







15个小时彻底搞懂NLP自然语言处理(2021最新版附赠课件笔记资料)【LP自然语言处理涉及到深度学习和神经网络的介绍、 Pytorch、 RNN自然语言处理】 笔记
- 教程与代码地址
- P1 机器学习与深度学习介绍
- P2 2.神经元和神经网络
- P3 3 感知机和多层神经网路的介绍
- P4 4 激活函数和神经网络思想
- P5 1 pytorch的安装方法
- P6 2 pytorch的入门操作(一)
- P7 3 pytorch的入门操作(二)
- P8 4 上午回顾 Tensor和tensor的区别
- P9 5 pytorch的入门操作(三)
- P10 1 梯度下降和梯度的介绍
- P11 2 梯度下降的过程
- P12 3 pytorch中反向传播和梯度计算的方法
- P13 4 手动实现线性回归
- P14 5 小结
- P15 6 知识点回归
- P16 使用pytroch完成线性回归
- P17 使用GPU完成代码的训练
- P18 不同的梯度下降算法的介绍
- P19 1 数据集类的使用
- P20 2 数据加载器类的使用
- P21 3 pytorch中自带数据的使用介绍
- P22 4 mnist手写数字加载的示例
- P23 5 torchvision中transforms方法的使用
- P24 1 手写数字识别
- P25 2 损失函数的学习
- P26 3 模型的训练保存
- P27 4 模型的评估
- P28 5 循环神经网络基础
- P29 6 word embedding的理解
- P30 7 文本情感分类数据的准备
- P31 8 小结
- P32 1 复习
- P33 2 collate fn的实现
- P34 3 文本序列化的方法
- P35 4 ws的保存
- P36 5 基础模型的构建
- P37 1 RNN结果的介绍
- P38 2 rnn不同类型的介绍
- P39 3 LSTM的GRU的学习
- P40 4 上午内容回顾
- P41 5 LSTM api的介绍
- P42 6 LSTM的使用示例
- P43 7 文本情感分类模型的修改
- P44 8 梯度爆炸和梯度消失
- P45 9 pytorch的序列化容器
- P46 10 总结
- P47 1 复习
- P48 2 聊天机器人的介绍
- P49 3 企业中聊天机器人的介绍
- P50 4 项目流程介绍
- P51 5 项目环境的准备
- P52 6 词典的准备
- P53 7 停用词的准备
- P54 8 相似问题的准备
- P55 9 分词api的实现
- P56 1 文本分类的介绍
- P57 2 fasttext和介绍
- P58 4 分类模型的准备
- P59 5 模型的评估
- P60 6 模型的封装的介绍
- P61 7 fasttext原理介绍
- P62 8 小结
- P63 1 复习
- P64 2 分类模型的封装
- P65 3 哈夫曼树和哈夫曼编码
- P66 4 层次化的softmax和负采样
- P67 5 seq2seq原理的认识
- P68 6 seq2seq案例流程介绍
- P69 7 案例数据集的准备
- P70 8 准备数据集
- P71 9 编码器的完成
- P72 10 解码器的介绍
- P73 11 解码器的流程
- P74 12 模型的训练(一)
- P75 13 模型的训练(二)
- P76 14 总结
- P77 15 复习
- P78 16 seq2seq demo完成模型评估
- P79 17 seq2seq模型小结
- P80 18 teacher forcing的介绍
- P81 19 闲聊机器人准备语料
- P82 20 闲聊机器人的文本序列化
- P83 21 dataset的准备
- P84 22 seq2seq模型的搭建
- P85 1 attention的介绍
- P86 2 attention的分类介绍
- P87 3 attention weight的计算的结果
- P88 4 小结
- P89 5 复习
- P90 6 attention的实现
- P91 7 解码的过程中使用attention
- P92 8 模型的评估
- P93 1 beam search的介绍
- P94 2 beam search的实现
- P95 3 模型的优化方法
- P96 4 chatbot的封装
- P97 1 问答机器人的介绍
- P98 2 召回的介绍
- P99 3 使用tfidf实现召回
- P100 4 pysparnn的原理
- P101 5 BM25算法的介绍
- P102 6 tfidf的优化方法介绍
- P103 7 复习
- P104 8 召回的封装
- P105 9 排序介绍
- P106 10 数据集的准备
- P107 11 模型的搭建(一)
- P108 12 模型的搭建(二)
- P109 13 损失函数的模型的训练
- P110 14 模型的封装
- P111 15 封装的介绍
- P112 1.机器学习和深度学习的介绍
教程与代码地址
笔记中,图片和代码基本源自up主的视频和代码
视频地址:15个小时彻底搞懂NLP自然语言处理(2021最新版附赠课件笔记资料)【LP自然语言处理涉及到深度学习和神经网络的介绍、 Pytorch、 RNN自然语言处理】
代码地址:
讲义地址:
如果想要爬虫视频网站一样的csdn目录,可以去这里下载代码:https://github.com/JeffreyLeal/MyUtils/tree/%E7%88%AC%E8%99%AB%E5%B7%A5%E5%85%B71
P1 机器学习与深度学习介绍
P2 2.神经元和神经网络
P3 3 感知机和多层神经网路的介绍

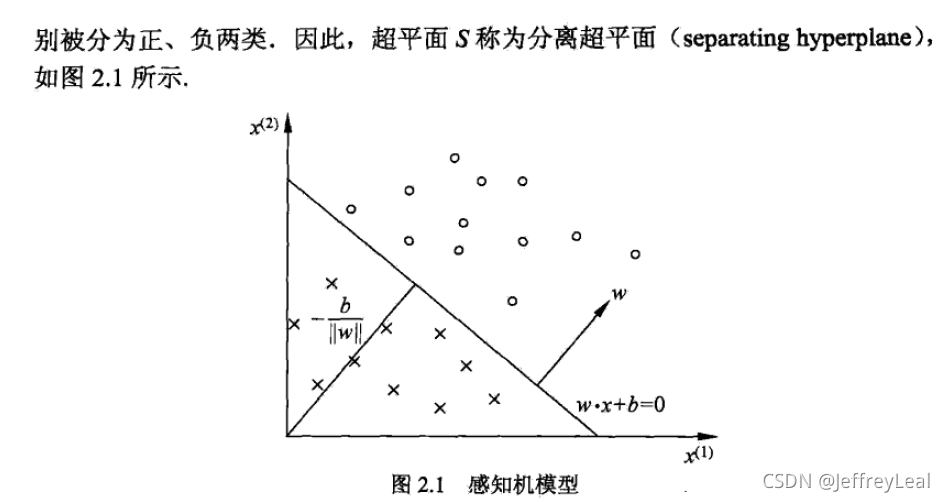
P4 4 激活函数和神经网络思想
P5 1 pytorch的安装方法
P6 2 pytorch的入门操作(一)
*args把可变形参装入tuple中
**kwargs把可变形参装入dict中
List转Numpy:numpy.array(list)
Numpy转List:array.tolist()
tensor.item:只有一个元素的张量可以转化为python中的常量
tensor.shape与tensor.size()都可以看维度,但size可以看具体位置
P7 3 pytorch的入门操作(二)
P8 4 上午回顾 Tensor和tensor的区别
P9 5 pytorch的入门操作(三)
x.add(y)和x.add_(y) 的区别:带下划线的方法会对x进行就地修改
P10 1 梯度下降和梯度的介绍
∇ w \nabla w ∇w表示梯度,导数
P11 2 梯度下降的过程
P12 3 pytorch中反向传播和梯度计算的方法
requires_grad,grad_fn,grad的含义及使用,fn is the abbreviation for function
对于pytorch中的一个tensor实例x,如果设置它的属性 requires_grad为True,loss.backward()就是根据损失函数,对参数x(requires_grad=True)计算他的梯度,并且把它累加保存到x.gard
P13 4 手动实现线性回归
numpy.reshape(-1):一个形状标注可以是-1。在这种情况下,将根据数组的长度和剩余维度推断该值。变成1行。
参数更新流程:
准备数据、参数设置requires_grad为True
循环:
判断参数梯度是否为零,不是则归零
计算损失
进行反向传播
更新参数
P14 5 小结
nn.model
要是有多个参数,上述手写代码不太实际,可以使用pytorch的api,nn.model,用前面的y = wx+b的模型举例如下:
from torch import nn
class Lr(nn.Module):
def __init__(self):
super(Lr, self).__init__() #继承父类init的参数
self.linear = nn.Linear(1, 1)
def forward(self, x):
out = self.linear(x)
return out
nn.Module定义了__call__方法,实现的就是调用forward方法,即Lr的实例,能够直接被传入参数调用,实际上调用的是forward方法并传入参数
# 实例化模型
model = Lr()
# 传入数据,计算结果
predict = model(x)
优化器
参数可以使用model.parameters()来获取,获取模型中所有requires_grad=True的参数
optimizer = optim.SGD(model.parameters(), lr=1e-3) #1. 实例化
optimizer.zero_grad() #2. 梯度置为0
loss.backward() #3. 计算梯度
optimizer.step() #4. 更新参数的值
损失函数
- 均方误差:
nn.MSELoss(),常用于回归问题 - 交叉熵损失:
nn.CrossEntropyLoss(),常用于分类问题
P15 6 知识点回归
P16 使用pytroch完成线性回归
使用api训练参数的流程(CPU版)
- 定义数据
- 定义模型
- 实例化模型,loss,和优化器
- 训练模型
循环:
获取预测值
计算损失
梯度归零
更新梯度
更新参数 - 模型评估
设置模型为评估模式,即预测模式
获取预测值,tensor类型
预测值转换成numpy类型
画图
P17 使用GPU完成代码的训练
使用api训练参数的流程(GPU版)
- 定义数据
- 定义模型
- 实例化模型,
将模型和数据的设备改为cuda,loss,和优化器 - 训练模型
循环:
获取预测值
计算损失
梯度归零
更新梯度
更新参数 - 模型评估
设置模型为评估模式,即预测模式
