







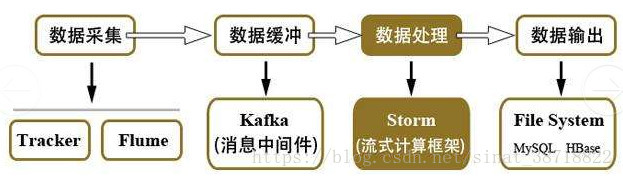
Storm (一)
storm的应用
-
01 Apache Storm是什么
实时计算和离线计算的区别:
离线计算,一次计算很多条数据, 批次处理
实时计算,数据被一条一条的计算, 实时收集、实时计算、实时展示
Storm是一个流式计算框架
Storm用来实时处理数据,特点:低延迟、高可用、分布式、可扩展、数据不丢失。
-
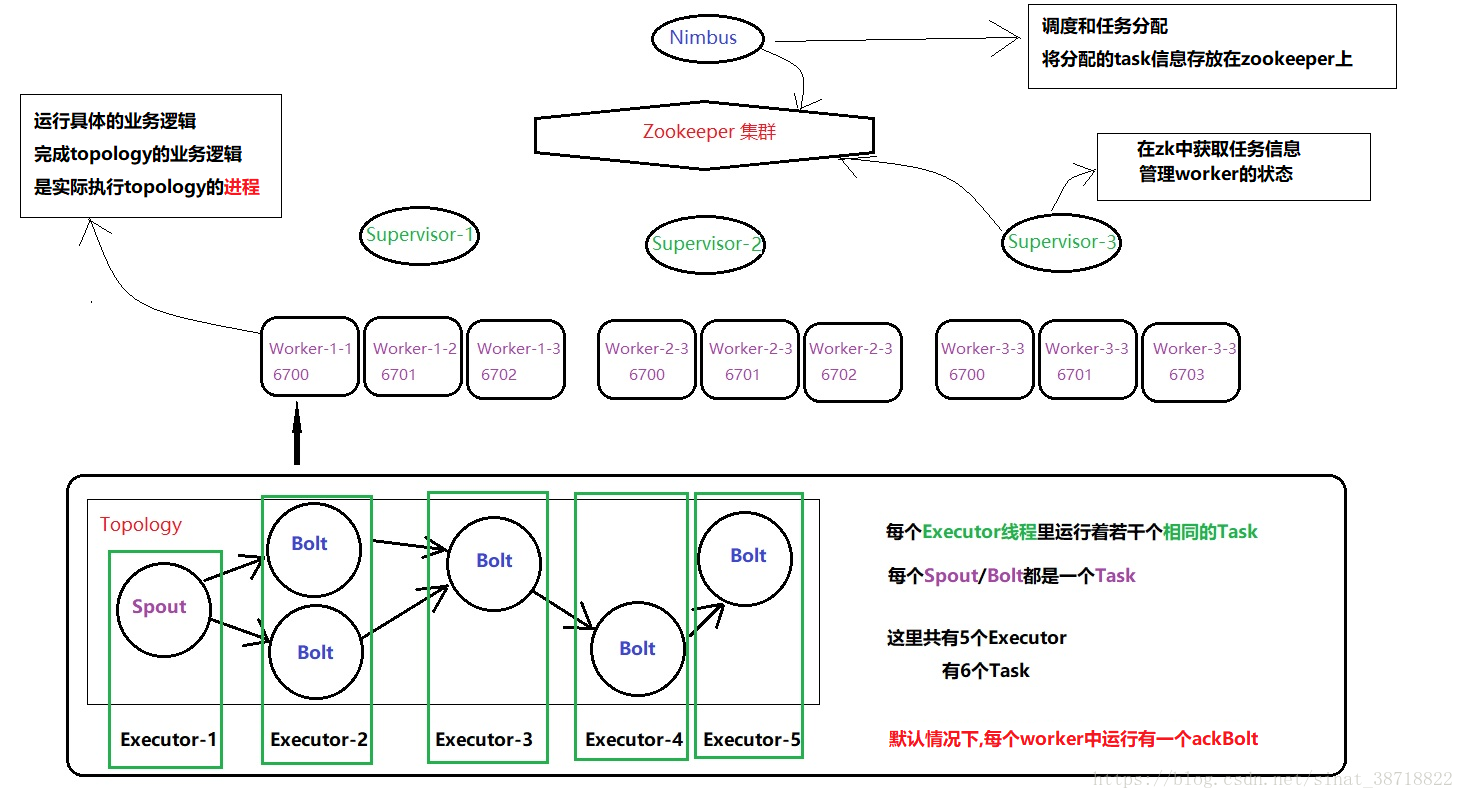
02 Apache Storm 架构&编程模型&基本概念

