






Kaggle Google - Isolated Sign Language Recognition竞赛链接Kaggle
第一名比赛方案链接Link
Train 笔记
下载轮子
!pip install -q /kaggle/input/tensorflow-2120/tensorflow-2.12.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
!pip install -q tensorflow-addons==0.20.0
!pip install -q git+https://github.com/hoyso48/tf-utils@main
加载要用到的库
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow_addons as tfa
import matplotlib.pyplot as plt
import matplotlib as mpl
import tensorflow.keras.mixed_precision as mixed_precision
from tqdm.autonotebook import tqdm
import sklearn
from tf_utils.schedules import OneCycleLR, ListedLR
from tf_utils.callbacks import Snapshot, SWA
from tf_utils.learners import FGM, AWP #
import os
import time
import pickle
import math
import random
import sys
import cv2
import gc
import glob
import datetime
print(f'Tensorflow Version: {tf.__version__}')
print(f'Python Version: {sys.version}')
这段代码主要是用于设置随机数种子和获取分布式策略。其中,seed_everything函数用于设置所有随机数生成器的种子,以确保结果的可重复性。get_strategy函数用于获取分布式策略,根据设备类型选择不同的策略,包括TPU、GPU和CPU。最后返回策略、副本数和是否使用TPU的标志。
# Seed all random number generators
def seed_everything(seed=42):
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
def get_strategy(device='TPU-VM'):
if "TPU" in device:
tpu = 'local' if device=='TPU-VM' else None
print("connecting to TPU...")
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect(tpu=tpu)
strategy = tf.distribute.TPUStrategy(tpu)
IS_TPU = True
if device == "GPU" or device=="CPU":
ngpu = len(tf.config.experimental.list_physical_devices('GPU'))
if ngpu>1:
print("Using multi GPU")
strategy = tf.distribute.MirroredStrategy()
elif ngpu==1:
print("Using single GPU")
strategy = tf.distribute.get_strategy()
else:
print("Using CPU")
strategy = tf.distribute.get_strategy()
CFG.device = "CPU"
if device == "GPU":
print("Num GPUs Available: ", ngpu)
AUTO = tf.data.experimental.AUTOTUNE
REPLICAS = strategy.num_replicas_in_sync
print(f'REPLICAS: {REPLICAS}')
return strategy, REPLICAS, IS_TPU
STRATEGY, N_REPLICAS, IS_TPU = get_strategy()
TRAIN_FILENAMES = glob.glob('/kaggle/input/islr-5fold/*.tfrecords')
print(len(TRAIN_FILENAMES))
# Train DataFrame
train_df = pd.read_csv('/kaggle/input/asl-signs/train.csv')
display(train_df.head())
display(train_df.info())
import re
def count_data_items(filenames):
n = [int(re.compile(r"-([0-9]*)\.").search(filename.split('/')[-1]).group(1)) for filename in filenames]
return np.sum(n)
print(count_data_items(TRAIN_FILENAMES), len(train_df))
assert count_data_items(TRAIN_FILENAMES) == len(train_df)
ROWS_PER_FRAME = 543
MAX_LEN = 384
CROP_LEN = MAX_LEN
NUM_CLASSES = 250
PAD = -100.
NOSE=[
1,2,98,327
]
LNOSE = [98]
RNOSE = [327]
LIP = [ 0,
61, 185, 40, 39, 37, 267, 269, 270, 409,
291, 146, 91, 181, 84, 17, 314, 405, 321, 375,
78, 191, 80, 81, 82, 13, 312, 311, 310, 415,
95, 88, 178, 87, 14, 317, 402, 318, 324, 308,
]
LLIP = [84,181,91,146,61,185,40,39,37,87,178,88,95,78,191,80,81,82]
RLIP = [314,405,321,375,291,409,270,269,267,317,402,318,324,308,415,310,311,312]
POSE = [500, 502, 504, 501, 503, 505, 512, 513]
LPOSE = [513,505,503,501]
RPOSE = [512,504,502,500]
REYE = [
33, 7, 163, 144, 145, 153, 154, 155, 133,
246, 161, 160, 159, 158, 157, 173,
]
LEYE = [
263, 249, 390, 373, 374, 380, 381, 382, 362,
466, 388, 387, 386, 385, 384, 398,
]
LHAND = np.arange(468, 489).tolist()
RHAND = np.arange(522, 543).tolist()
POINT_LANDMARKS = LIP + LHAND + RHAND + NOSE + REYE + LEYE #+POSE
NUM_NODES = len(POINT_LANDMARKS)
CHANNELS = 6*NUM_NODES
print(NUM_NODES)
print(CHANNELS)
def interp1d_(x, target_len, method='random'):
'''这是一段Python代码,使用了TensorFlow库。
函数名为interp1d_,作用是对输入的坐标信息进行插值处理。
参数x为输入的坐标信息,target_len为目标长度,method为插值方法。
首先使用tf.shape函数获取坐标信息的长度,然后使用tf.maximum函数确保目标长度不小于1。
如果method为'random',则使用tf.random.uniform函数生成两个随机数,
如果第一个随机数小于0.33,则使用双线性插值方法对坐标信息进行插值处理;
否则,如果第二个随机数小于0.5,则使用三次插值方法对坐标信息进行插值处理;
否则,使用最近邻插值方法对坐标信息进行插值处理。
如果method不为'random',则直接使用指定的插值方法对坐标信息进行插值处理。
最终返回插值处理后的坐标信息。'''
length = tf.shape(x)[1]
target_len = tf.maximum(1,target_len)
if method == 'random':
if tf.random.uniform(()) < 0.33: # 用于从均匀分布中输出随机值。
x = tf.image.resize(x, (target_len,tf.shape(x)[1]),'bilinear') # 双线性插值
else:
if tf.random.uniform(()) < 0.5:
x = tf.image.resize(x, (target_len,tf.shape(x)[1]),'bicubic') # 三次插值
else:
x = tf.image.resize(x, (target_len,tf.shape(x)[1]),'nearest') # 最近邻插值
else:
x = tf.image.resize(x, (target_len,tf.shape(x)[1]),method)
return x
'''这两段代码是用于计算张量中的NaN值的平均值和标准差。
第一段代码中,tf.where()函数用于将NaN值替换为0,
然后使用tf.reduce_sum()函数计算元素之和,最后除以非NaN值的数量来计算平均值。
第二段代码中,如果中心值为None,则使用第一段代码中的函数计算中心值。
然后计算差值并使用tf_nan_mean()函数计算平均值,最后使用tf.math.sqrt()函数计算标准差。'''
def tf_nan_mean(x, axis=0, keepdims=False):
#tf.reduce_sum()作用是按一定方式计算张量中元素之和
return tf.reduce_sum(tf.where(tf.math.is_nan(x), tf.zeros_like(x), x), axis=axis, keepdims=keepdims) / tf.reduce_sum(tf.where(tf.math.is_nan(x), tf.zeros_like(x), tf.ones_like(x)), axis=axis, keepdims=keepdims)
def tf_nan_std(x, center=None, axis=0, keepdims=False):
if center is None: # 如果中心是None
center = tf_nan_mean(x, axis=axis, keepdims=True) #返回center
d = x - center
return tf.math.sqrt(tf_nan_mean(d * d, axis=axis, keepdims=keepdims))
'''
这段代码定义了一个名为Preprocess的类,继承自tf.keras.layers.Layer。
该类的作用是对输入进行预处理,包括截取、标准化、差分等操作。
其中,max_len和point_landmarks是该类的两个参数,用于控制截取和差分的长度和位置。
call方法是该类的核心方法,用于实现具体的预处理操作。
具体实现包括对输入进行维度处理、计算均值和标准差、截取、差分、拼接等操作。
最后,使用tf.where函数将NaN值替换为0。
'''
class Preprocess(tf.keras.layers.Layer):
#当我们需要函数接收带关键字的参数作为输入的时候,应当使用**kwargs
def __init__(self, max_len=MAX_LEN, point_landmarks=POINT_LANDMARKS, **kwargs):
super().__init__(**kwargs)
self.max_len = max_len
self.point_landmarks = point_landmarks
def call(self, inputs):
if tf.rank(inputs) == 3: #tf.rank返回维度
x = inputs[None,...]
