网络的结构如上图所示,蓝色箭头代表卷积和激活函数,灰色箭头代表复制剪切操作,红色箭头代表下采样,绿色箭头代表反卷积,Conv
1
×
1
1\times1
1×1代表卷积核为
1
×
1
1\times1
1×1的卷积操作。U-Net网络没有全连接层,只有卷积和下采样。U-Net可以对像素进行端到端的分割,即输入是一幅图像,输出也是一幅图像。
U-Net网络由两部分组成:
- 收缩网络来获取上下文信息,主要负责下采样的工作,提取高维特征信息,每一次下采样包含两个的 3 × 3 3\times3 3×3 的卷积操作,一个 2 × 2 2\times2 2×2 的池化操作,通过修正线性单元(rectified linear unit, ReLU)作为激活函数,每一次下采样,图片大小变为原来的 1/2,特征数量变为原来的 2 倍。
- 扩张网络用以精确定位,主要负责上采样的工作,每一次上采样包含两个
3
×
3
3\times3
3×3 的卷积操作,通过修正线性单元作为激活函数。每一次上采样,图片大小变为原来的 2 倍,特征数量变为原来的 1/2。 在上采样操作中,将每一次的输出特征与相映射的收缩网络的特征合并在一起,补全中间丢失的边界信息。最后,加入
1
×
1
1\times1
1×1 的卷积操作将之前所获的的特征映射到所属分类上面。
Discriminator(PatchGAN)
PatchGAN,将图像( 256 × 256 256\times 256 256×256)通过PatchGAN映射成个 30 × 30 30\times 30 30×30的数组,数组中的元素 X i j X_{ij} Xij(感受野为 70 × 70 70\times 70 70×70 )表示原图像裁剪成多个重叠的 70 × 70 70\times 70 70×70 patch上,对应的patch i j ij ij 是 “fake or real”,PatchGAN代码解析。
关键点就是:在 X X X上的一个神经元 X i j X_{ij} Xij可以表示一块输入patch,这个神经元就对这块patch的像素敏感,这块patch 就是输出 X i j X_{ij} Xij的感受野(receptive field)。

来源:https://www.cnblogs.com/ChenKe-cheng/p/11207998.html
将一张图片所有patch的结果取平均值作为最终的判别器输出,而不是判断整个图像的 “真与假”。这会强制实施更多约束,能更好的判别高频信息。即使 N N N远小于原图的大小,patchGAN依然可以产生较好的结果。并且,它具有更少的参数,可以降低计算量,运行更快,提升效果,并且可以运用于任意大的图像。
Pacth-D生成的是一个patch(或者说一个矩阵),在早期的GAN中,D网络一般就只输出一个数字,0 or 1,这里输出一个矩阵,矩阵中的元素为0 or 1,矩阵大小可调节(patchsize的大小)。
- 当patchsize为1*1时,则为pixelGAN
- 当patchsize为70*70时,则为PatchGAN(最work)
- 当patchsize为286*286时,则为ImageGAN
生成器 G G G和鉴别器 D D D都是使用Conv-BatchNorm-ReLu的模型。
Optimization & Inference
G G G和 D D D分开训练。
- 在 G G G的训练中,选择训练最大化 l o g D ( x , G ( x , z ) ) logD(x,G(x,z)) logD(x,G(x,z))而不是最小化 l o g ( 1 − D ( x , G ( x , z ) ) ) log(1−D(x,G(x,z))) log(1−D(x,G(x,z)))。
- 在 D D D的训练中,我们要对目标 ÷ 2 \div2 ÷2,这可以减缓 D D D相对于 G G G的学习率。
- 使用 m i n i b a t c h S G D minibatch~SGD minibatch SGD和 A d a m Adam Adam优化。
- A d a m Adam Adam:lr=0.0002,beta1=0.5, beta2=0.999
在测试中应用了 d r o p o u t dropout dropout,以及对test batch的统计值(而不是train batch的)进行了 b a t c h n o r m a l i z a t i o n batch~normalization batch normalization,也就是前面提到的 B a t c h N o r m BatchNorm BatchNorm(每一层),当batch size=1时,被称之为 “instance normalization”,这是一个利用统计特性进行归一化的过程,计算:
x − m e a n v a r + ϵ \frac{x - mean}{\sqrt{var + \epsilon}} var+ϵx−mean
- mean:均值
- var:方差
- ϵ \epsilon ϵ:防止方差为0的一个很小的正数