-
03 Apache Storm WordCount程序编写-创建工程及介绍Spout的三个方法
创建maven工程,导入依赖
<dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.1.1</version> </dependency>创建数据流入源(spout)
/** * 读取外部的文件,将一行一行的数据发送给下游的bolt * 类似于hadoop MapReduce中的inputformat */ public class ReadFileSpout extends BaseRichSpout { private SpoutOutputCollector collector; private BufferedReader bufferedReader; /** * 初始化方法,类似于这个类的构造器,只被运行一次 * 一般用来打开数据连接,打开网络连接。 * * @param conf 传入的是storm集群的配置文件和用户自定义配置文件,一般不用。 * @param context 上下文对象,一般不用 * @param collector 数据输出的收集器,spout类将数据发送给collector,由collector发送给storm框架。 */ public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) { try { bufferedReader = new BufferedReader(new FileReader(new File("//root//zhangsan//wordcount.txt"))); } catch (FileNotFoundException e) { e.printStackTrace(); } this.collector = collector; } /** * 下一个tuple,tuple是数据传送的基本单位。 * 后台有个while循环一直调用该方法,每调用一次,就发送一个tuple出去 */ public void nextTuple() { String line = null; try { line = bufferedReader.readLine(); if (line!=null){ collector.emit(Arrays.asList(line)); } } catch (IOException e) { e.printStackTrace(); } } /** * 声明发出的数据是什么 * * @param declarer */ public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("juzi")); } } -
05 Apache Storm WordCount程序编写-splitBolt进行单词切割
/** * 输入:一行数据 * 计算:对一行数据进行切割 * 输出:单词及单词出现的次数 */ public class SplitBolt extends BaseRichBolt{ private OutputCollector collector; /** * 初始化方法,只被运行一次。 * @param stormConf 配置文件 * @param context 上下文对象,一般不用 * @param collector 数据收集器 */ @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } /** * 执行业务逻辑的方法 * @param input 获取上游的数据 */ @Override public void execute(Tuple input) { // 获取上游的句子 String juzi = input.getStringByField("juzi"); // 对句子进行切割 String[] words = juzi.split(" "); // 发送数据 for (String word : words) { // 需要发送单词及单词出现的次数,共两个字段 collector.emit(Arrays.asList(word,"1")); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word","num")); } } -
06 Apache Storm WordCount程序编写-单词计数
/** * 输入:单词及单词出现的次数 * 输出:打印在控制台 * 负责统计每个单词出现的次数 * 类似于hadoop MapReduce中的reduce函数 */ public class WordCountBolt extends BaseRichBolt { private Map<String, Integer> wordCountMap = new HashMap<String, Integer>(); /** * 初始化方法 * * @param stormConf 集群及用户自定义的配置文件 * @param context 上下文对象 * @param collector 数据收集器 */ @Override public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { // 由于wordcount是最后一个bolt,所有不需要自定义OutputCollector collector,并赋值。 } @Override public void execute(Tuple input) { //获取单词出现的信息(单词、次数) String word = input.getStringByField("word"); String num = input.getStringByField("num"); // 定义map记录单词出现的次数 // 开始计数 if (wordCountMap.containsKey(word)) { Integer integer = wordCountMap.get(word); wordCountMap.put(word, integer + Integer.parseInt(num)); } else { wordCountMap.put(word, Integer.parseInt(num)); } // 打印整个map System.out.println(wordCountMap); } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { // 不发送数据,所以不用实现。 } } -
07 Apache Storm WordCount程序编写-本地运行及maven插件设置
WordCountTopology类(main方法)
/** * wordcount的驱动类,用来提交任务的。 */ public class WordCountTopology { public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException { // 通过TopologyBuilder来封装任务信息 TopologyBuilder topologyBuilder = new TopologyBuilder(); // 设置spout,获取数据 topologyBuilder.setSpout("readfilespout",new ReadFileSpout(),2); // 设置splitbolt,对句子进行切割 topologyBuilder.setBolt("splitbolt",new SplitBolt(),4).shuffleGrouping("readfilespout"); // 设置wordcountbolt,对单词进行统计 topologyBuilder.setBolt("wordcountBolt",new WordCountBolt(),2).shuffleGrouping("splitbolt"); // 准备一个配置文件 Config config = new Config(); // storm中任务提交有两种方式,一种方式是本地模式,另一种是集群模式。 // LocalCluster localCluster = new LocalCluster(); // localCluster.submitTopology("wordcount",config,topologyBuilder.createTopology()); //在storm集群中,worker是用来分配的资源。如果一个程序没有指定worker数,那么就会使用默认值。 config.setNumWorkers(2); //提交到集群 StormSubmitter.submitTopology("wordcount1",config,topologyBuilder.createTopology()); } }指定jdk版本插件
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> -
08 Apache Storm WordCount程序编写-程序运行的整体流程梳理