else:
x = inputs
#tf.gather(该接口的作用:就是抽取出params的第axis维度上在indices里面所有的index
mean = tf_nan_mean(tf.gather(x, [17], axis=2), axis=[1,2], keepdims=True)
mean = tf.where(tf.math.is_nan(mean), tf.constant(0.5,x.dtype), mean)
x = tf.gather(x, self.point_landmarks, axis=2) #N,T,P,C
std = tf_nan_std(x, center=mean, axis=[1,2], keepdims=True)
x = (x - mean)/std
if self.max_len is not None:
x = x[:,:self.max_len] #截取
length = tf.shape(x)[1]
x = x[...,:2]
dx = tf.cond(tf.shape(x)[1]>1,lambda:tf.pad(x[:,1:] - x[:,:-1], [[0,0],[0,1],[0,0],[0,0]]),lambda:tf.zeros_like(x))
dx2 = tf.cond(tf.shape(x)[1]>2,lambda:tf.pad(x[:,2:] - x[:,:-2], [[0,0],[0,2],[0,0],[0,0]]),lambda:tf.zeros_like(x))
x = tf.concat([
tf.reshape(x, (-1,length,2*len(self.point_landmarks))),
tf.reshape(dx, (-1,length,2*len(self.point_landmarks))),
tf.reshape(dx2, (-1,length,2*len(self.point_landmarks))),
], axis = -1)
x = tf.where(tf.math.is_nan(x),tf.constant(0.,x.dtype),x)
return x
def decode_tfrec(record_bytes):
'''这段代码是用来解析TensorFlow记录文件(TFRecord)中的数据。
具体来说,它将记录字节解析为一个包含两个特征的字典:一个是名为“coordinates”的字符串特征,另一个是名为“sign”的整数特征。
然后,它使用TensorFlow的解码函数将“coordinates”特征中的原始字节解码为浮点数,并将其重新形状为一个三维张量。
最后,它将解码后的特征和整数特征打包成一个字典并返回。'''
features = tf.io.parse_single_example(record_bytes, {
'coordinates': tf.io.FixedLenFeature([], tf.string),
'sign': tf.io.FixedLenFeature([], tf.int64),
})
out = {}
out['coordinates'] = tf.reshape(tf.io.decode_raw(features['coordinates'], tf.float32), (-1,ROWS_PER_FRAME,3))
out['sign'] = features['sign']
return out
def filter_nans_tf(x, ref_point=POINT_LANDMARKS):
'''这是一段Python代码,使用了TensorFlow库。函数名为filter_nans_tf,
作用是过滤掉输入张量x中在参考点ref_point处存在NaN值的样本。
具体实现是通过tf.gather函数获取x张量在ref_point处的值,
然后使用tf.math.is_nan函数判断是否为NaN值,
再使用tf.reduce_all函数判断是否所有样本都存在NaN值,
最后使用tf.boolean_mask函数过滤掉存在NaN值的样本。'''
#tf.math.logical_not()x和y两个张量在相应位置上做非(!)操作。
mask = tf.math.logical_not(tf.reduce_all(tf.math.is_nan(tf.gather(x,ref_point,axis=1)), axis=[-2,-1]))
x = tf.boolean_mask(x, mask, axis=0)
return x
def preprocess(x, augment=False, max_len=MAX_LEN):
'''这是一段Python代码,使用了TensorFlow库。
函数名为preprocess,作用是对输入数据进行预处理。
首先从输入数据x中获取坐标信息,然后使用filter_nans_tf函数过滤掉存在NaN值的样本。
如果augment参数为True,则使用augment_fn函数对坐标信息进行增强处理。
接着使用tf.ensure_shape函数确保坐标信息的形状为(None,ROWS_PER_FRAME,3),其中None表示样本数量不确定。
最后使用Preprocess(max_len=max_len)对坐标信息进行预处理,并将处理后的结果转换为tf.float32类型的张量,
同时将标签信息转换为one-hot编码的形式。'''
coord = x['coordinates']
coord = filter_nans_tf(coord)
if augment:
coord = augment_fn(coord, max_len=max_len)
coord = tf.ensure_shape(coord, (None,ROWS_PER_FRAME,3))
return tf.cast(Preprocess(max_len=max_len)(coord)[0],tf.float32), tf.one_hot(x['sign'], NUM_CLASSES)
def flip_lr(x):
'''这段代码是一个函数,用于将输入的张量沿着最后一个维度进行翻转。
具体实现是先将输入张量按照最后一个维度进行拆分,然后将第一个元素取反,
再将拆分后的张量重新组合起来,最后按照指定的索引位置进行交换。
其中,tf.gather用于按照指定的索引位置获取张量中的元素,
tf.tensor_scatter_nd_update用于按照指定的索引位置更新张量中的元素。'''
x,y,z = tf.unstack(x, axis=-1)
x = 1-x
new_x = tf.stack([x,y,z], -1)
new_x = tf.transpose(new_x, [1,0,2]) #将new_x改为(y,x,z)
lhand = tf.gather(new_x, LHAND, axis=0)
rhand = tf.gather(new_x, RHAND, axis=0)
#tf.tensor_scatter_nd_update(对应位置的索引赋值
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(LHAND)[...,None], rhand)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(RHAND)[...,None], lhand)
llip = tf.gather(new_x, LLIP, axis=0)
rlip = tf.gather(new_x, RLIP, axis=0)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(LLIP)[...,None], rlip)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(RLIP)[...,None], llip)
lpose = tf.gather(new_x, LPOSE, axis=0)
rpose = tf.gather(new_x, RPOSE, axis=0)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(LPOSE)[...,None], rpose)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(RPOSE)[...,None], lpose)
leye = tf.gather(new_x, LEYE, axis=0)
reye = tf.gather(new_x, REYE, axis=0)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(LEYE)[...,None], reye)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(REYE)[...,None], leye)
lnose = tf.gather(new_x, LNOSE, axis=0)
rnose = tf.gather(new_x, RNOSE, axis=0)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(LNOSE)[...,None], rnose)
new_x = tf.tensor_scatter_nd_update(new_x, tf.constant(RNOSE)[...,None], lnose)
new_x = tf.transpose(new_x, [1,0,2]) #将new_x再改为(x,y,z)
return new_x #左右翻转图像
def resample(x, rate=(0.8,1.2)):
'''这段代码是一个函数,名为resample,它的作用是对输入的x进行重采样。
重采样的比例在0.8到1.2之间随机生成。
函数中使用了TensorFlow的函数tf.random.uniform来生成随机数,
使用了tf.shape获取x的长度,使用了tf.cast进行类型转换,
使用了interp1d_函数对x进行插值得到新的重采样后的x。最后返回新的x。'''
rate = tf.random.uniform((), rate[0], rate[1])
length = tf.shape(x)[0]
new_size = tf.cast(rate*tf.cast(length,tf.float32), tf.int32) #tf.cast()函数用于执行tensorflow中张量数据类型转换
new_x = interp1d_(x, new_size) #进行插值操作
return new_x
def spatial_random_affine(xyz,
scale = (0.8,1.2),
shear = (-0.15,0.15),
shift = (-0.1,0.1),
degree = (-30,30),
):
'''这段代码是一个用于进行空间随机仿射变换的函数。
其中包含了对输入的三维坐标进行缩放、剪切、旋转和平移等操作。
具体实现中使用了 TensorFlow 的一些函数和运算符,
如 tf.constant、tf.random.uniform、tf.identity、@ 运算符和 tf.concat 等。
其中,通过 @ 运算符可以方便地实现矩阵相乘,
而 tf.identity 则用于创建一个恒等矩阵。
此外,代码中还使用了 numpy 库中的 np.pi 常量。'''
center = tf.constant([0.5,0.5])
if scale is not None:
scale = tf.random.uniform((),*scale)
xyz = scale*xyz
if shear is not None:
#Numpy 中 a[::,1] 等价于 a[...,1]
xy = xyz[...,:2]
z = xyz[...,2:]
shear_x = shear_y = tf.random.uniform((),*shear)
if tf.random.uniform(()) < 0.5:
shear_x = 0.
else:
shear_y = 0.
