






该实验将重构某些代码以提高并发度。
首先切换到lock分支:
- git fetch
- git checkout lock
- make clean
一、Memory allocator
简介
user/kalloctest 这个程序会对xv6的内存分配器进行压力测试,该测试中三个进程会扩大缩小其地址空间(使用 kalloc、kfree),而这会导致 kmem.lock 的竞争。该测试会在 acquire 中打印出为了获取锁而循环等待的次数,这可以作为锁竞争的粗略指标。在未进行任何优化前,打印如下图:
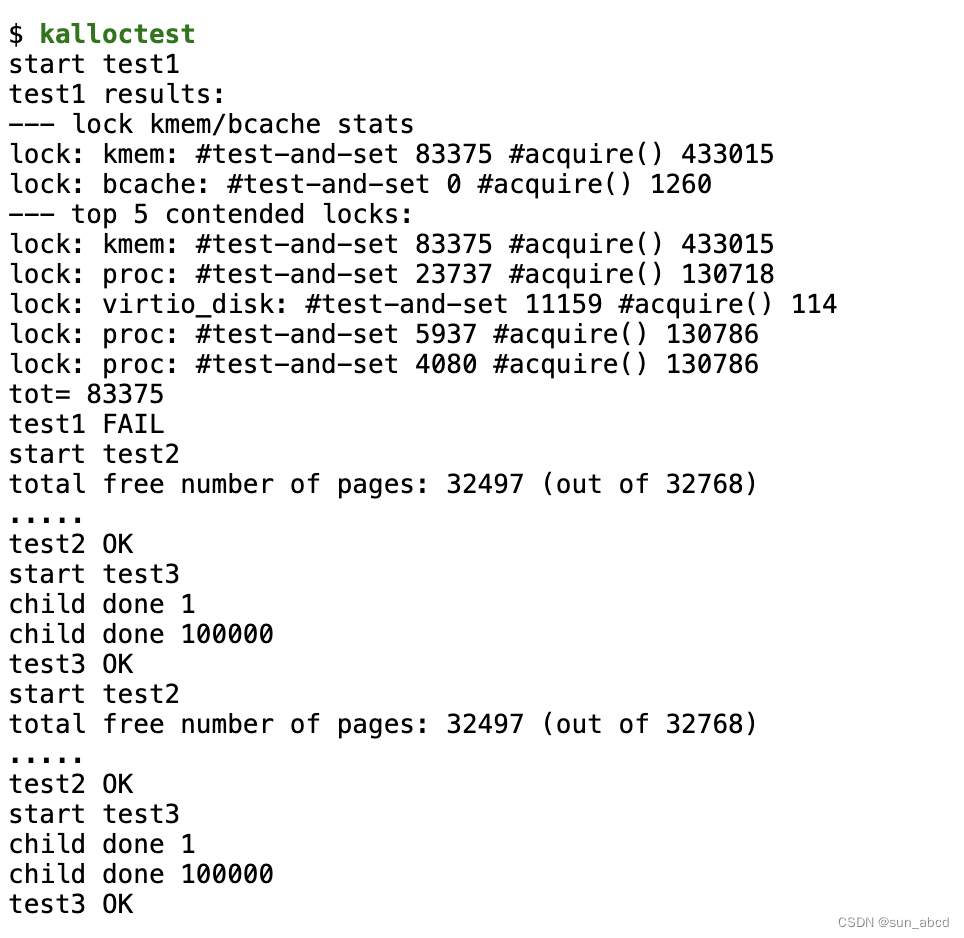
这里竞争严重的问题原因是空闲内存由一个链表来维护,多个核情况下存在并发竞争,需要锁来保护。因此,一个简单的思想是每个核都维护一个空闲链表,每个核的空闲链表拥有自己专门的锁来保证并发安全。需要注意的是,我们要处理一个核的空闲链表已经没有内存了,但另外一个核的空闲链表还存在空闲内存的情况,即需要有内存窃取机制。
提示
- 你可以使用
kernel/param.h中定义的常量NCPU - 让
freerange函数返回所有的空闲内存给运行freerange的cpu - 可以使用
cpuid来获取当前cpu的id,但是需要关闭中断,可以使用push_off()和pop_off()控制中断的开关 - 可以使用xv6的
race detector来辅助定位问题,其可以帮助检查内存是否重复分配,如果存在内存分配竞争,其将会打印如下内容:- make clean
- make KCSAN=1 qemu
- kalloctest
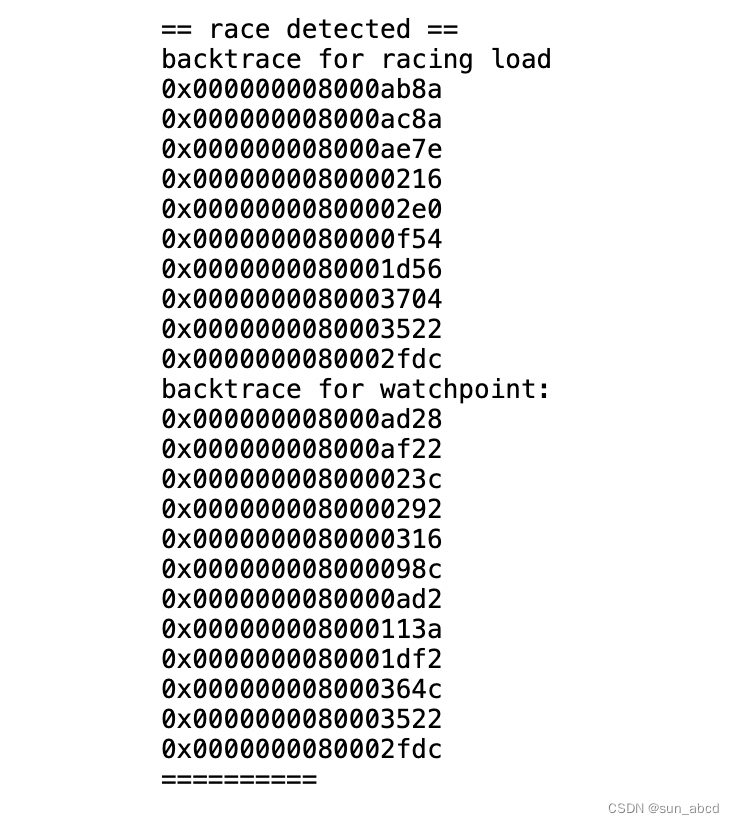
- 可以将
race detector打印的内容通过riscv64-linux-gnu-addr2line -e kernel/kernel转换成对应的函数名
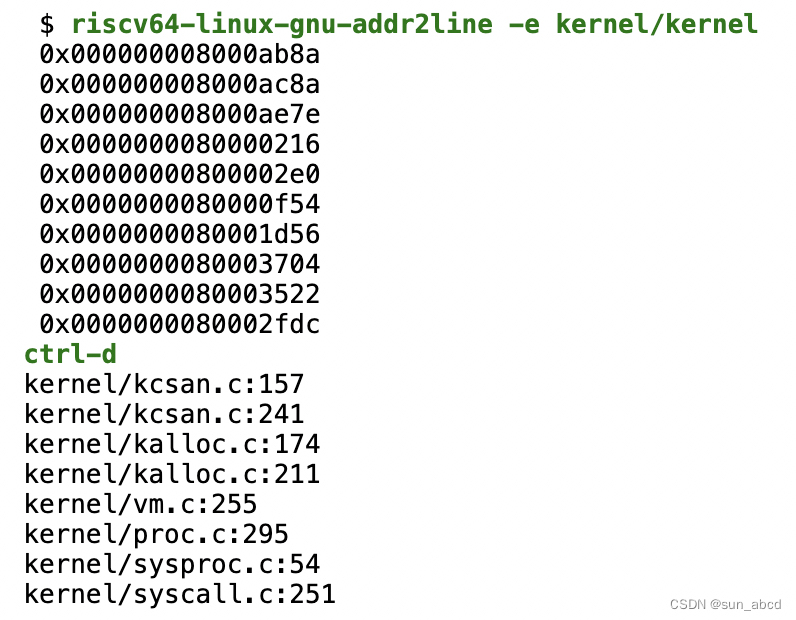
实验代码
本实验主要修改内存申请释放模块,即主要修改kalloc.c文件。