获取预测值,tensor类型
预测值,设备转换成cpu,再转换成numpy类型
画图,将数据的设备改为cpu
容易发生的错误
- x = torch.rand([50,1])写成x = torch.rand(50),会引起
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x50 and 1x1)
解释:可能是modole里面,m维参数w的排列本来就是以行向量的形式,所以m维输入必须以行向量的形式,如果有n个输入样品,就应该以n*m形式的张量输入。
- criterion = nn.MSELoss()
loss = criterion(y,out)
写成:
loss = nn.MSELoss()
loss = loss(y,out)
会报错
TypeError: 'Tensor' object is not callable
pytorch .detach() .detach_() 和 .data用于切断反向传播
P18 不同的梯度下降算法的介绍
P19 1 数据集类的使用
在torch中提供了数据集的基类torch.utils.data.Dataset,需要继承才能使用。
P20 2 数据加载器类的使用
dataset = CifarDataset() # 实例化dataset
data_loader = DataLoader(dataset=dataset,batch_size=10,shuffle=True,num_workers=2)
windows下num_workers=0
使用enumerate()能够返回可迭代对象的索引
#遍历,获取其中的每个batch的结果
for index, (label, context) in enumerate(data_loader):
print(index,label,context)
print("*"*100)
P21 3 pytorch中自带数据的使用介绍
torchvision提供了对图片数据处理相关的api和数据- 数据位置:
torchvision.datasets,例如:torchvision.datasets.MNIST(手写数字图片数据)
- 数据位置:
torchtext提供了对文本数据处理相关的API和数据- 数据位置:
torchtext.datasets,例如:torchtext.datasets.IMDB(电影评论文本数据)
- 数据位置:
P22 4 mnist手写数字加载的示例
import torchvision
dataset = torchvision.datasets.MNIST(root="./data",train=True,download=True,transform=None)
print(dataset[0])
可以其中数据集返回了两条数据,可以猜测为图片的数据和标签值
P23 5 torchvision中transforms方法的使用
调用MNIST返回的结果中图形数据是一个Image对象,需要对其进行处理,为了进行数据的处理,使用torchvision.transfroms的方法
- transforms.ToTensor不接受参数,因为它没有构造器,只能实例化后,调用它打call方法
data = np.random.randint(0, 255, size=12)
img = data.reshape(2,2,3)
img_tensor = transforms.ToTensor(img) # 转换成tensor
输出:
TypeError: ToTensor() takes no arguments
- torchvision.transforms.Normalize(mean, std),归一化处理,Normalized_image=(image-mean)/std
- torchvision.transforms.Compose(transforms),转换的组合拳
transforms.Compose([
torchvision.transforms.ToTensor(), #先转化为Tensor
torchvision.transforms.Normalize(mean,std) #在进行正则化
])
P24 1 手写数字识别
pytorch在构建模型的时候形状上并不会考虑batch_size
def forward(self,x):
x = x.view(-1,28*28*1) #对数据形状变形,-1表示该位置根据后面的形状自动调整,也可以用x.size(0)
x = self.fc1(x) #[batch_size,28]
x = F.relu(x) #[batch_size,28]
x = self.fc2(x) #[batch_size,10]
# return x
P25 2 损失函数的学习
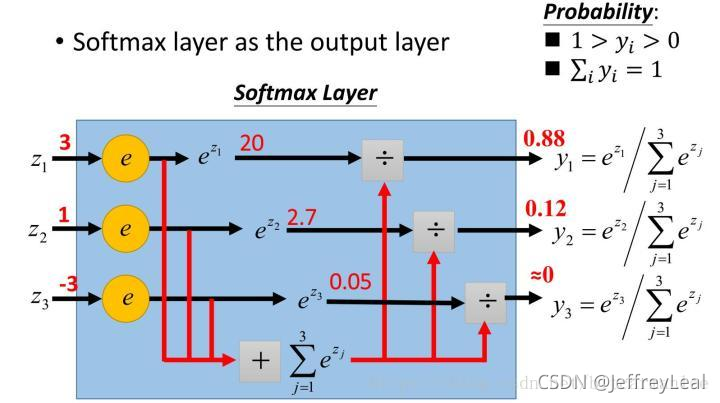 log_softmax、softmax和的nll_loss、nn.CrossEntropy区别(Pytorch学习笔记)
log_softmax、softmax和的nll_loss、nn.CrossEntropy区别(Pytorch学习笔记)
在pytorch中有两种方法实现交叉熵损失
- criterion = nn.CrossEntropyLoss()
loss = criterion(input,target) - #1. 对输出值计算softmax和取对数
output = F.log_softmax(x,dim=-1)
#2. 使用torch中带权损失
loss = F.nll_loss(output,target)
P26 3 模型的训练保存
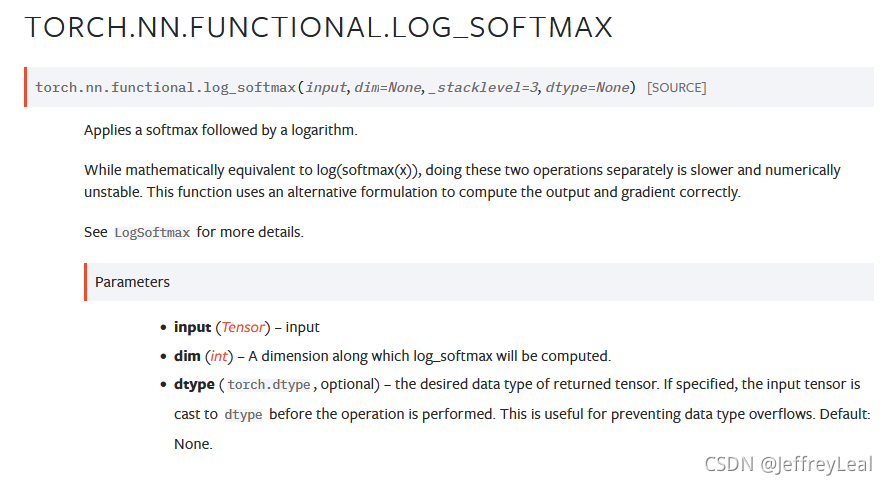
(三)PyTorch学习笔记——softmax和log_softmax的区别、CrossEntropyLoss() 与 NLLLoss() 的区别、log似然代价函数
模型的保存
一般保存模型与参数、或者只保存参数
torch.save(mnist_net.state_dict(),"model/mnist_net.pt") #保存模型参数
torch.save(optimizer.state_dict(), 'results/mnist_optimizer.pt') #保存优化器参数
模型的加载
mnist_net.load_state_dict(torch.load("model/mnist_net.pt"))
optimizer.load_state_dict(torch.load("results/mnist_optimizer.pt"))
P27 4 模型的评估
def test():
with torch.no_grad():#不用追踪参数
pred = output.data.max(1, keepdim=True)[1] #获取最大值的位置,[batch_size,1]
max()返回最大值和位置索引。
torch.max中keepdim的作用

P28 5 循环神经网络基础
P29 6 word embedding的理解
NLP经典论文:Word2vec、CBOW、Skip-gram 笔记
P30 7 文本情感分类数据的准备
python中read() readline()以及readlines()对比(转)
1. 定义tokenize的方法
python正则表达式(7)–flag修饰符、match对象属性
def tokenize(text):
# fileters = '!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n'
fileters = ['!','"','#','$','%','&','\(','\)','\*','\+',',','-','\.','/',':',';','<','=','>','\?','@'
,'\[','\\','\]','^','_','`','\{','\|','\}','~','\t','\n','\x97','\x96','”','“',]
text = re.sub("<.*?>"," ",text,flags=re.S) # 去掉html标签
text = re.sub("|".join(fileters)," ",text,flags=re.S) # 匹配符的拼接,源码中:"|" A|B, creates an RE that will match either A or B.把filter中的字符换成空格
return [i.strip() for i in text.split()] # 输出为词列表
2. 准备dataset
模板
from config import dataset_dir
class DatasetModel(Dataset):
def __init__(self, mode, parameter1, parameter2, parameter3):
super(DatasetModel,self).__init__()
if mode=="train":
# 拼接训练集地址
else:
# 拼接测试集地址
#记下显示数据的格式
self.parameter1 = parameter1
def __getitem__(self, index):
# 1. 读取数据集, 抽出index所在条目
# 2. 根据__init__()中的参数对feature进行预处理,包括分词等
# 3. 有时也需要对label进行预处理,比如str->int
return feature, label
def __len__(self):
# 读取数据集条目,记下总数
输出 总数
# 重写collate_fn()方法
def collate_fn(*batch):
return features, labels