#tf.identity在计算图内部创建了两个节点,send / recv节点,用来发送和接受两个变量,如果两个变量在不同的设备上,比如 CPU 和 GPU,那么将会复制变量,如果在一个设备上,将会只是一个引用。
shear_mat = tf.identity([
[1.,shear_x],
[shear_y,1.]
])
xy = xy @ shear_mat #通过@运算符可以方便的实现矩阵相乘,还可以通过tf.matmul(a, b)实现
center = center + [shear_y, shear_x]
xyz = tf.concat([xy,z], axis=-1)
if degree is not None:
xy = xyz[...,:2]
z = xyz[...,2:]
xy -= center
degree = tf.random.uniform((),*degree)
radian = degree/180*np.pi
c = tf.math.cos(radian)
s = tf.math.sin(radian)
rotate_mat = tf.identity([
[c,s],
[-s, c],
])
xy = xy @ rotate_mat
xy = xy + center
xyz = tf.concat([xy,z], axis=-1)
if shift is not None:
shift = tf.random.uniform((),*shift)
xyz = xyz + shift
return xyz
def temporal_crop(x, length=MAX_LEN):
'''这段代码是一个函数,名为temporal_crop,它的作用是对输入的x进行裁剪,使其长度为length。
如果没有指定length,则默认为MAX_LEN。
具体实现是先获取x的长度l,然后生成一个随机数offset,范围在[0, l-length]之间,
最后将x从offset开始裁剪,长度为length。
裁剪后的x作为函数的返回值。
这段代码使用了TensorFlow库中的一些函数,如tf.shape、tf.random.uniform和tf.clip_by_value。'''
l = tf.shape(x)[0]
offset = tf.random.uniform((), 0, tf.clip_by_value(l-length,1,length), dtype=tf.int32)
x = x[offset:offset+length]
return x
def temporal_mask(x, size=(0.2,0.4), mask_value=float('nan')):
'''这段代码是一个用于生成时间掩码的函数,主要用于在训练神经网络时对输入数据进行随机掩码处理,以增强模型的鲁棒性。
函数的输入参数x是一个张量,size是一个元组,表示掩码的大小范围,mask_value是掩码的值。
函数首先获取输入张量的长度l,然后随机生成掩码的大小mask_size,并将其转换为整数类型。
接着,随机生成掩码的偏移量mask_offset,并使用tf.tensor_scatter_nd_update函数将掩码应用到输入张量的相应位置上。
最后,函数返回处理后的张量。'''
l = tf.shape(x)[0]
mask_size = tf.random.uniform((), *size)
mask_size = tf.cast(tf.cast(l, tf.float32) * mask_size, tf.int32)
mask_offset = tf.random.uniform((), 0, tf.clip_by_value(l-mask_size,1,l), dtype=tf.int32)
x = tf.tensor_scatter_nd_update(x,tf.range(mask_offset, mask_offset+mask_size)[...,None],tf.fill([mask_size,543,3],mask_value))
return x
def spatial_mask(x, size=(0.2,0.4), mask_value=float('nan')):
'''这段代码是一个用于生成空间掩码的函数。
它使用了TensorFlow库中的随机数生成函数,生成了一个随机的掩码位置和大小,并将掩码应用于输入张量x的第一和第二维。
掩码的值为NaN,即将掩码位置的值替换为NaN。
最后,函数返回处理后的张量x。'''
mask_offset_y = tf.random.uniform(())
mask_offset_x = tf.random.uniform(())
mask_size = tf.random.uniform((), *size)
mask_x = (mask_offset_x<x[...,0]) & (x[...,0] < mask_offset_x + mask_size)
mask_y = (mask_offset_y<x[...,1]) & (x[...,1] < mask_offset_y + mask_size)
mask = mask_x & mask_y
x = tf.where(mask[...,None], mask_value, x)
return x
def augment_fn(x, always=False, max_len=None):
'''这是一段Python代码,作用是对输入的坐标信息进行增强处理。
函数名为augment_fn,参数x为输入的坐标信息,always为是否总是进行增强处理的标志,
max_len为最大长度。首先使用tf.random.uniform函数生成一个随机数,
如果小于0.8或always为True,则使用resample函数对坐标信息进行重采样。
接着再次生成一个随机数,如果小于0.5或always为True,则使用flip_lr函数对坐标信息进行左右翻转。
如果max_len不为None,则使用temporal_crop函数对坐标信息进行时间裁剪。
再次生成一个随机数,如果小于0.75或always为True,则使用spatial_random_affine函数对坐标信息进行空间仿射变换。
接着再次生成一个随机数,如果小于0.5或always为True,则使用temporal_mask函数对坐标信息进行时间遮盖。
最后再次生成一个随机数,如果小于0.5或always为True,则使用spatial_mask函数对坐标信息进行空间遮盖。
最终返回增强处理后的坐标信息。'''
if tf.random.uniform(())<0.8 or always:
x = resample(x, (0.5,1.5))
if tf.random.uniform(())<0.5 or always:
x = flip_lr(x)
if max_len is not None:
x = temporal_crop(x, max_len)
if tf.random.uniform(())<0.75 or always:
x = spatial_random_affine(x)
if tf.random.uniform(())<0.5 or always:
x = temporal_mask(x)
if tf.random.uniform(())<0.5 or always:
x = spatial_mask(x)
return x
def get_tfrec_dataset(tfrecords, batch_size=64, max_len=64, drop_remainder=False, augment=False, shuffle=False, repeat=False):