- 将空闲链表分为每个cpu一个,且每个cpu一个锁
- 修改
kinit()初始化每个cpu的空闲链表 - 修改
kalloc()分配内存时通过cpuid()获取当前cpu id,从自己的空闲链表中获取内存;kfree()同理 kalloc()中需要添加内存盗取逻辑
修改空闲链表每个cpu一个
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
更改初始化逻辑
void
kinit()
{
char name[16];
for(int i = 0; i < NCPU; i++){
snprintf(name, sizeof(name), "kmem_cpu%d", i);
initlock(&kmem[i].lock, name);
}
freerange(end, (void*)PHYSTOP);
}
更改分配逻辑
void *
kalloc(void)
{
struct run *r;
int cpu = -1;
push_off(); //关中断
cpu = cpuid();
pop_off(); // 开中断
acquire(&kmem[cpu].lock);
r = kmem[cpu].freelist;
if(r){
kmem[cpu].freelist = r->next;
} else {
// 内存窃取
struct run* tmp;
for (int i = 0; i < NCPU; ++i) {
if (i == cpu) continue;
acquire(&kmem[i].lock);
tmp = kmem[i].freelist;
if (tmp == 0) {
release(&kmem[i].lock);
continue;
} else {
// 窃取一个页面
kmem[cpu].freelist = kmem[i].freelist;
kmem[i].freelist = tmp->next;
tmp->next = 0;
release(&kmem[i].lock);