def getDataLoader(dataset_dir, mode, parameter1):
dataset = Dataset1(dataset_dir, mode, parameter1)
dataLoader = DataLoader(dataset=dataset, batch_size ,shuffle=True, collate_fn=collate_fn)
return dataLoader
示例
data_base_path = r"data\aclImdb"
class ImdbDataset(Dataset):
def __init__(self,mode):
super(ImdbDataset,self).__init__()
if mode=="train":
text_path = [os.path.join(data_base_path,i) for i in ["train/neg","train/pos"]] # 训练集
else:
text_path = [os.path.join(data_base_path,i) for i in ["test/neg","test/pos"]] # 测试集
self.total_file_path_list = []
for i in text_path:
self.total_file_path_list.extend([os.path.join(i,j) for j in os.listdir(i)]) # 添加所有txt文件到列表中
def __getitem__(self, idx):
cur_path = self.total_file_path_list[idx]
cur_filename = os.path.basename(cur_path)
label = int(cur_filename.split("_")[-1].split(".")[0]) -1 #处理标题,获取label,转化为从[0-9]
text = tokenize(open(cur_path).read().strip()) #直接按照空格进行分词
return label,text
def __len__(self):
return len(self.total_file_path_list)
输出结果
#3. 观察数据输出结果
for idx,(label,text) in enumerate(dataloader):
print("idx:",idx)
print("table:",label)
print("text:",text)
break
idx: 0
table: tensor([3, 1])
text: [('I', 'Want'), ('thought', 'a'), ('this', 'great'), ('was', 'recipe'), ('a', 'for'), ('great', 'failure'), ('idea', 'Take'), ('but', 'a'), ('boy', 's'), ('was', 'y'), ('it', 'plot'), ('poorly', 'add'), ('executed', 'in'), ('We', 'some'), ('do', 'weak'), ('get', 'completely'), ('a', 'undeveloped'), ('broad', 'characters'), ('sense', 'and'), ('of', 'than'), ('how', 'throw'), ('complex', 'in'), ('and', 'the'), ('challenging', 'worst'), ('the', 'special'), ('backstage', 'effects'), ('operations', 'a'), ('of', 'horror'), ('a', 'movie'), ('show', 'has'), ('are', 'known'), ('but', 'Let'), ('virtually', 'stew'), ('no', 'for'), ...('show', 'somehow'), ('rather', 'destroy'), ('than', 'every'), ('anything', 'copy'), ('worth', 'of'), ('watching', 'this'), ('for', 'film'), ('its', 'so'), ('own', 'it'), ('merit', 'will')]
出现问题的原因在于Dataloader中的参数collate_fn
collate_fn的默认值为torch自定义的default_collate,collate_fn的作用就是对每个batch进行处理,而默认的default_collate处理出错,调用了zip方法,对batch里面每条数据对应位置进行zip操作。
P31 8 小结
P32 1 复习
P33 2 collate fn的实现
P34 3 文本序列化的方法
把文本中的每一个词,存储到字典当中,再将这个字典映射到word embedding空间,这个映射关系,可以使用预训练好的模型,如bert,也可以使用torch.nn.embedding中随机初始化的参数
 关于embedding的训练,图解深度学习∶训练word embedding的两种方法
关于embedding的训练,图解深度学习∶训练word embedding的两种方法
建立字典
dict.get(key[, default]):
Return the value for key if key is in the dictionary, else default. If default is not given, it defaults to None, so that this method never raises a KeyError.
字典生成式:
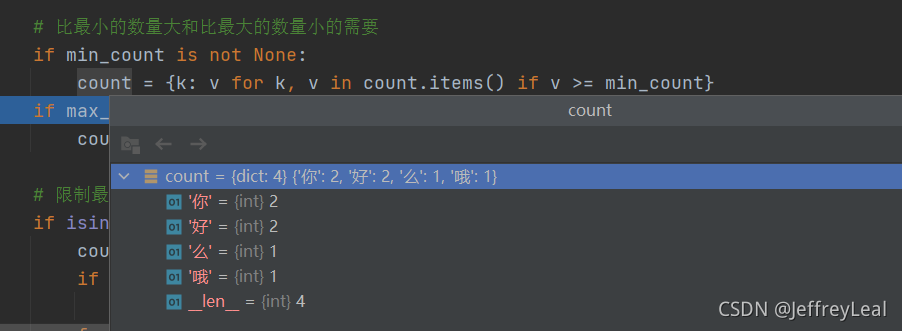 相当于:
相当于:
for k, v in count.items():
if v >= min_count:
yield k: v
去掉字典中的高频和低频词:
# 比最小的数量大和比最大的数量小的需要
if min_count is not None:
count = {k: v for k, v in count.items() if v >= min_count}
if max_count is not None:
count = {k: v for k, v in count.items() if v <= max_count}
排序去掉字典数量上限max_features以外的词
sorted(iterable, *, key=None, reverse=False):
Return a new sorted list from the items in iterable.
Has two optional arguments which must be specified as keyword arguments.
key specifies a function of one argument that is used to extract a comparison key from each element in iterable (for example, key=str.lower). The default value is None (compare the elements directly).
reverse is a boolean value. If set to True, then the list elements are sorted as if each comparison were reversed.
Use functools.cmp_to_key() to convert an old-style cmp function to a key function.
The built-in sorted() function is guaranteed to be stable. A sort is stable if it guarantees not to change the relative order of elements that compare equal — this is helpful for sorting in multiple passes (for example, sort by department, then by salary grade).
The sort algorithm uses only < comparisons between items. While defining an lt() method will suffice for sorting, PEP 8 recommends that all six rich comparisons be implemented. This will help avoid bugs when using the same data with other ordering tools such as max() that rely on a different underlying method. Implementing all six comparisons also helps avoid confusion for mixed type comparisons which can call reflected the gt() method.
For sorting examples and a brief sorting tutorial, see Sorting HOW TO.

