






目录
0. 基本概念
表1. 判别式建模 vs. 生成式建模

GenAI分类:
- task-specific:VAE, GAN, flow, diffusion,
- general: GPT,

生成式人工智能模型的类型[5]
1. 深度生成模型
概览
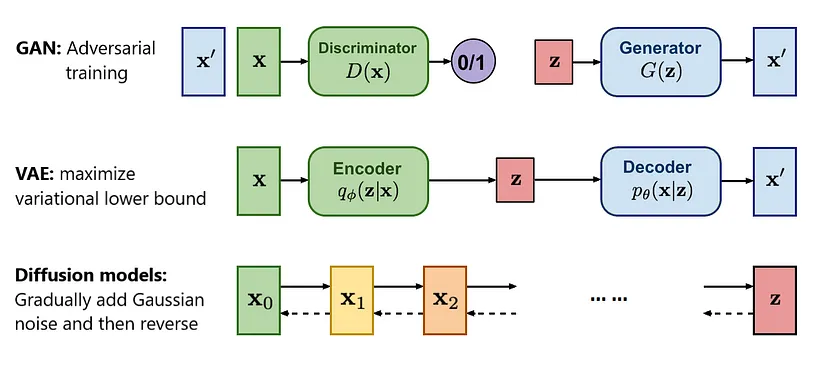
图1. 不同类型生成模型概述[1]
(上)GAN由生成器和判别器组成,生成器接收从正态分布中采样的随机值并生成样本,鉴别器则尝试区分真实样本和生成样本。
(中)VAE由编码器和解码器组成,编码器将高维输入数据映射为低维表示,解码器则尝试将这种表示映射回原始域。
(下)扩散模型有一个固定的正向扩散和一个可训练的反向扩散过程组成,正向扩散是一个马尔可夫链,逐渐向输入数据中添加噪声,直到得到白噪声。反向扩散过程的目的是一步一步地逆转正向过程,去除噪声,从而恢复原始数据。
表1. 三种生成模型的特点
| 模型 | 优点 | 局限 |
|---|---|---|
| VAE | 多样性高;采样快; | 保真度可能较低(潜在编码重叠;潜空间小无法保留像素级信息); |
| GAN | 较高保真(神经网络收敛后,判别器无法区分真实样本和生成样本);采样快; | 多样性低(模式崩溃);难以训练(需要关注两个损失); |
| diffusion | 高保真(逐步生成,中间图像/潜空间于训练图像一样大);多样性高; | 速度慢(多步); |
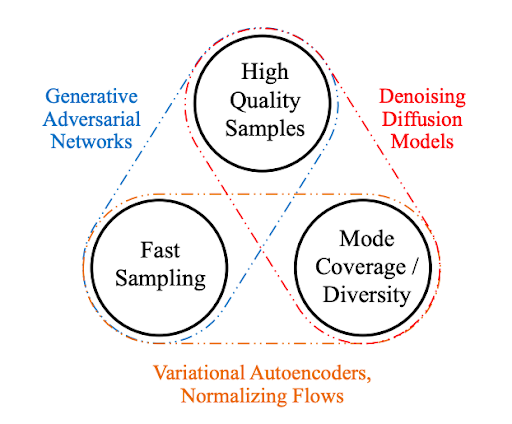
图2. 生成学习三元悖论[2]
高质量采样: 许多应用都需要较高的生成质量。
模式覆盖/采样多样性: 如果训练数据包含复杂或大量多样性,模型应能成功捕捉,而不影响生成质量。
快速且计算成本低廉的采样: 许多交互式应用需要快速生成。
现有方法通常需要权衡利弊,无法同时满足所有要求。
变分自编码器(VAE)
VAE结合了自编码器和概率建模的能力,以获得数据的压缩表示。VAE将输入数据编码到一个低维的潜空间中,通过从获取的分布中采样点来生成新样本。
VAE 的实际应用涵盖图像生成、数据压缩、异常检测和药物发现等多个领域。
生成对抗网络(GAN)
GAN由两个相互博弈的生成器和判别器组成。生成器的主要功能是生成与真实数据非常相似的合成数据,而判别器则负责区分真实数据和伪造数据。生成器通过对抗训练提高生成数据的真实性,而判别器则有效地确定数据是真实的还是合成的。
GAN可用于生成样本以增强数据和预处理。广泛应用于图像处理和生物医学等多个领域。
流模型(flow)
基于流的模型旨在学习给定数据集的底层结构,模型通过理解数据集中不同事件的概率分布来实现这一目标,然后就能生成与初始数据集具有相同统计属性和特征的新数据点。
模型的一个主要特点是,它们对输入数据进行简单的可逆变换,而这种变换很容易逆转。通过从简单的初始分布(如随机噪音)开始并反向应用变换,模型可以快速生成新样本,而无需进行复杂的优化。这使得基于流的模型比其他模型计算效率更高、速度更快。