break;
}
}
r = kmem[cpu].freelist;
if (r)
kmem[cpu].freelist = r->next;
}
release(&kmem[cpu].lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
更改回收逻辑
void
kfree(void *pa)
{
struct run *r;
int cpu = -1;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off();
cpu = cpuid();
pop_off();
acquire(&kmem[cpu].lock);
r->next = kmem[cpu].freelist;
kmem[cpu].freelist = r;
release(&kmem[cpu].lock);
}
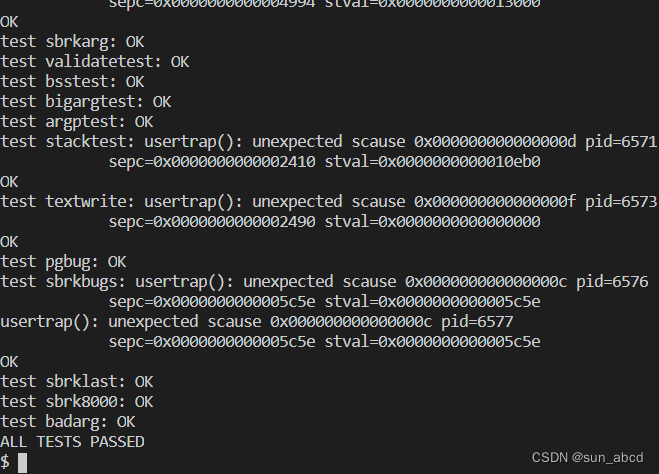
实验结果
-
kalloctest
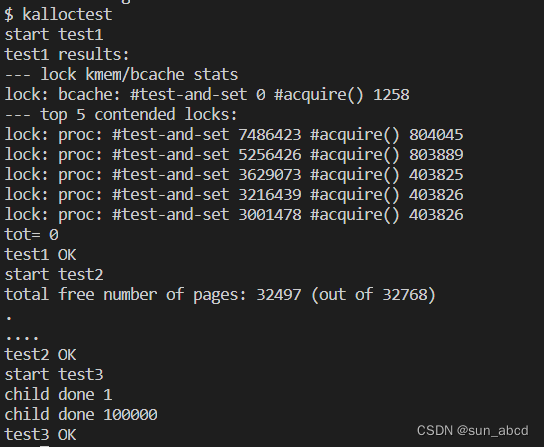
-
usertests sbrkmuch
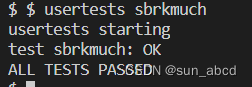
-
usertests -q
二、Buffer cache
简介
当多个进程密集的访问文件系统时,它们可能会争夺 bcache.lock ,该锁保护 kernel/bio.c 中磁盘块缓存。bcachetest 将创建多个重复读取不同文件的进程,以使得产生 bcache.lock 的争用,其输出可能如下(在未完成实验之前):

bcache.lock 保护了很多临界区,包括:the list of cached block buffers, the reference count (b->refcnt) in each block buffer, and the identities of the cached blocks (b->dev and b->blockno).