# 限制最大的数量
if isinstance(max_feature, int):
count = sorted(list(count.items()), key=lambda x: x[1]) # 以词频进行排序
if max_feature is not None and len(count) > max_feature:
count = count[-int(max_feature):] # 截取最大的数量的词
for w, _ in count:
self.dict[w] = len(self.dict) # 给词赋予索引,默认从2开始,因为self.dict本身就有2个词
else:
for w in sorted(count.keys()):
self.dict[w] = len(self.dict)
实现吧句子转化为数组(向量)
向量中的数值为词在字典中的索引值
def transform(self, sentence,max_len=None):
实现从数组 转化为文字
def inverse_transform(self,indices):
P35 4 ws的保存

保存数据的api:pickle,对对象进行格式化储存与读取
# 对wordSequesnce进行保存
pickle.dump(ws,open("./model/ws.pkl","wb"))
#对wordSequesnce进行读取
ws = pickle.load(open("./model/ws.pkl","rb"))
显示进度条的api:tqdm
tqdm官方文档,用tqdm装载可迭代对象
修改后的def collate_fn(batch)出现效率慢的问题
texts = torch.tensor([ws.transform(i, MAX_LEN) for i in texts])
输出:
E:/Code/PythonCode/ai/nlp/scut-jeffreyleal-nlp-pytorch/demo/nlp/dataset.py:102: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ..\torch\csrc\utils\tensor_new.cpp:201.)
texts = torch.tensor([ws.transform(i, MAX_LEN) for i in texts])
显示运行效率慢,应该改为:
numpy数组与list之间的转换
texts = torch.tensor(numpy.array([ws.transform(i, MAX_LEN) for i in texts]))
P36 5 基础模型的构建
关于nn.embedding的中padding_idx的含义,padding_idx所在的那个embedding向量不会随着训练更新。
注意:模型中,__init__()内考虑输入数据只有一个的时候的模型维度,而forward()中考虑输入数据为batch_size的时候的模型维度。
class IMDBModel(nn.Module):
def __init__(self,max_len):
super(IMDBModel,self).__init__()
self.embedding = nn.Embedding(len(ws),300,padding_idx=ws.PAD) #[N,300]
self.fc = nn.Linear(max_len*300,10) #input=max_len*300, output=10
def forward(self, x):
embed = self.embedding(x) #input=(batch_size,max_len), output=(batch_size, max_len, 300)
embed = embed.view(x.size(0),-1) #参数-1把(max_len, 300)->max_len*300
out = self.fc(embed)
return F.log_softmax(out,dim=-1)
embed.view(x.size(0),-1),view是tensor类型数据的函数,-1代表后面的维度无论是多少维的,都自然展开成一个维度,官方文档示例
F.log_softmax(out,dim=-1)中,dim (int) – A dimension along which log_softmax will be computed.
,代表tensor倒数第一个维度会被计算。
坑
坑1
#1. 对IMDB的数据进行fit操作
def fit_save_word_sequence():
from wordSequence import Word2Sequence