扩散模型(diffusion)
扩散模型背后的基本思想是将简单易得的分布转化为更复杂、更有意义的数据分布。这种转换是通过一系列可逆操作完成的。一旦模型理解了转换过程,它就能从简单分布中的一个点开始生成新样本,并逐渐向所需的复杂数据分布扩散。
生成式扩散模型可以利用训练数据创建新数据。
2. 生成式(大语言|多模态)模型
GPT (OpenAI)
通过无监督预训练和针对下游任务的微调,GPT显示其生成特定任务自然语言的潜力。它利用transformer-decoder层进行下一单词预测和连贯文本生成。
LLaMA (Meta)
LLaMA 已在各种数据源上进行了训练,包括社交媒体帖子、网页、书籍、新闻文章等。其目的是支持各种元应用,如内容管理、搜索、推荐和个性化。
PaLM 2 (Google)
一个拥有400B参数的多模态大模型,可以处理和生成文本和图像。它经过了大规模数据集的训练,涵盖 100 种语言和 40 个视觉领域,因此能够执行图像字幕、视觉问题解答、文生图等跨模态任务。
基于GAN
- StyleGAN 3(NVIDIA):一个GAN模型,专注于生成高质量的图像,特别是人脸。
基于扩散
- Stable Diffusion(Stability AI)
- DALL·E 2(OpenAI)
3. 生成式模型开发
流程
- 定义目标:明确定义目标。
- 数据收集:收集与目标一致的各种数据集。
- 预处理:消除噪音和错误。
- 选择模型架构:每种架构都有独特优势和局限,评估目标和数据集,结合架构特点进行选择。
- 实现模型:
TensorFlow和PyTorch等框架和库提供了预构建组件和资源,可简化实现过程。 - 训练模型:需要大量时间和资源,具体取决于模型的复杂程度和数据集的大小。监控模型的进展并调整其超参(如学习率,批大小)对取得最佳结果至关重要。
- 评估和优化:使用适当的指标来衡量预测结果。如结果不符合预期,则进一步调整模型架构、训练参数或数据集,以优化其性能。
- 微调和迭代:对初步结果评估后,就可以确定需要改进的地方。持续改进是开发高质量生成模型的关键。
策略
- 选择典型的模型架构:根据目标,综合考虑多种因素,如数据复杂性,质量;性能;可扩展性;效率等。
- 使用迁移学习和预训练模型:可以大大减少训练所需的时间和资源。
- 使用数据增强和正则化技术:可以改善生成质量和模型泛化能力。
- 数据扩增:通过对现有数据进行裁剪、翻转、旋转或引入噪声等变换来创建多样化的数据。可用于图像生成的随机裁剪或颜色抖动。
- 正则化:通过dropout、权重衰减等对模型施加约束或惩罚,以防止过拟合并增强泛化能力。
- 使用分布式和并行计算:可以加快训练速度,扩大生成模型的规模。
- 使用高效的自适应算法:此类算法能灵活地增强生成模型的参数和超参数,包括学习率、批量大小和历时次数。还可以提高模型的性能和收敛性,减少试错时间。有几种算法可用于优化生成模型,包括 SGD、Adam 和 AdaGrad。此外,贝叶斯优化、网格搜索和随机搜索算法也适用于超参数调整。利用这些技术,可以有效地对模型进行微调,以适应不同的数据和任务,同时解决非凸和动态优化难题。建议采用这些方法来实现生成模型的最佳结果。