# Initialize dataset with TFRecords
'''这段代码定义了一个函数,用于从TFRecords文件中读取数据集并进行预处理。
函数的参数包括TFRecords文件路径、批次大小、最大长度、是否丢弃剩余数据、是否进行数据增强、是否打乱数据、是否重复数据等。
函数首先使用TFRecordDataset初始化数据集,然后使用decode_tfrec函数解码数据,再使用preprocess函数进行预处理。
如果需要重复数据,则使用repeat函数,如果需要打乱数据,则使用shuffle函数,
并设置options.experimental_deterministic为False以确保每次打乱的结果不同。
最后,使用padded_batch函数将数据集分成批次,并使用prefetch函数提前加载数据以提高性能。函数返回处理后的数据集。'''
ds = tf.data.TFRecordDataset(tfrecords, num_parallel_reads=tf.data.AUTOTUNE, compression_type='GZIP')
ds = ds.map(decode_tfrec, tf.data.AUTOTUNE)
ds = ds.map(lambda x: preprocess(x, augment=augment, max_len=max_len), tf.data.AUTOTUNE)
if repeat:
ds = ds.repeat()
if shuffle:
ds = ds.shuffle(shuffle)
options = tf.data.Options()
options.experimental_deterministic = (False)
ds = ds.with_options(options)
if batch_size:
ds = ds.padded_batch(batch_size, padding_values=PAD, padded_shapes=([max_len,CHANNELS],[NUM_CLASSES]), drop_remainder=drop_remainder)
ds = ds.prefetch(tf.data.AUTOTUNE)
return ds
ds = get_tfrec_dataset(TRAIN_FILENAMES, augment=True, batch_size=1024)
'''这段代码的作用是从TRAIN_FILENAMES中获取TFRecord数据集,并进行数据增强,每个batch的大小为1024。
然后通过for循环遍历数据集,将第一个batch的数据赋值给temp_train。'''
for x in ds:
temp_train = x
break
这段代码主要是用于可视化人体姿态估计的结果。首先导入了IPython.display和matplotlib.animation模块。然后定义了一个函数filter_nans用于过滤掉帧中存在NaN值的部分。接着使用tf.data.TFRecordDataset读取数据集,并使用decode_tfrec函数对数据进行解码。然后通过循环遍历数据集,找到第一个包含左手的帧。接着定义了一个edges列表,用于表示人体骨架的连接关系。最后定义了两个函数plot_frame和animate_frames,用于绘制单个帧和多个帧的动画。其中plot_frame函数用于绘制单个帧,包括人体关键点的坐标和骨架的连接关系;animate_frames函数用于绘制多个帧的动画,使用matplotlib.animation模块中的FuncAnimation函数实现。
from IPython.display import HTML #要在Jupyter Notebook中打印HTML文本并以HTML格式显示,可以使用IPython.display模块中的HTML类
import matplotlib.animation as animation
from matplotlib.animation import FuncAnimation
def filter_nans(frames):
return frames[~np.isnan(frames).all(axis=(-2,-1))]
ds = tf.data.TFRecordDataset(TRAIN_FILENAMES, num_parallel_reads=tf.data.AUTOTUNE, compression_type='GZIP')
ds = ds.map(decode_tfrec, tf.data.AUTOTUNE)
print(ds)
for x in ds:
temp = x['coordinates'].numpy()
if not len(filter_nans(temp[:,LHAND])) == 0:
break
edges = [(0,1),(1,2),(2,3),(3,4),(0,5),(0,17),(5,6),(6,7),(7,8),(5,9),(9,10),(10,11),(11,12),
(9,13),(13,14),(14,15),(15,16),(13,17),(17,18),(18,19),(19,20)]
fig, ax = plt.subplots()
def plot_frame(frame, edges=[], idxs=[]):
frame[np.isnan(frame)] = 0
x = list(frame[...,0])
y = list(frame[...,1])
if len(idxs) == 0:
idxs = list(range(len(x)))
ax.clear()
ax.scatter(x, y, color='dodgerblue')
for i in range(len(x)):
ax.text(x[i], y[i], idxs[i])
for edge in edges:
ax.plot([x[edge[0]], x[edge[1]]], [y[edge[0]], y[edge[1]]], color='salmon')
ax.set_xticks([])
ax.set_yticks([])
ax.set_xticklabels([])
ax.set_yticklabels([])
def animate_frames(frames, edges=[], idxs=[]):
anim = FuncAnimation(fig, lambda frame: plot_frame(frame, edges, idxs), frames=frames, interval=100)
return HTML(anim.to_jshtml())
# Animate the frames
animate_frames(filter_nans(temp[:,LHAND]),edges=edges)
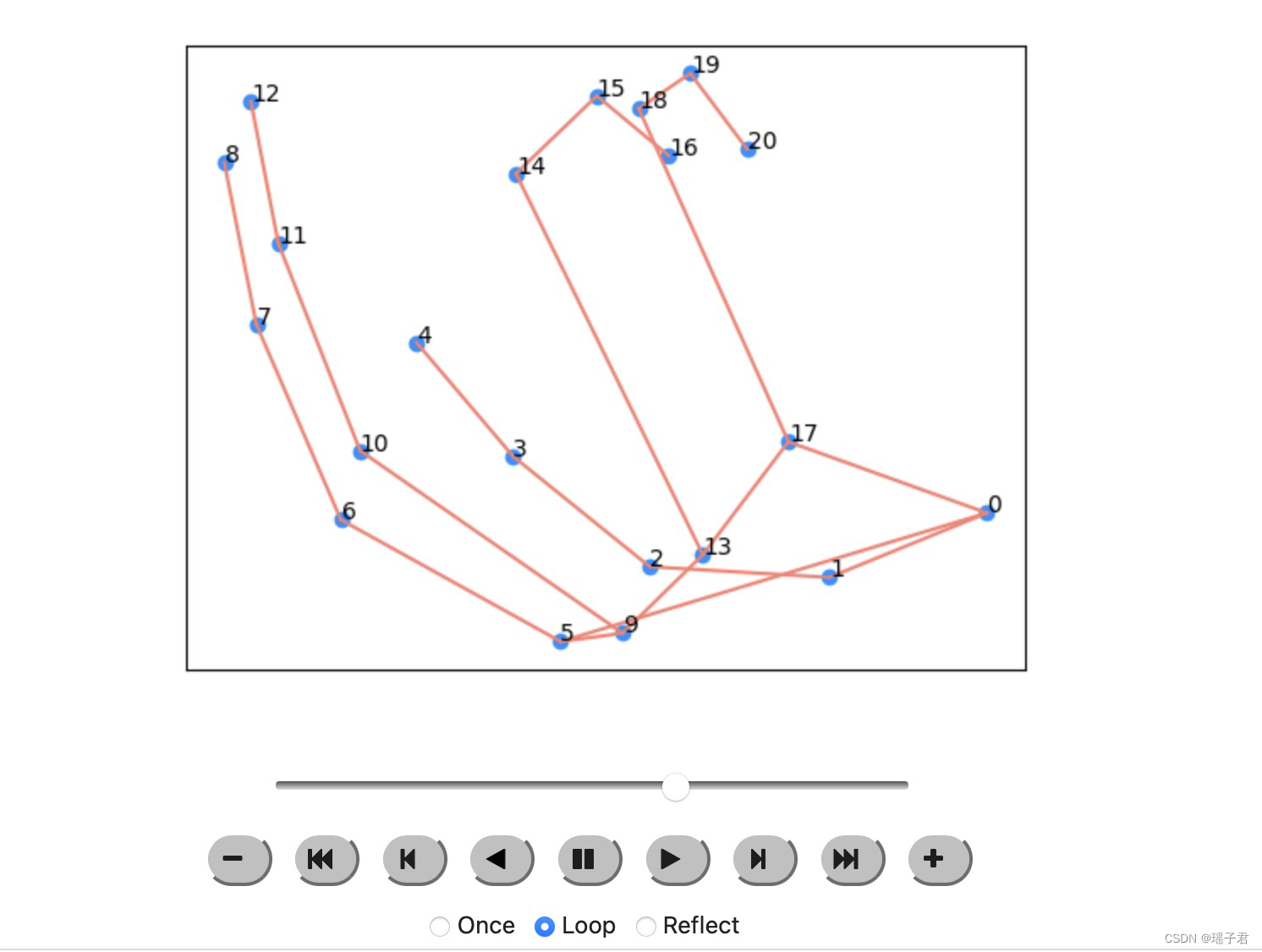
animate_frames(filter_nans(augment_fn(temp,always=True).numpy()[:,RHAND]),edges=edges)
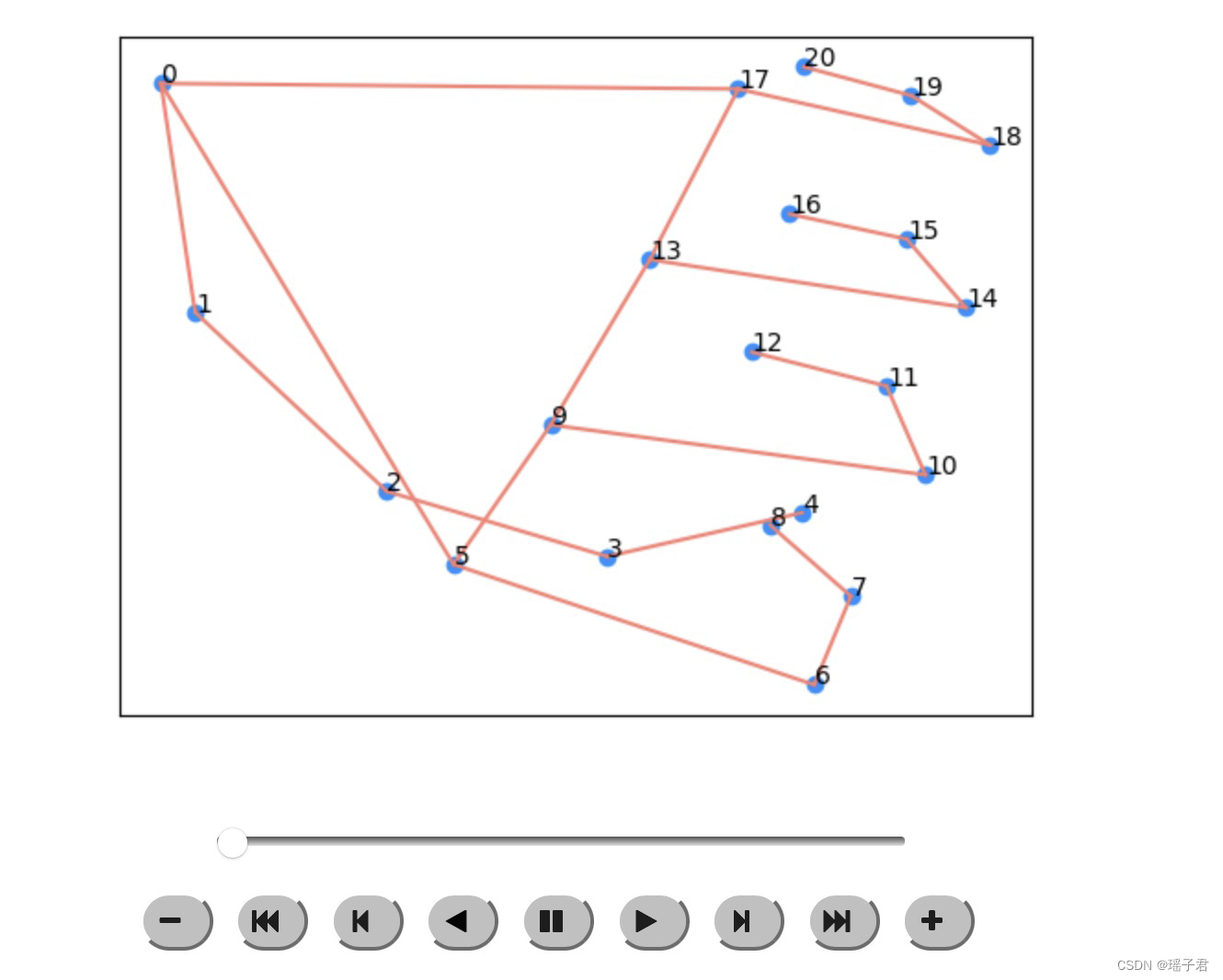
animate_frames(filter_nans(temp[:,POINT_LANDMARKS]))

animate_frames(filter_nans(augment_fn(temp,always=True).numpy()[:,POINT_LANDMARKS]), idxs=POINT_LANDMARKS)