ws = Word2Sequence()
train_path = [os.path.join(data_base_path,i) for i in ["train/neg","train/pos"]]
total_file_path_list = []
tokenized_texts = []
for i in train_path:
total_file_path_list.extend([os.path.join(i, j) for j in os.listdir(i)])
for cur_path in tqdm(total_file_path_list,ascii=True,desc="fitting"):
tokenized_texts.append(tokenize(open(cur_path, encoding='utf-8').read().strip()))
ws.fit(tokenized_texts,max_feature=20000)
# 对wordSequesnce进行保存
pickle.dump(ws,open("./model/ws.pkl","wb"))
要建立tokenized_texts列表储存分词后的多个文本,不然传入分词函数tokenize()中的sentences参数有可能分词后的单个文本,按照它分词的源码,分词后会变成单个字母,导致字典缩小并不可用。
def fit(self, sentences, min_count=1, max_count=None, max_feature=None):
"""
:param sentences:[[word1,word2,word3],[word1,word3,wordn..],...]
:param min_count: 最小出现的次数
:param max_count: 最大出现的次数
:param max_feature: 总词语的最大数量
:return:
"""
count = {}
for sentence in sentences:
for a in sentence:
if a not in count:
count[a] = 0
count[a] += 1
坑2
collate_fn()函数中,返回MAX_LEN最大文本长度的文本,model中max_len要与MAX_LEN相同
def collate_fn(batch):
MAX_LEN = 500
#MAX_LEN = max([len(i) for i in texts]) #取当前batch的最大值作为batch的最大长度
self.fc = nn.Linear(max_len*300,10) #input=max_len*300, output=10
不然会报错:
mat1 and mat2 shapes cannot be multiplied
mat1 and mat2 shapes cannot be multiplied (128x432 and 576x64)的解决
坑3
loss = F.nll_loss(output,target) #traget需要是[0,9],不能是[1-10]
这个语句接收的target,即label要是LongTensor类型的,所以要在collate_fn()中修改返回的label
labels = torch.tensor(batch[0],dtype=torch.int)
改为:
labels = torch.LongTensor(batch[0])
不然会报错:
训练代码运行到损失函数时报错RuntimeError: expected scalar type Long but found Int
训练代码运行到损失函数时报错RuntimeError: expected scalar type Long but found Int
P37 1 RNN结果的介绍
普通的神经网络问题:
- 信息的传递是单向的,这种限制虽然使得网络变得更容易学习,在很多现实任务中,网络的输出不仅和当前时刻的输入相关,也和其过去一段时间的输出相关。如问答系统,当前的回答,和前几轮的问答有关联。
- 输入和输出的维数都是固定的,不能任意改变,难以处理时序数据,比如视频、语音、文本等,时序数据的长度一般是不固定的。如翻译,输出词不固定。
P38 2 rnn不同类型的介绍
P39 3 LSTM的GRU的学习
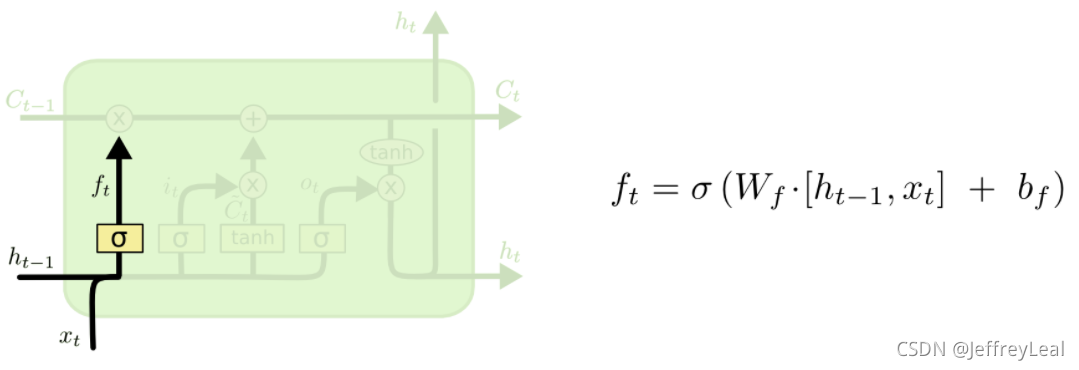
LSTM结构:
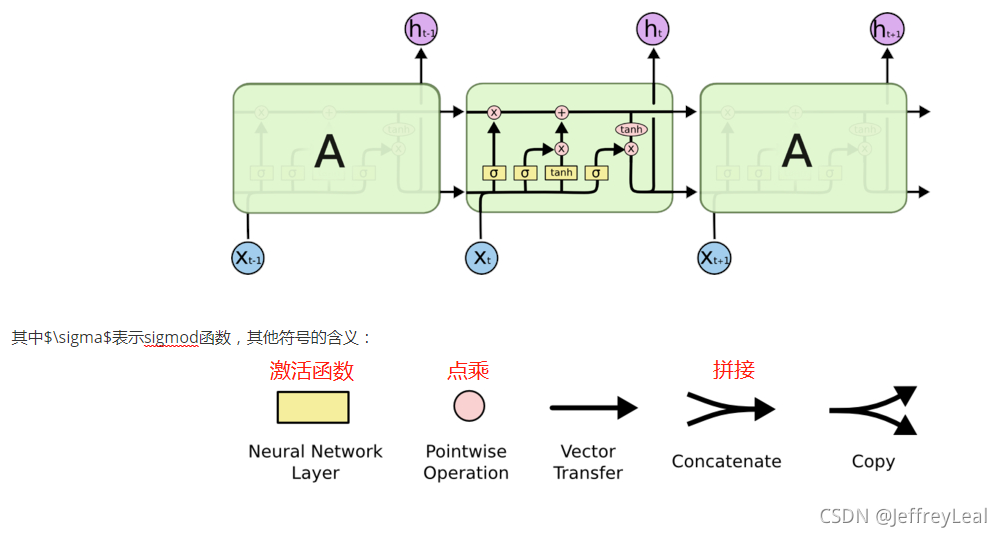
遗忘门
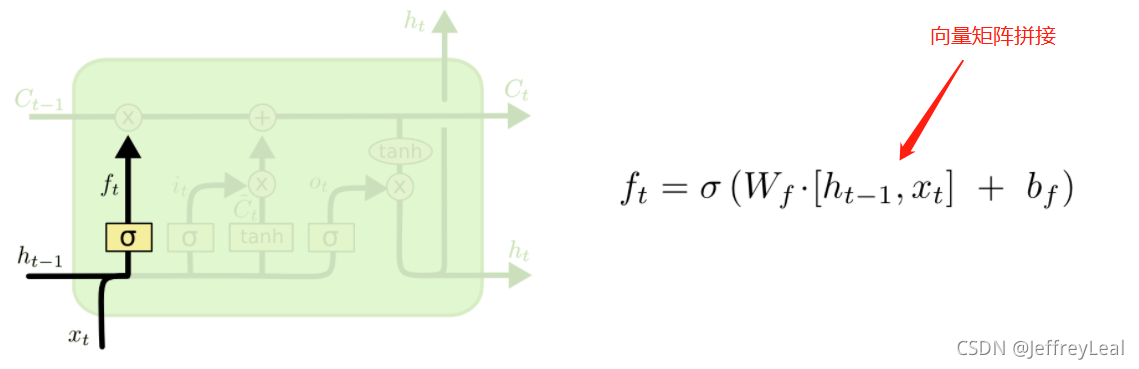
上一时刻的状态和当前的输入,共同决定上一时刻的输出,有多少会被遗忘
输入门