Storm集群搭建
-
09 Apache Storm 集群管理-集群部署
-
storm是依赖于zookeeper的,搭建storm集群前,必须先把zookeeper集群搭建好
-
上传解压storm安装包到指定目录
tar -zxvf apache-storm-1.1.1.tar.gz -C ../services/-
修改配置文件 storm.yaml
storm.zookeeper.servers: - "node01" - "node02" - "node03" # nimbus.seeds: ["node01", "node02", "node03"] storm.local.dir: "/export/data/stormdata" ui.port: 8088 supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 -
将安装程序分发到其他机器
scp -r apache-storm-1.1.1/ node02:/export/services/ scp -r apache-storm-1.1.1/ node03:/export/services/ -
启动storm相关服务
启动 nimbus进程(主节点) nohup bin/storm nimbus >/dev/null 2>&1 & 启动supervisor(从节点) nohup bin/storm supervisor >/dev/null 2>&1 & 启动web UI nohup bin/storm ui >/dev/null 2>&1 & 启动logViewer nohup bin/storm logviewer >/dev/null 2>&1 &storm没有提供一键启动,需要自己手动编写一键启动脚本
-
访问stormUI界面
访问地址
http://xxxx:8088/
-
-
10 Apache Storm 集群管理-编译代码并提交任务
提交任务到集群
bin/storm jar /export/services/storm.jar com.test.storm.MainTopology clusterStorm -
11 Apache Storm 集群管理-任务资源申请的基本单位Worker&Task

- 12 Apache Storm 集群管理-任务提交过程及执行流程


- 13 Apache Storm 集群管理-任务的worker&Task设置

-
14 Apache Storm 集群管理-replication count及nimbus seeds节点说明
nimbus seeds和我们启动的nimbus主节点的个数有关,每个任务都会在集群所有的nimbus主节点上备份一份
案例实战
-
15 Apache Storm 案例实战-实时看板整体结构及模拟生产支付信息
模拟生产了订单数据

-
16 Apache Storm 案例实战-实时看板代码开发之集成KafkaSpout插件
创建maven工程,导入依赖
<dependencies> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>1.1.1</version> <!-- 如果集群上提供了storm-core.jar。需要在编译的时候排除掉 --> <!--<scope>provided</scope>--> </dependency> <!--storm和kafka集成--> <!-- use new kafka spout code --> <dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-kafka-client</artifactId> <version>1.1.1</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.10.0.0</version> </dependency> <dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.8.1</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> </dependencies>/** * 驱动类 * 提交一个订单实时金额统计的任务 */ public class KanBanTopology { public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException { TopologyBuilder topologyBuilder = new TopologyBuilder(); // 1.设置一个kafkaspout消费kafka集群中的数据 KafkaSpoutConfig.Builder<String, String> builder = KafkaSpoutConfig.builder("node01:9092", "payment"); builder.setGroupId("payment_storm_index"); KafkaSpoutConfig<String, String> kafkaSpoutConfig = builder.build(); topologyBuilder.setSpout("KafkaSpout", new KafkaSpout<String, String>(kafkaSpoutConfig), 3); // 2.设置解析json串的bolt topologyBuilder.setBolt("ParserPaymentBolt",new ParserPaymentBolt(),3).shuffleGrouping("KafkaSpout"); // 3. 设置计算指标的bolt topologyBuilder.setBolt("PaymentIndexProcessBolt",new PaymentIndexProcessBolt(),3).shuffleGrouping("ParserPaymentBolt"); // 4.得到一个真正的stormtopology对象,用来提交到集群 StormTopology topology = topologyBuilder.createTopology(); // 5.使用本地模式运行任务 Config config = new Config(); config.setNumWorkers(1); LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("kanban",config,topology); // StormSubmitter.submitTopology("kanban",config,topology); } }

-
17 Apache Storm 案例实战-实时看板代码开发之使用Gson解析订单信息
/** * 获取kafkaspout发送过来的数据,并解析成为一个javabean * 输入的json * 输出:java对象 */ public class ParserPaymentBolt extends BaseRichBolt { private OutputCollector collector; public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { this.collector = collector; } public void execute(Tuple input) { long start = System.currentTimeMillis(); //1.获取从kafka集群中消费数据 // 从input中获取值,有两种方式。getStringByField 和通过角标获取值 String json = input.getStringByField("value"); // Object value1 = input.getValue(4); // String value2 = input.getString(4); System.out.println("-------------"); Gson gson = new Gson(); Payment payment = gson.fromJson(json, Payment.class); // 在发送数据的时候,Arrays.asList得到一个list对象 // 其实storm框架也封装一个类,让开发者快速的得到一个list。就是Values类 collector.emit(new Values(payment)); System.out.println(System.currentTimeMillis()-start); } public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("javaBean")); } }