这里给出了三个自定义的Keras层,分别是ECA、LateDropout和CausalDWConv1D。其中ECA是一种基于通道注意力机制的卷积神经网络层,用于增强模型的特征提取能力;LateDropout是一种在训练过程中逐渐增加dropout比例的dropout层,用于防止过拟合;CausalDWConv1D是一种因果卷积层,用于处理时间序列数据。同时,还给出了一个Conv1DBlock函数,用于构建一个高效的卷积块。这些层和函数的具体实现细节可以参考代码块中的注释。
class ECA(tf.keras.layers.Layer):
def __init__(self, kernel_size=5, **kwargs):
super().__init__(**kwargs)
self.supports_masking = True
self.kernel_size = kernel_size
#tf.keras.layers.Conv1D(1,1个过滤器
self.conv = tf.keras.layers.Conv1D(1, kernel_size=kernel_size, strides=1, padding="same", use_bias=False)
def call(self, inputs, mask=None):
nn = tf.keras.layers.GlobalAveragePooling1D()(inputs, mask=mask) #时间数据的全局平均池化操作
nn = tf.expand_dims(nn, -1)
nn = self.conv(nn)
nn = tf.squeeze(nn, -1)
nn = tf.nn.sigmoid(nn)
nn = nn[:,None,:] #增加维度
return inputs * nn
class LateDropout(tf.keras.layers.Layer):
def __init__(self, rate, noise_shape=None, start_step=0, **kwargs):
super().__init__(**kwargs)
self.supports_masking = True
self.rate = rate
self.start_step = start_ste0p
self.dropout = tf.keras.layers.Dropout(rate, noise_shape=noise_shape)
'''tf.keras.layers.Dropout()參數
rate 在 0 和 1 之間浮點數。要刪除的輸入單位的分數。
noise_shape 一維整數張量,表示將與輸入相乘的二進製 dropout 掩碼的形狀。例如,如果您的輸入具有 (batch_size, timesteps, features) 形狀,並且您希望所有時間步的 dropout 掩碼都相同,則可以使用 noise_shape=(batch_size, 1, features) 。
seed 用作隨機種子的 Python 整數。
Dropout 層在訓練期間的每一步以 rate 的頻率將輸入單元隨機設置為 0,這有助於防止過度擬合。未設置為 0 的輸入按 1/(1 - 比率) 放大,以使所有輸入的總和保持不變。
請注意,Dropout 層僅在 training 設置為 True 時適用,這樣在推理期間不會丟棄任何值。使用 model.fit , training 時會自動適當地設置為 True,在其他情況下,您可以在調用層時將 kwarg 顯式設置為 True。
(這與為 Dropout 層設置 trainable=False 形成對比。trainable 不會影響層的行為,因為 Dropout 沒有任何可以在訓練期間凍結的變量/權重。)'''
def build(self, input_shape):
super().build(input_shape)
agg = tf.VariableAggregation.ONLY_FIRST_REPLICA
self._train_counter = tf.Variable(0, dtype="int64", aggregation=agg, trainable=False)
def call(self, inputs, training=False):
x = tf.cond(self._train_counter < self.start_step, lambda:inputs, lambda:self.dropout(inputs, training=training))
if training:
self._train_counter.assign_add(1)
return x
class CausalDWConv1D(tf.keras.layers.Layer):
def __init__(self,
kernel_size=17,
dilation_rate=1,
use_bias=False,
depthwise_initializer='glorot_uniform',
name='', **kwargs):
super().__init__(name=name,**kwargs)
self.causal_pad = tf.keras.layers.ZeroPadding1D((dilation_rate*(kernel_size-1),0),name=name + '_pad')
#一維輸入的零填充層(例如時間序列)
#深度可分离卷积
self.dw_conv = tf.keras.layers.DepthwiseConv1D(
kernel_size,
strides=1,
dilation_rate=dilation_rate,
padding='valid',
use_bias=use_bias,
depthwise_initializer=depthwise_initializer,
name=name + '_dwconv')
self.supports_masking = True
def call(self, inputs):
x = self.causal_pad(inputs)
x = self.dw_conv(x)
return x
def Conv1DBlock(channel_size,
kernel_size,
dilation_rate=1,
drop_rate=0.0,
expand_ratio=2,
se_ratio=0.25,
activation='swish',
name=None):
'''
efficient conv1d block, @hoyso48
'''
if name is None:
name = str(tf.keras.backend.get_uid("mbblock"))
# Expansion phase
def apply(inputs):
channels_in = tf.keras.backend.int_shape(inputs)[-1]
channels_expand = channels_in * expand_ratio
skip = inputs
x = tf.keras.layers.Dense(
channels_expand,
use_bias=True,
activation=activation,
name=name + '_expand_conv')(inputs)
# Depthwise Convolution
x = CausalDWConv1D(kernel_size,
dilation_rate=dilation_rate,
use_bias=False,
name=name + '_dwconv')(x)
x = tf.keras.layers.BatchNormalization(momentum=0.95, name=name + '_bn')(x)