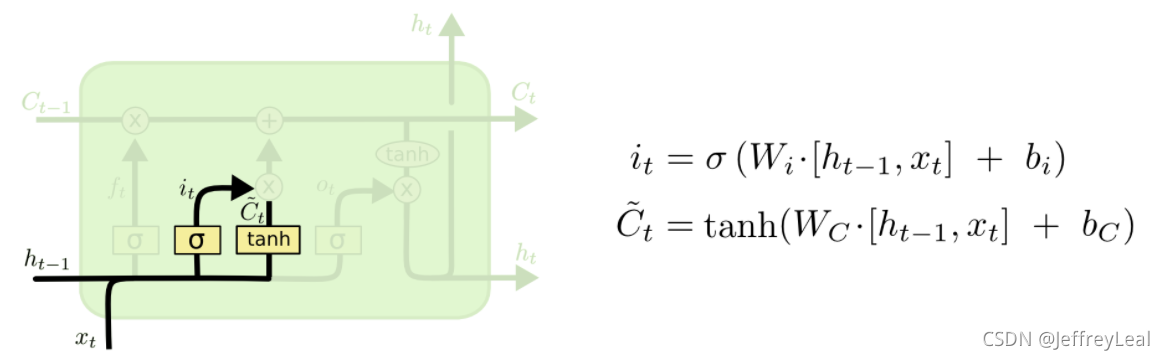
上一时刻的状态和当前的输入,共同决定当前时刻的输入,有多少会被保留
输出门

上一时刻的状态和当前的输入,当前的输出,共同决定当前的状态
GRU,LSTM的变形
NLP经典论文:Sequence to Sequence、Encoder-Decoder 、GRU 笔记
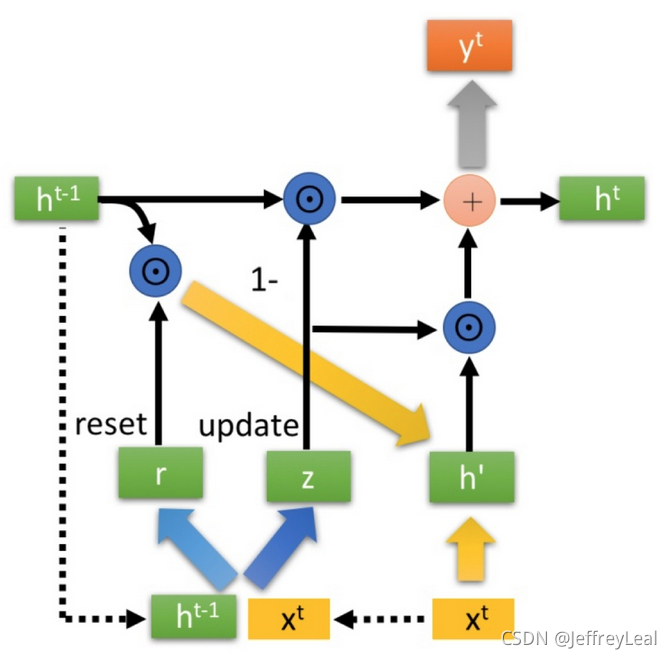
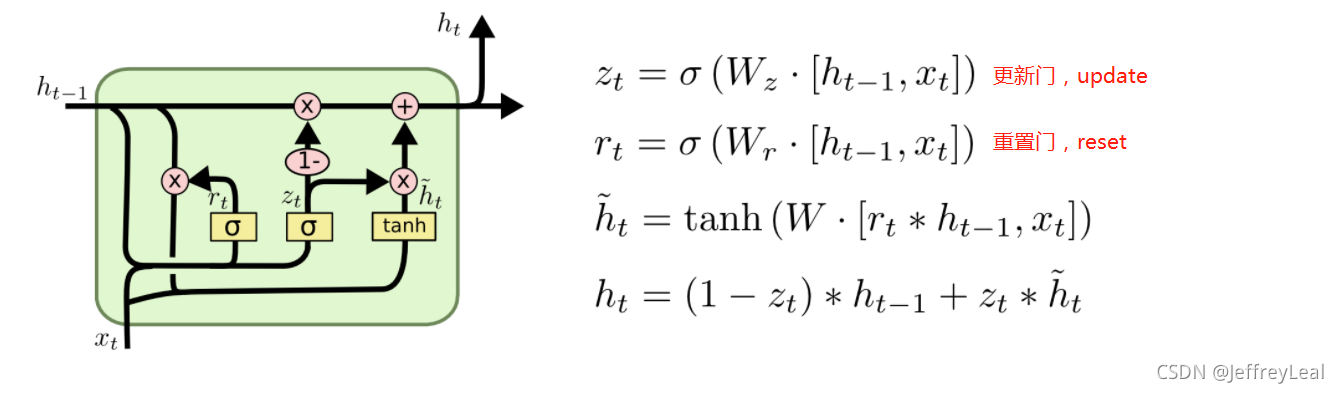
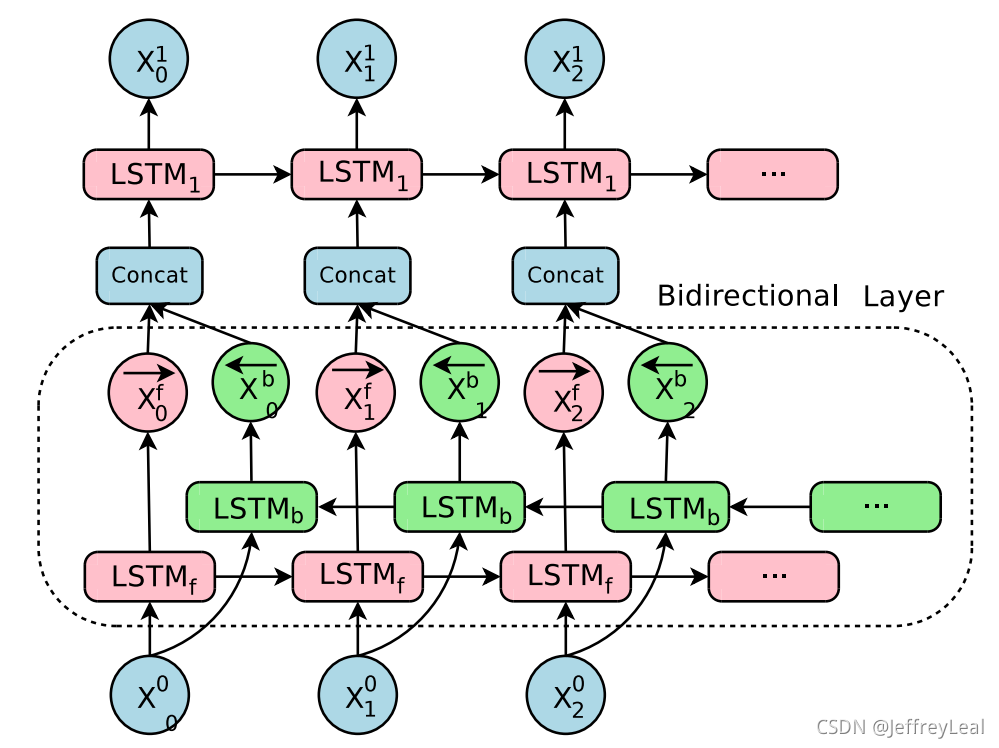
双向LSTM
P40 4 上午内容回顾
P41 5 LSTM api的介绍
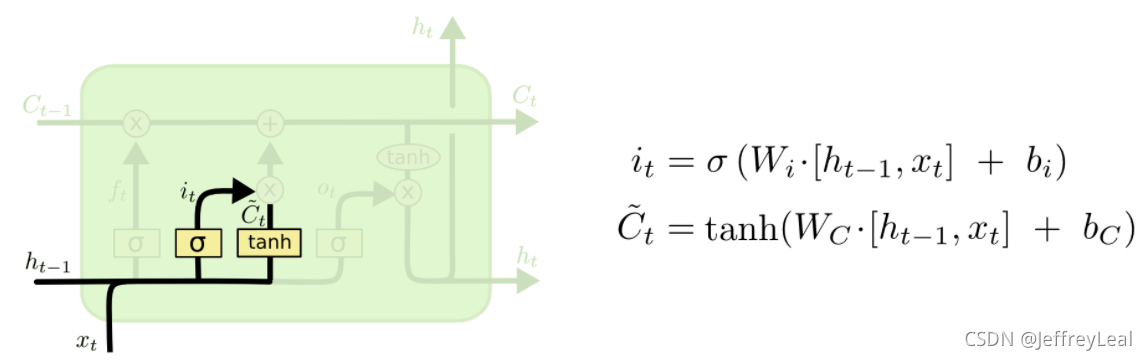

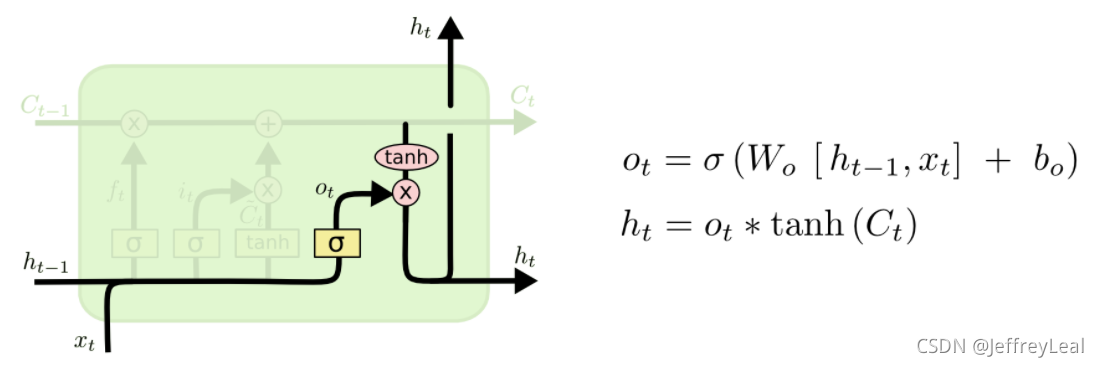
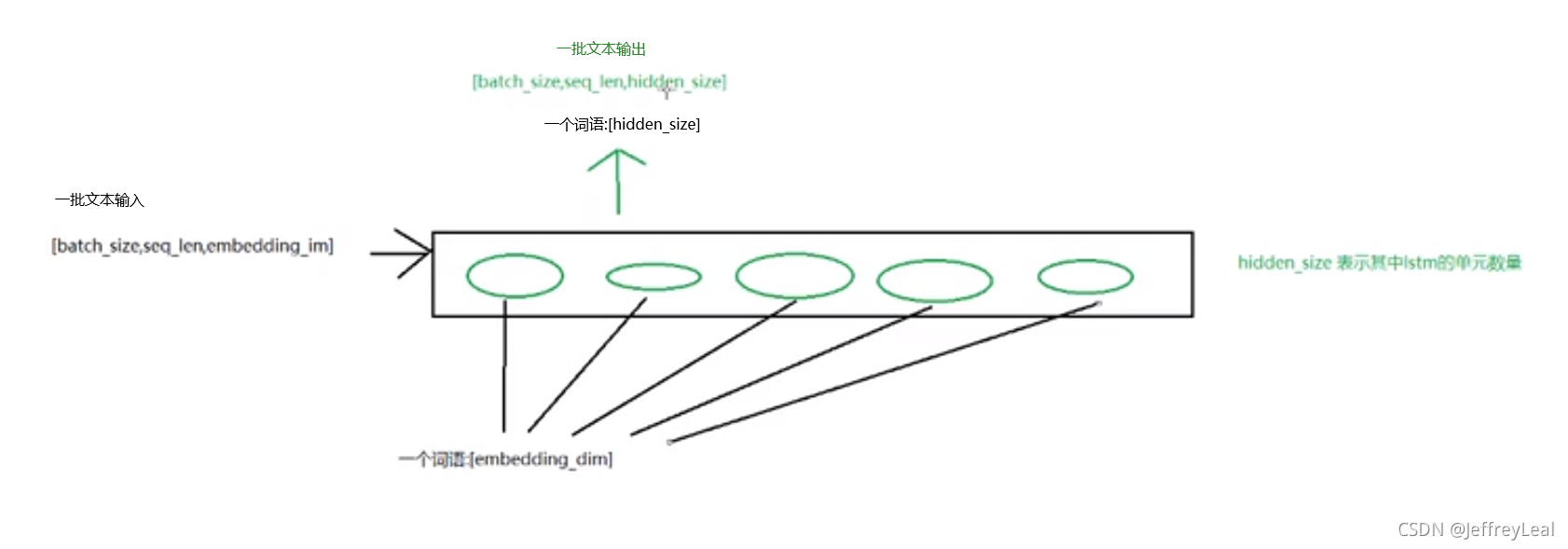
torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first,dropout,bidirectional)
input_size:输入数据的形状,即embedding_dim,一个词对应embedding向量的维度hidden_size:隐藏层神经元的数量,即每一层有多少个LSTM单元num_layer:即RNN的中LSTM单元的层数batch_first:默认值为False,输入的数据需要[seq_len,batch,feature],如果为True,则为[batch,seq_len,feature]dropout:dropout的比例,默认值为0。dropout是一种训练过程中让部分参数随机失活的一种方式,能够提高训练速度,同时能够解决过拟合的问题。这里是在LSTM的最后一层,对每个输出进行dropoutbidirectional:是否使用双向LSTM,默认是False
实例化LSTM对象之后,不仅需要传入数据,还需要前一次的h_0(前一次的隐藏状态)和c_0(前一次memory)
即:lstm(input,(h_0,c_0))
input: tensor of shape (sequence length, batch size, input_size) when batch_first=False or (batch size, sequence length, input_size) when batch_first=True,input_size=embedding_dim
2. h_n:(num_layers * num_directions, batch, hidden_size)
3. c_n: (num_layers * num_directions, batch, hidden_size)
LSTM的默认输出为output, (h_n, c_n)
output:(seq_len, batch, num_directions * hidden_size)—>batch_first=False,num_directions=2 if 双向 else 1,(batch,seq_len , num_directions * hidden_size)when batch_first=Trueh_n:(num_layers * num_directions, batch, hidden_size)c_n: (num_layers * num_directions, batch, hidden_size)
P42 6 LSTM的使用示例
P43 7 文本情感分类模型的修改
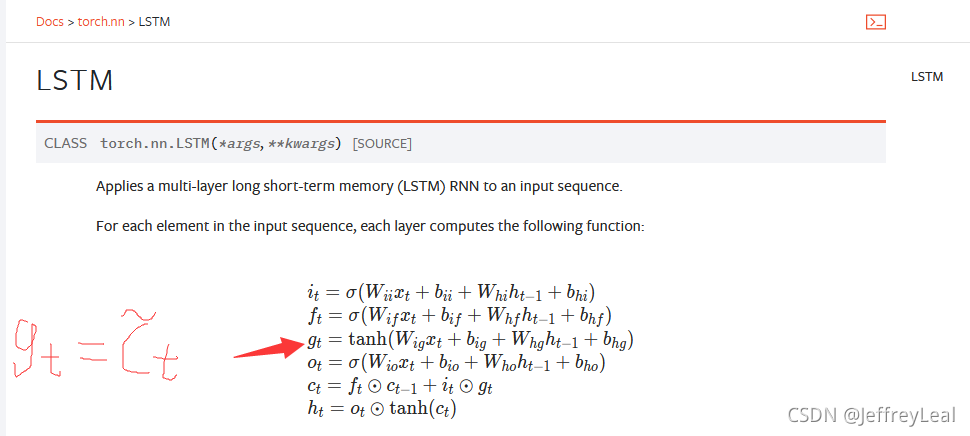
LSTM、GRU的输出:output, h_n,人们往往使用h_n,因为它包含全部输出信息,是全部输出信息的编码,而output中,并不是每一个神经元都包含全部句子的信息。
坑
output.size()的输出,最后一个值必须等于target的值域最大值,意思就是模型的最后的全连接层输出维度要等于标签数,不然会报错:
for idx,(target,input,input_lenght) in enumerate(train_dataloader):
target = target.to(device)
input = input.to(device)
optimizer.zero_grad()
output = imdb_model(input)
loss = F.nll_loss(output,target) #traget需要是[0,9],不能是[1-10]
输出:
IndexError: Target 1 is out of bounds.