在实验过程中, b a t c h batch batch 的具体大小为 1 ∼ 10 1 \sim10 1∼10,取决于具体的实验要求。
Experiment
- l a b e l s ↔ p h o t o labels\leftrightarrow photo labels↔photo,图像标签生成相应的照片
- A r c h i t e c t u r e l a b l e s ↔ p h o t o Architecture\space lables\leftrightarrow photo Architecture lables↔photo,结构化的标签生成照片
- M a p ↔ a e r i a l p h o t o Map \leftrightarrow aerial\space photo Map↔aerial photo,地图生成区域照片
- B W ↔ c o l o r p h o t o BW\leftrightarrow color\space photo BW↔color photo,黑白图像上色
- E d g e s → p h o t o Edges\rightarrow photo Edges→photo,边缘图像转化为照片
- S k e t c h → p h o t o Sketch\rightarrow photo Sketch→photo,素描转化为照片
- D a y → N i g h t Day\rightarrow Night Day→Night,白天照片转为夜间
- T h e r m a l → c o l o r p h o t o Thermal\rightarrow color\space photo Thermal→color photo, 红外线图像转为彩色照片
- P h o t o w i t h m i s s i n g p i x e l s → i n p a i n t e d p h o t o Photo\space with\space missing\space pixels\rightarrow inpainted\space photo Photo with missing pixels→inpainted photo,缺损图像修复
Evaluation Metrics
- Amazon Mechanical Turk (AMT)
- FCN-Score
Analysis of Objective Function
通过一个对照实验,单独观察 L 1 L_1 L1 和 cGAN的效果,同时也是比较条件生成对抗网络和非条件生成对抗网络之间的效果。我们发现,单独使用 L 1 L_1 L1 时,出现了比较合理的结果,但是显得很模糊,而单独使用cGAN(即 λ = 0 \lambda = 0 λ=0)呈现出来的效果更加锐利,但是在视觉上引入了一些人工的成分。而当我们把这两者结合在一起使用时( λ = 100 \lambda = 100 λ=100),减少了人工成分,并且图像也不会显得模糊。
Analysis of Generator Architecture
比较了传统的Encoder-Decoder和U-Net在城市景观图生成上的效果,可以发现当两者都搭配 L 1 L_1 L1 进行训练时,U-Net表现出了更好的效果。
pix2pix的优点和缺点
pix2pix的优点
-
对于实现图像到图像的转换问题,提供了通用框架。相比于传统方法实现图像到图像间的转换,对于不同类型的图像转换,pix2pix不需要一个特定的算法,也不需要设定专门的损失函数。
-
利用U-Net框架提升了图像的细节特征,并且利用PatchGAN分类器来处理图像的高频部分,使生成图像的轮廓和条纹更清晰,色彩度更加鲜艳。
pix2pix的缺点
-
在训练模型阶段需要大量的1对1配对图像,但是这些图像收集起来很困难。
-
生成图像的真实度有待提高,如果输入的图像轮廓清晰度不高,那么生成的图像会比较模糊,图像不够真实。
参考:
https://blog.csdn.net/fr555wlj/article/details/100153303
https://blog.csdn.net/yangzishiw/article/details/82686698
https://blog.csdn.net/fuxin607/article/details/79937020
https://www.jianshu.com/p/a1058084288c
https://www.pianshen.com/article/5092511680/
https://blog.csdn.net/Lyn_B/article/details/89322085
https://blog.csdn.net/Teeyohuang/article/details/82699781
https://www.jianshu.com/p/57ff6f96ce4c
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/39
















 1417
1417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