x = ECA()(x)
x = tf.keras.layers.Dense(
channel_size,
use_bias=True,
name=name + '_project_conv')(x)
if drop_rate > 0:
x = tf.keras.layers.Dropout(drop_rate, noise_shape=(None,1,1), name=name + '_drop')(x)
if (channels_in == channel_size):
x = tf.keras.layers.add([x, skip], name=name + '_add')
return x
return apply
这段代码定义了一个多头自注意力层(MultiHeadSelfAttention)和一个Transformer块(TransformerBlock)。
MultiHeadSelfAttention层的作用是对输入进行多头自注意力计算,其中dim表示每个头的维度,num_heads表示头的数量,dropout表示dropout的比例。在call方法中,首先通过一个全连接层(self.qkv)将输入映射到三个维度为dim的向量q、k、v,然后将这三个向量分别拆分成num_heads个头,进行多头自注意力计算,最后将计算结果通过一个全连接层(self.proj)映射回dim维度。
TransformerBlock块由两个子层组成,分别是多头自注意力层和前馈神经网络层。其中dim表示每个头的维度,num_heads表示头的数量,expand表示前馈神经网络层中间层的扩展倍数,attn_dropout表示多头自注意力层的dropout比例,drop_rate表示前馈神经网络层的dropout比例,activation表示前馈神经网络层的激活函数。在apply方法中,首先对输入进行批量归一化,然后通过多头自注意力层进行计算,再进行dropout和残差连接。接着再进行批量归一化,通过前馈神经网络层进行计算,再进行dropout和残差连接,最后返回计算结果。
class MultiHeadSelfAttention(tf.keras.layers.Layer):
def __init__(self, dim=256, num_heads=4, dropout=0, **kwargs):
super().__init__(**kwargs)
self.dim = dim
self.scale = self.dim ** -0.5
self.num_heads = num_heads
self.qkv = tf.keras.layers.Dense(3 * dim, use_bias=False)
self.drop1 = tf.keras.layers.Dropout(dropout)
self.proj = tf.keras.layers.Dense(dim, use_bias=False)
self.supports_masking = True
def call(self, inputs, mask=None):
qkv = self.qkv(inputs)
qkv = tf.keras.layers.Permute((2, 1, 3))(tf.keras.layers.Reshape((-1, self.num_heads, self.dim * 3 // self.num_heads))(qkv))
q, k, v = tf.split(qkv, [self.dim // self.num_heads] * 3, axis=-1)
attn = tf.matmul(q, k, transpose_b=True) * self.scale
if mask is not None:
mask = mask[:, None, None, :]
attn = tf.keras.layers.Softmax(axis=-1)(attn, mask=mask)
attn = self.drop1(attn)
x = attn @ v
x = tf.keras.layers.Reshape((-1, self.dim))(tf.keras.layers.Permute((2, 1, 3))(x))
x = self.proj(x)
return x
def TransformerBlock(dim=256, num_heads=4, expand=4, attn_dropout=0.2, drop_rate=0.2, activation='swish'):
def apply(inputs):
x = inputs
x = tf.keras.layers.BatchNormalization(momentum=0.95)(x)
x = MultiHeadSelfAttention(dim=dim,num_heads=num_heads,dropout=attn_dropout)(x)
x = tf.keras.layers.Dropout(drop_rate, noise_shape=(None,1,1))(x)
x = tf.keras.layers.Add()([inputs, x])
attn_out = x
x = tf.keras.layers.BatchNormalization(momentum=0.95)(x)
x = tf.keras.layers.Dense(dim*expand, use_bias=False, activation=activation)(x)
x = tf.keras.layers.Dense(dim, use_bias=False)(x)
x = tf.keras.layers.Dropout(drop_rate, noise_shape=(None,1,1))(x)
x = tf.keras.layers.Add()([attn_out, x])
return x
return apply
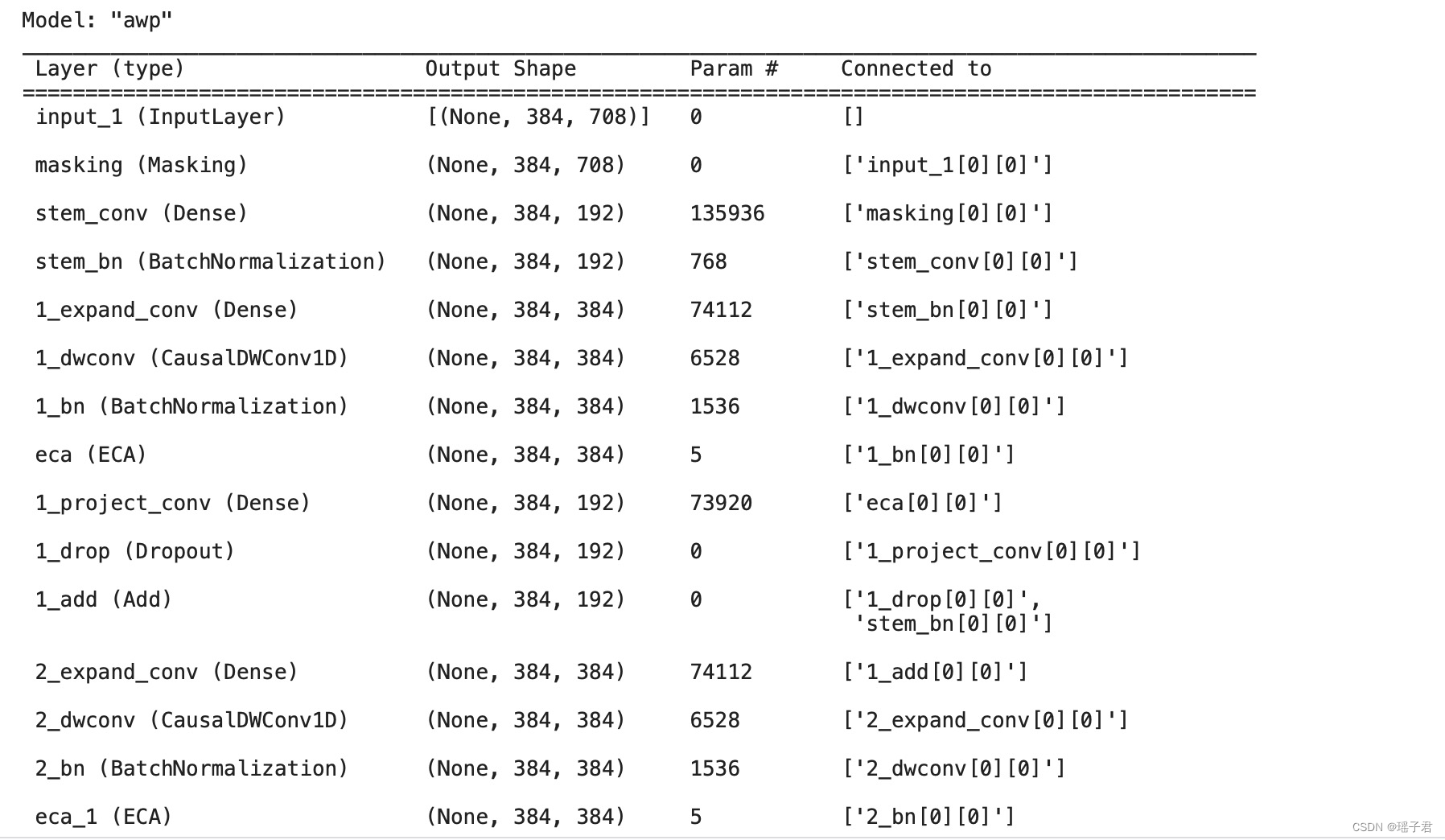
这段代码定义了一个函数get_model,用于构建一个神经网络模型。该模型包含了多个卷积层和Transformer层,以及一些其他的层,最终输出一个分类结果。具体来说,该模型的输入是一个形状为(max_len,CHANNELS)的张量,其中max_len表示输入序列的最大长度,CHANNELS表示每个时间步的特征维度。该张量首先经过一个Masking层,将输入序列中的PAD值进行mask,然后经过一个Dense层和BatchNormalization层,将输入序列的特征维度转换为dim。接下来,该张量经过多个Conv1DBlock层和TransformerBlock层的堆叠,用于提取输入序列的特征。最后,该张量经过一个全局平均池化层和一个LateDropout层,最终输出一个形状为(NUM_CLASSES,)的张量,表示输入序列的分类结果。在代码的最后,使用该模型对一个样本进行预测,并计算其损失值。
def get_model(max_len=64, dropout_step=0, dim=192):
inp = tf.keras.Input((max_len,CHANNELS))
x = tf.keras.layers.Masking(mask_value=PAD,input_shape=(max_len,CHANNELS))(inp)
ksize = 17
x = tf.keras.layers.Dense(dim, use_bias=False,name='stem_conv')(x)