P44 8 梯度爆炸和梯度消失
P45 9 pytorch的序列化容器
nn.Sequential
layer = nn.Sequential(
nn.Linear(input_dim, n_hidden_1),
nn.ReLU(True), #inplace=False 是否对输入进行就地修改,默认为False
nn.Linear(n_hidden_1, n_hidden_2),
nn.ReLU(True),
nn.Linear(n_hidden_2, output_dim) # 最后一层不需要添加激活函数
)
nn.BatchNorm1d
缓解梯度消失与爆炸,把激活后的数据拉伸到适合训练的梯度范围
P46 10 总结
P47 1 复习
P48 2 聊天机器人的介绍
P49 3 企业中聊天机器人的介绍
P50 4 项目流程介绍
P51 5 项目环境的准备
fasttest安装
pip install fasttext
安装出错:已解决ERROR: Failed building wheel for fasttext
pysparnn安装
https://github.com/facebookresearch/pysparnn
cd pysparnn (charge dirctory 到pysparnn解压后的目录,requirements.txt 的上一级目录)
pip install -r requirements.txt
python setup.py install
示例:
# 在conda下:
cd E:\download\pysparnn-master
pip install -r requirements.txt
python setup.py install
P52 6 词典的准备
1. 分词词典
1.2 词典处理
输入法的词典都是特殊格式,需要使用特殊的工具才能够把它转化为文本格式
工具名称:深蓝词库转换.exe
下载地址:https://github.com/studyzy/imewlconverter
4. 相似问答对的采集
4.1 采集相似问答对的目的
通过百度知道页面的爬虫,去获取相似性的问题
P53 7 停用词的准备
P54 8 相似问题的准备
P55 9 分词api的实现
按照逐个逐个字去分词
读取句子判断字符类型的顺序:字母->标点符号->中文字
# 这里的by_word,指的是by_character,即一个一个字,而不是词
def _cut_by_word(sentence):
# 对中文按照字进行处理,对英文不分为字母
sentence = re.sub("\s+"," ",sentence) # 所有类型的间隔符->空格
sentence = sentence.strip()
result = []
temp = ""
for word in sentence:
if word.lower() in letters: #letters:'abcdefghijklmnopqrstuvwxyz'
temp += word.lower() # 把一个单词的所有字母拼接到一起,保留整个单词
else:
if temp != "": #temp是字母串,temp的下一个待拼接的字符word不是字母,意思英文单词捕获完成
result.append(temp)
temp = ""
if word.strip() in filters: #标点符号,感觉这个strip()没有用,读取字符不会读取2个,空格也是一个字符
continue
else: #是单个字
result.append(word)
if temp != "": #最后的temp中包含字母
result.append(temp)
return result
路径问题
导包路径
使用工程路径
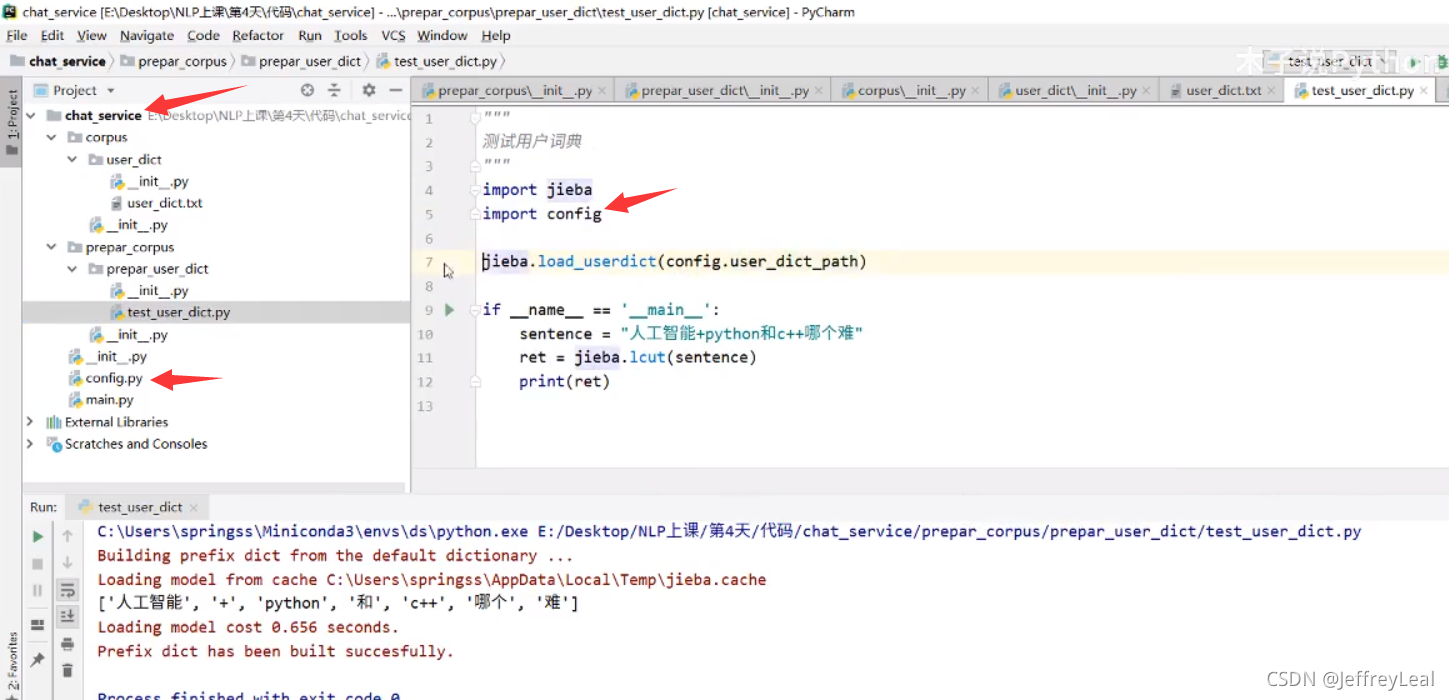
config就在工程目录下,所以直接导入不会出错,如果config不在工程目录下,则需要:
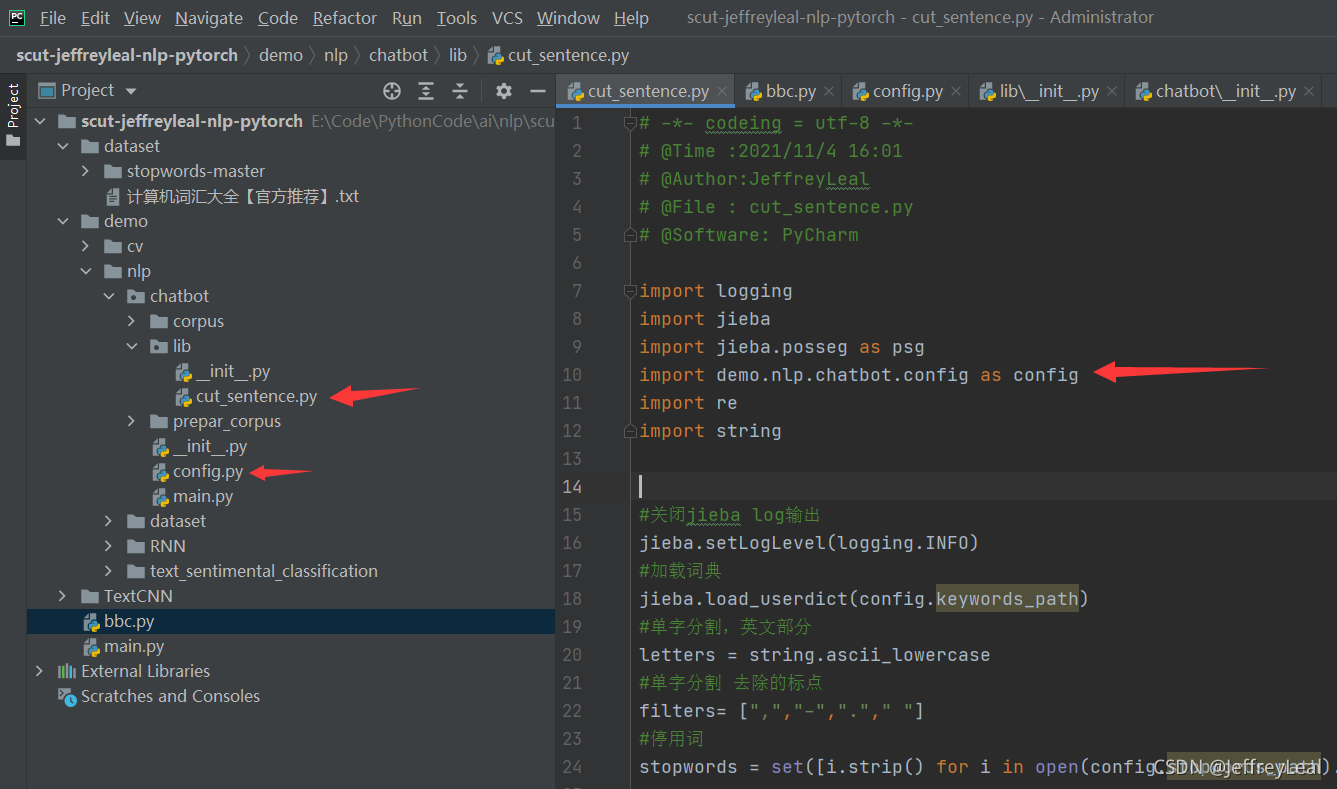
文件路径
- 相对路径
- 绝对路径
- 没有工程路径
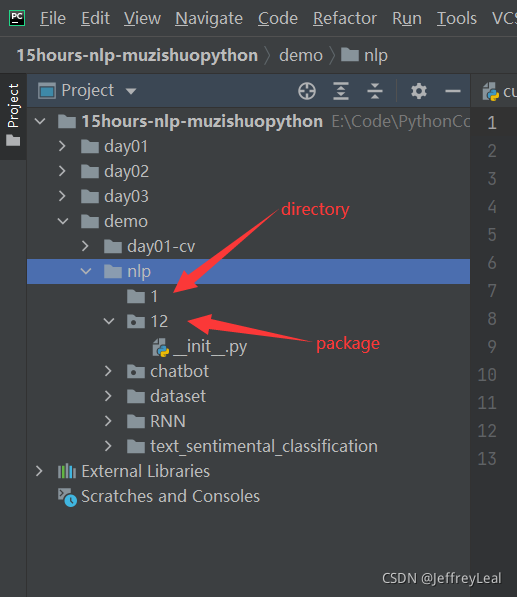