我们需要修改锁的粒度,实现所有锁在acquire()中的打印接近于0,即每个锁的获取几乎不需要等待。修改 bget() 和 brelse() 函数,使得 bcache 中不同块的并发查找和释放不太可能发生冲突。
必须保证每个块在bcache中最多一份缓存。
完成该实验后,运行下列命令打印如下:
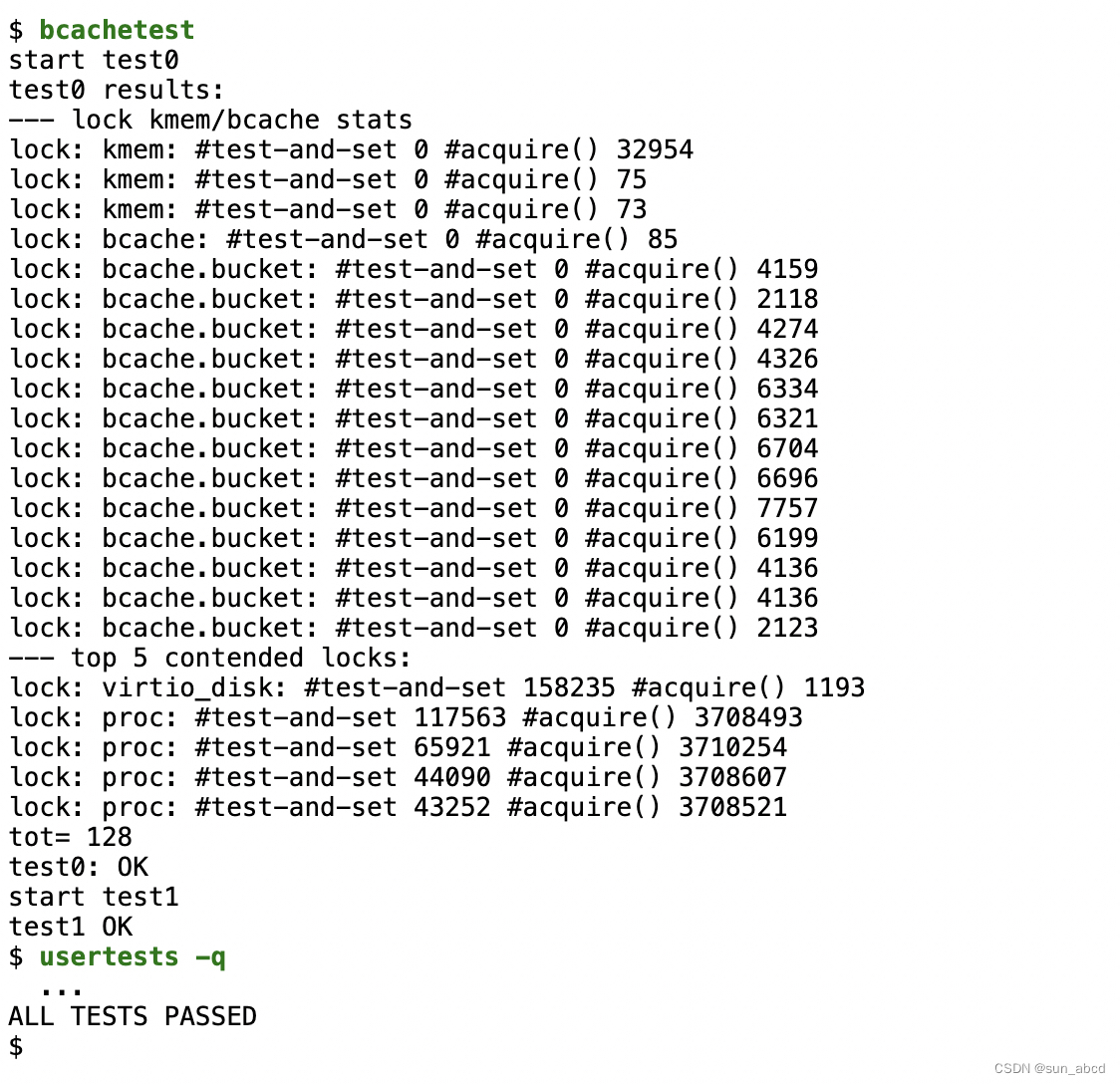
提示
- 所有锁的名称必须用
bcache开头,并使用initlock()初始化这些锁 - 可以采用给每个hash桶一个锁的方式来实现
- 可以扩大hash桶来减少桶内元素的竞争
- 阅读 xv6-book 的 section 8.1-8.3,了解xv6的块缓存
- hash桶的大小可以采用质数(例如13)来减少冲突,hash表的大小可以是固定,不用动态扩容
- hash表中寻找
buffer缓存和当搜寻不到,为该块分配缓存时的操作必须是原子的 - 删除所有bcache中的buffer list(
bcache.head),并且不使用LRU算法,这样relse()可以不用获取bcache 锁,bget()中可以选择任意一个refcnt == 0的块。
实验代码
- 主要修改
bio.c,该实验由于时间原因,取网上答案且未验证
重新定义bcache,包含13个hash桶,每个桶一个锁,hash算法使用最简单的blockno % NBUCKET
#define NBUCKET 13
struct {
struct spinlock lock;
struct buf head[NBUCKET];
struct buf hash[NBUCKET][NBUF];
struct spinlock hashlock[NBUCKET]; // lock per bucket
} bcache;
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
for (int i = 0; i < NBUCKET; i++) {
initlock(&bcache.hashlock[i], "bcache");
// Create linked list of buffers
bcache.head[i].prev = &bcache.head[i];
bcache.head[i].next = &bcache.head[i];
for(b = bcache.hash[i]; b < bcache.hash[i]+NBUF; b++){
b->next = bcache.head[i].next;
b->prev = &bcache.head[i];
initsleeplock(&b->lock, "buffer");
bcache.head[i].next->prev = b;
bcache.head[i].next = b;
}
}
}