x = tf.keras.layers.BatchNormalization(momentum=0.95,name='stem_bn')(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = TransformerBlock(dim,expand=2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = TransformerBlock(dim,expand=2)(x)
if dim == 384: #for the 4x sized model
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = TransformerBlock(dim,expand=2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = Conv1DBlock(dim,ksize,drop_rate=0.2)(x)
x = TransformerBlock(dim,expand=2)(x)
x = tf.keras.layers.Dense(dim*2,activation=None,name='top_conv')(x)
x = tf.keras.layers.GlobalAveragePooling1D()(x)
x = LateDropout(0.8, start_step=dropout_step)(x)
x = tf.keras.layers.Dense(NUM_CLASSES,name='classifier')(x)
return tf.keras.Model(inp, x)
model = get_model()
y = model(temp_train[0])
tf.keras.losses.CategoricalCrossentropy(from_logits=True)(temp_train[1],y)
这段代码是用来检查模型中的每一层是否支持掩码操作。对于每一层,如果不支持掩码操作,则打印出该层的名称和支持掩码操作的状态
#check supports_masking
for x in model.layers:
if not x.supports_masking:
print(x.supports_masking, x.name)
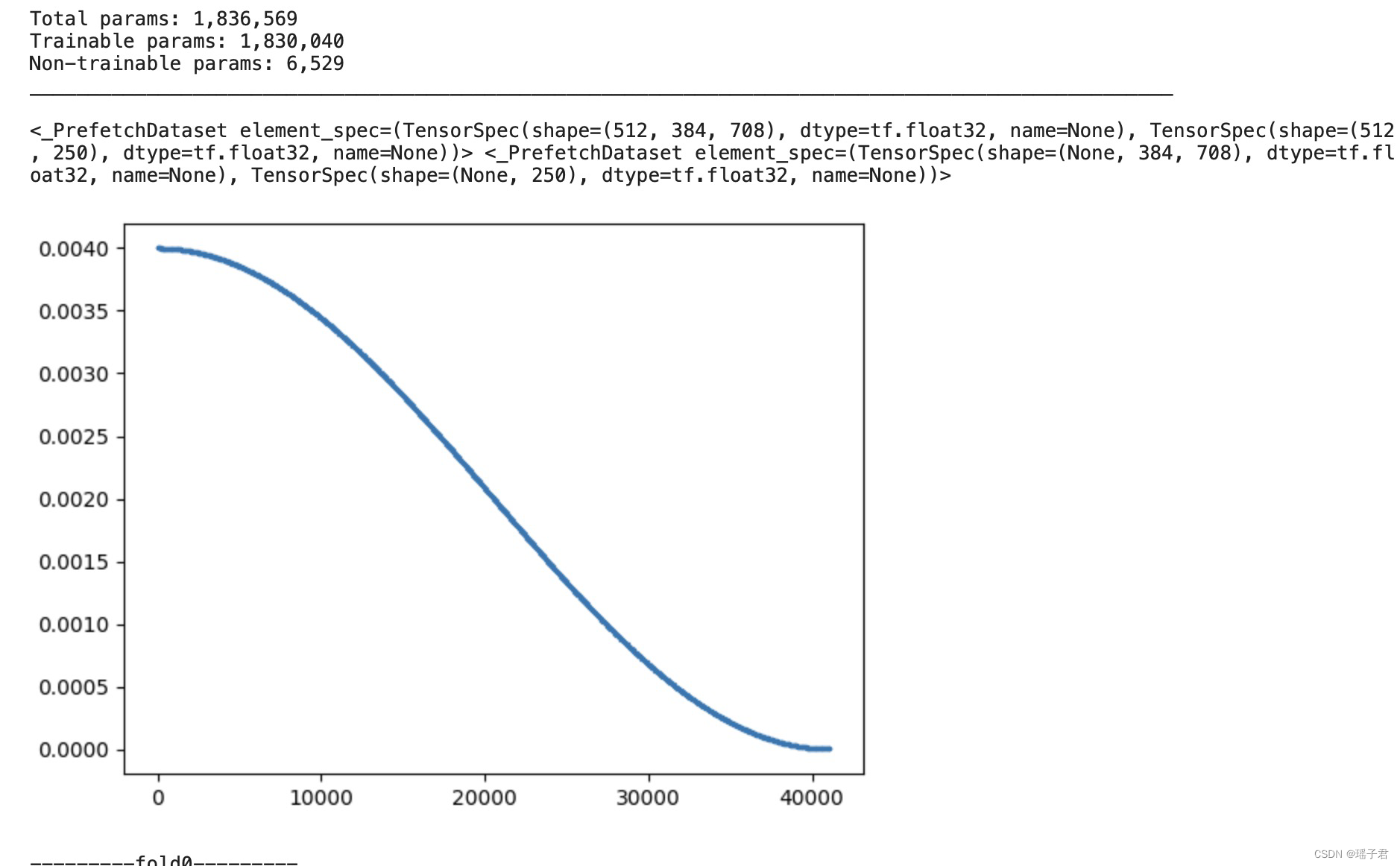
这段代码是一个用于训练模型的函数,其中包含了一些数据预处理、模型构建、优化器设置、回调函数等步骤。具体来说,该函数会根据传入的参数进行数据集的划分,然后使用给定的模型构建函数构建模型,并使用给定的优化器和回调函数进行模型训练。训练过程中还会进行一些其他的设置,如设置学习率、权重衰减、梯度累积等。最终,该函数会返回训练好的模型、交叉验证结果和训练历史记录。
def train_fold(CFG, fold, train_files, valid_files=None, strategy=STRATEGY, summary=True):
seed_everything(CFG.seed)
tf.keras.backend.clear_session()
gc.collect()
tf.config.optimizer.set_jit(True)
if CFG.fp16:
try:
policy = mixed_precision.Policy('mixed_bfloat16')
mixed_precision.set_global_policy(policy)
except:
policy = mixed_precision.Policy('mixed_float16')
mixed_precision.set_global_policy(policy)
else:
policy = mixed_precision.Policy('float32')
mixed_precision.set_global_policy(policy)
if fold != 'all':
train_ds = get_tfrec_dataset(train_files, batch_size=CFG.batch_size, max_len=CFG.max_len, drop_remainder=True, augment=True, repeat=True, shuffle=32768)
valid_ds = get_tfrec_dataset(valid_files, batch_size=CFG.batch_size, max_len=CFG.max_len, drop_remainder=False, repeat=False, shuffle=False)
else:
train_ds = get_tfrec_dataset(train_files, batch_size=CFG.batch_size, max_len=CFG.max_len, drop_remainder=False, augment=True, repeat=True, shuffle=32768)
valid_ds = None
valid_files = []
num_train = count_data_items(train_files)
num_valid = count_data_items(valid_files)
steps_per_epoch = num_train//CFG.batch_size
with strategy.scope():
dropout_step = CFG.dropout_start_epoch * steps_per_epoch
model = get_model(max_len=CFG.max_len, dropout_step=dropout_step, dim=CFG.dim)
schedule = OneCycleLR(CFG.lr, CFG.epoch, warmup_epochs=CFG.epoch*CFG.warmup, steps_per_epoch=steps_per_epoch, resume_epoch=CFG.resume, decay_epochs=CFG.epoch, lr_min=CFG.lr_min, decay_type=CFG.decay_type, warmup_type='linear')
decay_schedule = OneCycleLR(CFG.lr*CFG.weight_decay, CFG.epoch, warmup_epochs=CFG.epoch*CFG.warmup, steps_per_epoch=steps_per_epoch, resume_epoch=CFG.resume, decay_epochs=CFG.epoch, lr_min=CFG.lr_min*CFG.weight_decay, decay_type=CFG.decay_type, warmup_type='linear')
awp_step = CFG.awp_start_epoch * steps_per_epoch
if CFG.fgm:
model = FGM(model.input, model.output, delta=CFG.awp_lambda, eps=0., start_step=awp_step)
elif CFG.awp:
model = AWP(model.input, model.output, delta=CFG.awp_lambda, eps=0., start_step=awp_step)
opt = tfa.optimizers.RectifiedAdam(learning_rate=schedule, weight_decay=decay_schedule, sma_threshold=4)#, clipvalue=1.)