工程文件结构
文件和包的区别在于,是否有__init__.py文件
python模块中__init__.py的作用
【----init.py文件的作用以及内容----】【----20180102----】
Python init.py 作用详解
P56 1 文本分类的介绍
文本预处理标准:standard preprocessing scripts
P57 2 fasttext和介绍
P58 4 分类模型的准备
P59 5 模型的评估
P60 6 模型的封装的介绍
P61 7 fasttext原理介绍
1. fastText的模型架构
1.1 N-garm的理解
1.1.1 bag of word
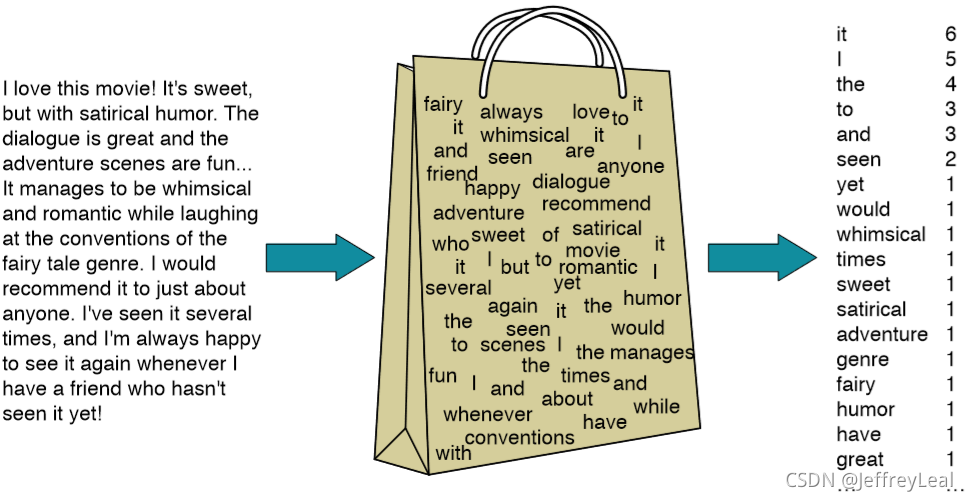
bag of word 又称为bow,称为词袋。是一种只统计词频的手段。
P62 8 小结
P63 1 复习
P64 2 分类模型的封装
P65 3 哈夫曼树和哈夫曼编码
哈夫曼树
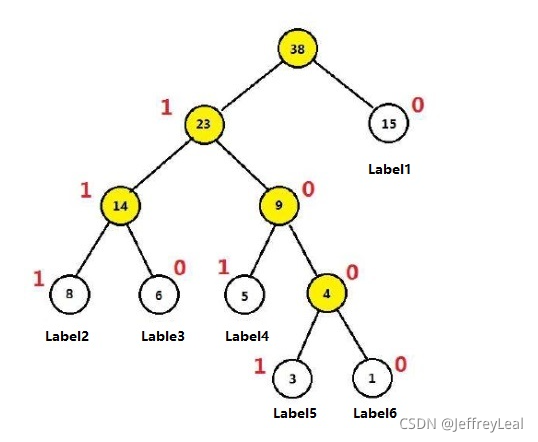
哈夫曼编码
显然字使用频率越小权值越小,权值越小叶子就越靠下,于是频率小编码长,频率高编码短,这样就保证了此树的最小带权路径长度效果上就是传送报文的最短长度
对于从根节点出发,到达Label5一共经历4次2分类,将每次分类结果的概率写出来就是:
- 第一次:$P(1|X,\theta_1) = \delta(X^T\theta_1) $ ,即从根节点到23节点的概率是在知道X和 θ 1 \theta_1 θ1的情况下取值为1的概率
- 第二次:$P(0|X,\theta_2) =1- \delta(X^T\theta_2) $
- 第三次:$P(0 |X,\theta_3) =1- \delta(X^T\theta_4) $
- 第四次:$P(1|X,\theta_4) = \delta(X^T\theta_4) $
P66 4 层次化的softmax和负采样
NLP经典论文:Word2vec、CBOW、Skip-gram 笔记,这里介绍了分层softmax和负采样。
层次化softmax的好处:传统的softmax的时间复杂度为L(Labels的数量),但是使用层次化softmax之后时间复杂度的log(L) (二叉树高度和宽度的近似),从而在多分类的场景提高了效率
P67 5 seq2seq原理的认识
NLP经典论文:Sequence to Sequence、Encoder-Decoder 、GRU 笔记
Sequence to sequence (seq2seq)是由encoder(编码器)和decoder(解码器)两个RNN的组成的。其中encoder负责对输入句子的理解,转化为context vector,decoder负责对理解后的句子的向量进行处理,解码,获得输出。
总之:Seq2seq模型中的encoder接受一个长度为M的序列,得到1个 context vector,之后decoder把这一个context vector转化为长度为N的序列作为输出,从而构成一个M to N的模型,能够处理很多不定长输入输出的问题
P68 6 seq2seq案例流程介绍
P69 7 案例数据集的准备
P70 8 准备数据集
P71 9 编码器的完成
P72 10 解码器的介绍
P73 11 解码器的流程
P74 12 模型的训练(一)
P75 13 模型的训练(二)
P76 14 总结
P77 15 复习
P78 16 seq2seq demo完成模型评估
P79 17 seq2seq模型小结
P80 18 teacher forcing的介绍
P81 19 闲聊机器人准备语料
P82 20 闲聊机器人的文本序列化
P83 21 dataset的准备
P84 22 seq2seq模型的搭建
P85 1 attention的介绍
NLP经典论文:Attention、Transformer 笔记















 1775
1775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