附录
Transformer架构
Transformer是一种用于处理序列数据的深度学习架构,本身并不是一个生成模型,但可以被用作生成模型的基础,比如GPT,T5,BART等。
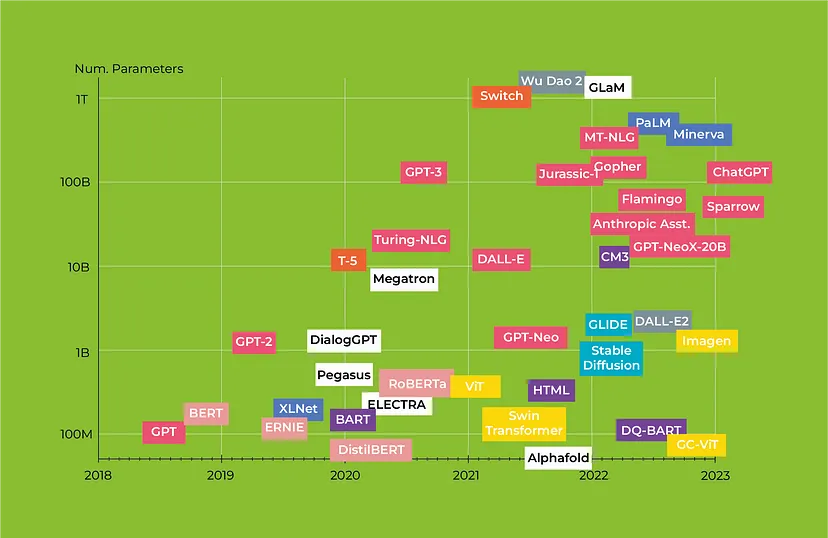
Transformer时间轴。纵轴为参数数量,颜色描述Transformer系列。[4]
Transformer架构的核心是自注意力机制,它允许模型在处理输入序列时关注序列中的不同部分,从而捕捉长距离依赖关系。
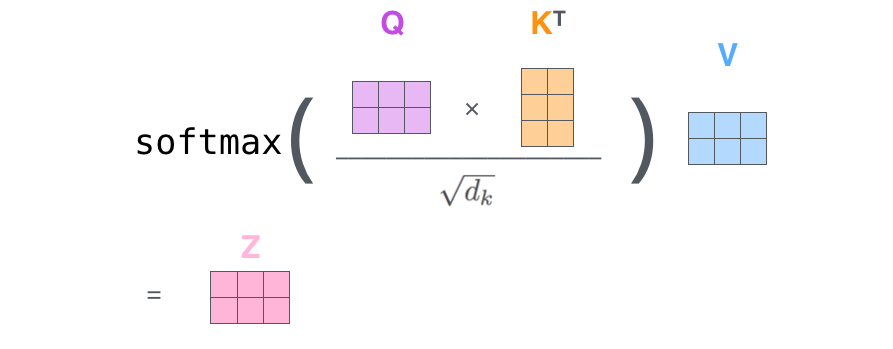
计算自注意分数矩阵(Z)。
查询矩阵(Q):n_token * n_embedding
键矩阵(K):n_token * n_embedding
值矩阵(V):n_token * n_embedding
注意力分数表明每个单词与其他单词之间的关系。
BERT大语言模型
BERT是一个基于transformer构建的大语言模型(3.4B),利用双向自注意从海量文本数据中获取知识。
| models | tokenization | input embedding | task |
|---|---|---|---|
| BERT | wordpiece(30K) | token, positional, segment | MLM; NSP |
BERT可以执行多种NLP任务,如文本分类、情感分析和命名实体识别。此外,还被广泛用作预训练模型,用于微调特定的下游任务和领域。
参考
[1] Ainur Gainetdinov. FollowDiffusion Models vs. GANs vs. VAEs: Comparison of Deep Generative Models
[2] Arash Vahdat & Karsten Kreis. Improving Diffusion Models as an Alternative To GANs, Part 1
[3] Jagreet Kaur Gill. Generative AI Models Types, Training and Evaluation Strategy
[4] Vlad. A Comprehensive Review of Transformers: from BERT to ChatGPT
[5] Li, Chengyuan, et al. “Generative AI models for different steps in architectural design: A literature review.” Frontiers of Architectural Research (2024).


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