opt = tfa.optimizers.Lookahead(opt,sync_period=5)
model.compile(
optimizer=opt,
loss=[tf.keras.losses.CategoricalCrossentropy(from_logits=True, label_smoothing=0.1)], #[tf.keras.losses.CategoricalCrossentropy(from_logits=True)],
metrics=[
[
tf.keras.metrics.CategoricalAccuracy(),
],
],
steps_per_execution=steps_per_epoch,
)
if summary:
print()
model.summary()
print()
print(train_ds, valid_ds)
print()
schedule.plot()
print()
init=False
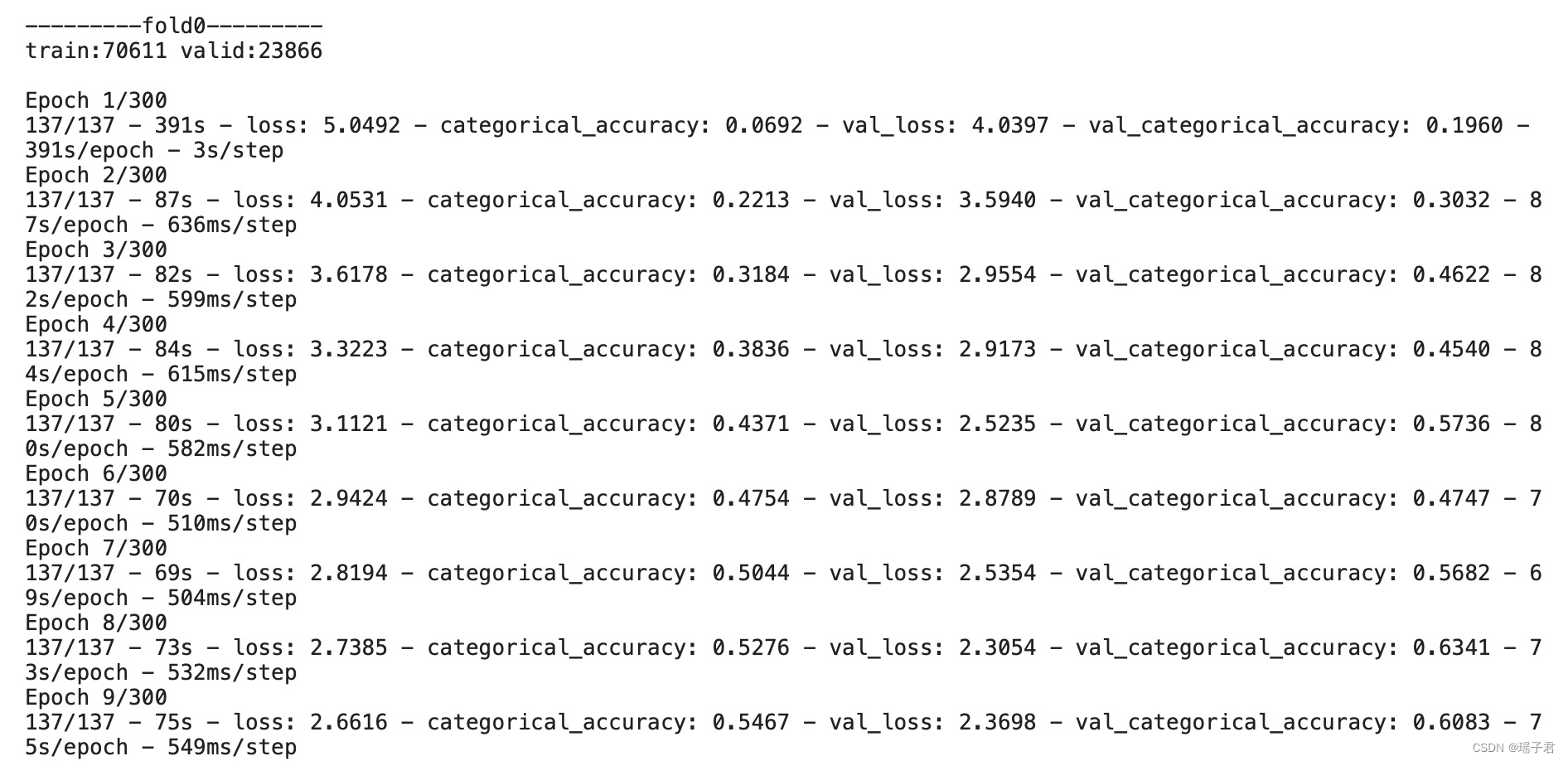
print(f'---------fold{fold}---------')
print(f'train:{num_train} valid:{num_valid}')
print()
if CFG.resume:
print(f'resume from epoch{CFG.resume}')
model.load_weights(f'{CFG.output_dir}/{CFG.comment}-fold{fold}-last.h5')
if train_ds is not None:
model.evaluate(train_ds.take(steps_per_epoch))
if valid_ds is not None:
model.evaluate(valid_ds)
logger = tf.keras.callbacks.CSVLogger(f'{CFG.output_dir}/{CFG.comment}-fold{fold}-logs.csv')
sv_loss = tf.keras.callbacks.ModelCheckpoint(f'{CFG.output_dir}/{CFG.comment}-fold{fold}-best.h5', monitor='val_loss', verbose=0, save_best_only=True,
save_weights_only=True, mode='min', save_freq='epoch')
snap = Snapshot(f'{CFG.output_dir}/{CFG.comment}-fold{fold}', CFG.snapshot_epochs)
swa = SWA(f'{CFG.output_dir}/{CFG.comment}-fold{fold}', CFG.swa_epochs, strategy=strategy, train_ds=train_ds, valid_ds=valid_ds, valid_steps=-(num_valid//-CFG.batch_size))
callbacks = []
if CFG.save_output:
callbacks.append(logger)
callbacks.append(snap)
callbacks.append(swa)
if fold != 'all':
callbacks.append(sv_loss)
history = model.fit(
train_ds,
epochs=CFG.epoch-CFG.resume,
steps_per_epoch=steps_per_epoch,
callbacks=callbacks,
validation_data=valid_ds,
verbose=CFG.verbose,
validation_steps=-(num_valid//-CFG.batch_size)
)
if CFG.save_output:
try:
model.load_weights(f'{CFG.output_dir}/{CFG.comment}-fold{fold}-best.h5')
except:
pass
if fold != 'all':
cv = model.evaluate(valid_ds,verbose=CFG.verbose,steps=-(num_valid//-CFG.batch_size))
else:
cv = None
return model, cv, history
def train_folds(CFG, folds, strategy=STRATEGY, summary=True):
for fold in folds:
if fold != 'all':
all_files = TRAIN_FILENAMES
train_files = [x for x in all_files if f'fold{fold}' not in x]
valid_files = [x for x in all_files if f'fold{fold}' in x]
else:
train_files = TRAIN_FILENAMES
valid_files = None
train_fold(CFG, fold, train_files, valid_files, strategy=strategy, summary=summary)
return
这段代码定义了一个名为CFG的类,其中包含了一些超参数和配置信息,用于训练一个模型。其中包括数据集划分数、是否保存输出、输出目录、随机种子、最大长度、学习率、权重衰减、训练轮数、批量大小等等。此外,还包括了一些特殊的训练技巧,如混合精度训练、对抗训练、自适应权重裁剪等。这些超参数和技巧的具体含义需要根据具体的模型和任务来理解
class CFG:
n_splits = 5
save_output = True
output_dir = '/kaggle/working'
seed = 42
verbose = 2 #0) silent 1) progress bar 2) one line per epoch
max_len = 384
replicas = 8
lr = 5e-4 * replicas
weight_decay = 0.1
lr_min = 1e-6
epoch = 300 #400
warmup = 0
batch_size = 64 * replicas
snapshot_epochs = []
swa_epochs = [] #list(range(epoch//2,epoch+1))
fp16 = True
fgm = False
awp = True
awp_lambda = 0.2
awp_start_epoch = 15
dropout_start_epoch = 15
resume = 0
decay_type = 'cosine'
dim = 192
comment = f'islr-fp16-192-8-seed{seed}'
train_folds(CFG, [0])















 2458
2458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