-
18 Apache Storm 案例实战-实时看板代码开发之订单人数、订单金额、订单数计算
/** * 计算相关的指标 * 计算那些指标? * 计算订单金额(payPrice字段的金额进行累加)、订单数(一条消息就是一个订单)、订单人数(一个消息就是一个人) * -------------指标口径的统一,在每个企业中都不一样。作为开发者,一定要找产品经理或者提需求的人讨论明白。 * 指标数据存放到哪里? * --------------存放到redis */ public class PaymentIndexProcessBolt extends BaseRichBolt { private Jedis jedis = null; public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) { // jedis = new Jedis("redis",6379); jedis = new Jedis("192.168.40.167",6379); } public void execute(Tuple input) { // 获取上游发送的值 Payment value = (Payment) input.getValue(0); // 计算订单金额(payPrice字段的金额进行累加)、订单数(一条消息就是一个订单)、订单人数(一个消息就是一个人) jedis.incrBy("price", value.getPayPrice()); jedis.incrBy("orderNum",1); jedis.incrBy("orderUser",1); // 计算每个品类的订单数,订单人数,订单金额 // 返回的是三品的一级品类,二级品类,三级品类 String categorys = value.getCatagorys(); String[] split = categorys.split(","); //102,144,114 for(int i=0;i<split.length;i++){ //price:1:102 //price:2:144 //price:3:144 jedis.incrBy("price:"+(i+1)+":"+split[i], value.getPayPrice()); jedis.incrBy("orderNum:"+(i+1)+":"+split[i],1); jedis.incrBy("orderUser:"+(i+1)+":"+split[i],1); } // 计算商品属于哪个产品线 // jedis.incrBy("price:cpxid:"+split[i], value.getPayPrice()); //计算每个店铺的订单人数,订单金额,订单数 jedis.incrBy("price:shop:"+value.getShopId(), value.getPayPrice()); jedis.incrBy("orderNum:shop:"+value.getShopId(),1); jedis.incrBy("orderUser:shop:"+value.getShopId(),1); //计算每个商品的订单人数,订单金额,订单数 jedis.incrBy("price:pid:"+value.getProductId(), value.getPayPrice()); jedis.incrBy("orderNum:pid:"+value.getProductId(),1); jedis.incrBy("orderUser:pid:"+value.getProductId(),1); } public void declareOutputFields(OutputFieldsDeclarer declarer) { } }

-
19 Apache Storm 案例实战-实时看板代码开发之 程序的worker&Task数量设置
根据所处理对的数据大小,以及kafka的消费者负载均衡策略,设置程序的worker和task数
-
20 Apache Storm 案例实战-实时看板代码打包运行(maven的provide作用域说明)
打包插件
<build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <!--设置驱动--> <mainClass>cn.itcast.realtime.storm.kanban.KanBanTopology</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.7.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build>标签值得使用,说明:
<scope>provided</scope> 目前<scope>可以使用5个值: * compile,缺省值,适用于所有阶段,会随着项目一起发布。 * provided,表示打包时不需要该jar包,本地运行时需要。 * runtime,只在运行时使用,如JDBC驱动,适用运行和测试阶段。 * test,只在测试时使用,用于编译和运行测试代码。不会随项目发布。 * system,类似provided,需要显式提供包含依赖的jar,Maven不会在Repository中查找它。 -
21 Apache Storm 案例实战-实时看板业务问题扩展
实现商品的一级,二级,三级分类
每个品类,每个产品线,每个店铺,每个商品分别的实时成交情况
Storm 一键启动脚本扩展
-
storm集群一键启动脚本
source /etc/profile nohup storm nimbus >/dev/null 2>&1 & nohup storm ui >/dev/null 2>&1 & cat /export/servers/storm/bin/slave | while read line do { echo $line ssh $line "source /etc/profile;nohup storm supervisor >/dev/null 2>&1 &" }& wait done -
storm集群一键停止脚本
source /etc/profile jps | awk '{ if( $2 == "nimbus" || $2 == "supervisor" || $2 == "core" ) print $1 }' |xargs kill -s 9 cat /export/script/slaves | while read line do { echo $line ssh $line "source /etc/profile;jps |grep Supervisor |cut -c 1-4 |xargs kill -s 9" }& wait done -
slave文件
node02 node03
Storm的动态修改并行参数
-
运行命令
storm rebalance mytopology -n 3 -e mySpout=5 -e splitBolt=6 -e countBolt=8 -
参数介绍
mytopology 我们在storm集群提交任务时,所取的任务名
-n 表示要设置的worker数 后面跟上要具体设置的数值
-e 表示要设置的executor数后面跟上Spout/Bolt的类名 id=具体数值
一定要注意:重新调整的时候=号两边不要有空格
















 725
725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









