







一、问题
原始数据中ID对应多个文本数据,现在需要将ID下面的文本进行合并。
在工作中曾经遇到过这样的场景,有一批客户,客户用客户ID表示,每个客户下面有很多条评论,需要将客户的评论进行合并,然后对客户的评论进行文本挖掘。思路和下面的思路一样。

二、问题解决代码
import pandas as pd
import numpy as np
data = pd.DataFrame({'id':[1,1,1,2,2,2],'value':['A','B','C','D','E','F']})
data_deal = data.groupby('id').apply(lambda x:[','.join(x['value'])]).apply(lambda x:x[0]).reset_index(name='value')
print(data_deal)
'''
id value
0 1 A,B,C
1 2 D,E,F
'''三、用到的知识点
3.1 groupby
3.1.1 主要作用:
和excel中分类汇总或者透视表实现的功能是一样的,比如有一组关于客户的数据,里面有客户的性别、年龄段等数据,现在想要知道每个年龄段每个性别有多少人。
3.1.2 常用方法
3.1.2.1 单类分组
是指只有一个统计变量,如下面的统计字段['shot_zone_basic'] (数据是来自kaggle比赛数据)

以上的操作只能创建一个groupby对象,一般在应用中会加上要统计的方式,如下客户直接展示数据的多种统计指标,当然如果只需要统计一种统计指标可以直接将descrbe()替换成mean()、count()等。
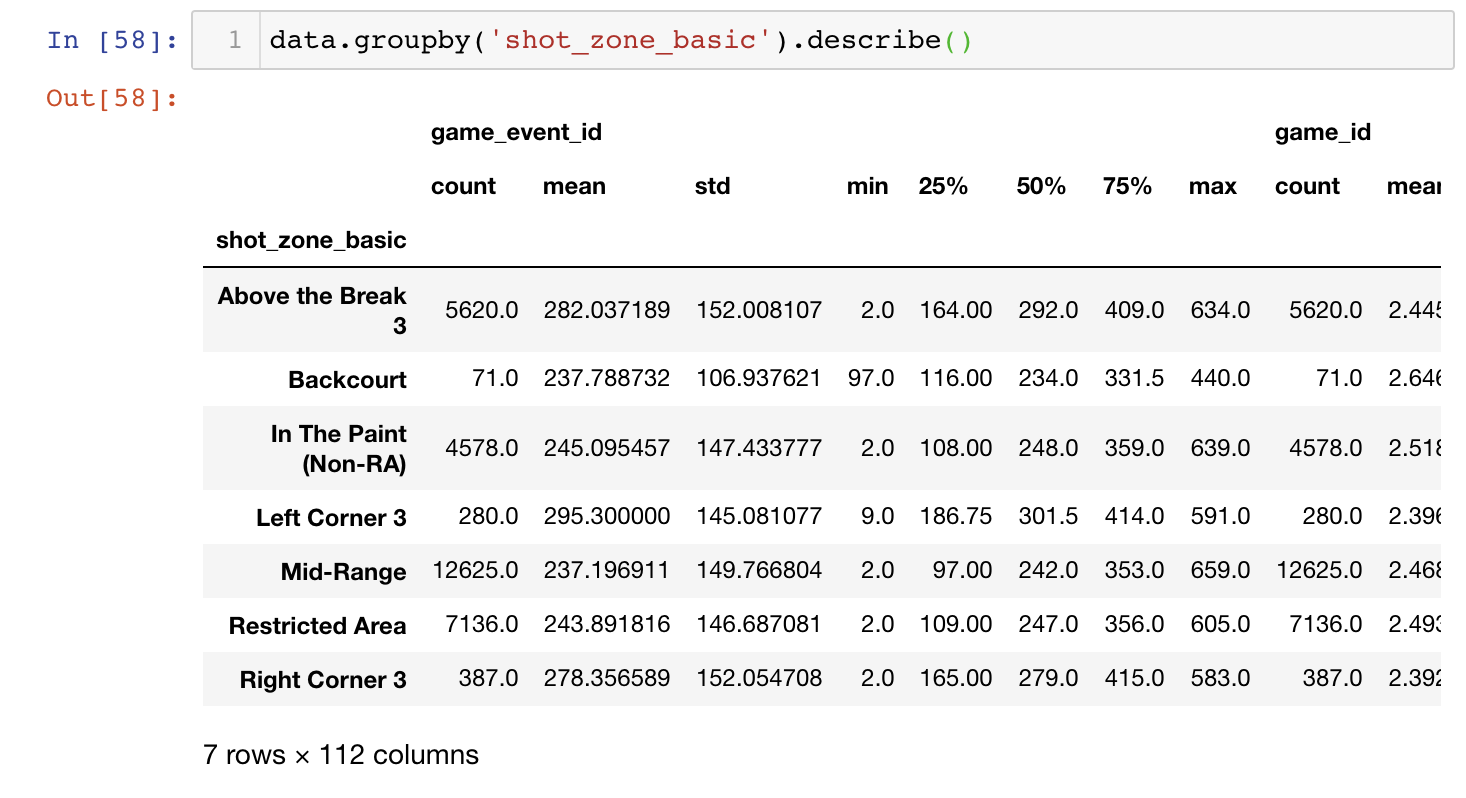
很多时候统计的指标和数据变量较多时,数据使用横排展示在视觉上很难看清,这时可以使用unstack()函数优化展示。

3.1.2.2 多类分组
多类统计是统计时有一个以上的变量,在实际工作中应用就是多个变量多个统计指标的统计方式,如下:


3.2 匿名函数
指没有函数的名字,又不想命名的函数
3.2.1 匿名函数 lamda表达式
result = lambda[arg1[,arg2,...,argn]]:expression
#result:用于调用lambda表达式
#[arg1[,arg2,…,argn]]:可选参数,用于指定要传递的参数列表,多个参数使用逗号“,”分隔
#expression:必选参数,用于指定一个实现具体功能的表达式,如果有参数,那么在该表达式中将应用这些参数。3.2.2 应用小案例
a, b = 10, 20
sum = lambda x, y: x + y
print(sum)
print(sum(a, b))















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