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
uint hashcode = blockno % NBUCKET;
acquire(&bcache.hashlock[hashcode]);
// Is the block already cached?
for(b = bcache.head[hashcode].next; b != &bcache.head[hashcode]; b = b->next){
if(b->dev == dev && b->blockno == blockno){
b->refcnt++;
release(&bcache.hashlock[hashcode]);
acquiresleep(&b->lock);
return b;
}
}
// Not cached.
// Recycle the least recently used (LRU) unused buffer.
for(b = bcache.head[hashcode].prev; b != &bcache.head[hashcode]; b = b->prev){
if(b->refcnt == 0) {
b->dev = dev;
b->blockno = blockno;
b->valid = 0;
b->refcnt = 1;
release(&bcache.hashlock[hashcode]);
acquiresleep(&b->lock);
return b;
}
}
panic("bget: no buffers");
}
void
brelse(struct buf *b)
{
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
uint hashcode = b->blockno % NBUCKET;
acquire(&bcache.hashlock[hashcode]);
b->refcnt--;
if (b->refcnt == 0) {
// no one is waiting for it.
b->next->prev = b->prev;
b->prev->next = b->next;
b->next = bcache.head[hashcode].next;
b->prev = &bcache.head[hashcode];
bcache.head[hashcode].next->prev = b;
bcache.head[hashcode].next = b;
}
release(&bcache.hashlock[hashcode]);
}














 490
490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









