






收集网上的答案,以及自己错的随便编写的博文,如有雷同万分抱歉,
1. Some of the problems below are best addressed using a supervised learning algorithm, and the others with an unsupervised learning algorithm. Which of the following would you apply supervised learning to? (Select all that apply.) In each case,assume some appropriate dataset is available for your algorithm to learn from.
A. Given historical data of childrens' ages and heights, predict children's height as a function of their age.
B. Examine a large collection of emails that are known to be spam email, to discover if there are sub-types of spam mail.
C. Examine the statistics of two football teams, and predicting which team will win tomorrow's match (given historical data of teams' wins/losses to learn from).
D. Given a large dataset of medical records from patients suffering from heart disease, try to learn whether there might be different clusters of such patients for which we might tailor separate treatements.
答案【A,C】
【解析】This is a supervised learning, regression problem, where we can learn from a training set to predict height.
【解析】This can addressed using a clustering (unsupervised learning) algorithm, to cluster spam mail into sub-types.
【解析】This can be addressed using supervised learning, in which we learn from historical records to make win/loss predictions.
【解析】This can be addressed using an unsupervised learning, clustering, algorithm, in which we group patients into different clusters.
2. Suppose that for some linear regression problem (say, predicting housing prices as in the lecture), we have some training set, and for our training set we managed to find some θ0, θ1 such that J(θ0,θ1)=0. Which of the statements below must then
be true?
A. For these values of θ0 and θ1 that satisfy J(θ0,θ1)=0, we have that hθ(x(i))=y(i) for every training example (x(i),y(i))
B. For this to be true, we must have y(i)=0 for every value of i=1,2,…,m.
C. Gradient descent is likely to get stuck at a local minimum and fail to find the global minimum.
D.We can perfectly predict the value of y even for new examples that we have not yet seen. (e.g., we can perfectly predict prices of even new houses that we have not yet seen.)
答案【A】
【解析】J(θ0,θ1)=0, that means the line defined by the equation "y=θ0+θ1x" perfectly fits all of our data.
【解析】So long as all of our training examples lie on a straight line, we will be able to find θ0 and θ1 so that J(θ0,θ1)=0. It is not necessary that y(i)=0 for all of our examples.
【解析】The cost function J(θ0,θ1) for linear regression has no local optima (other than the global minimum), so gradient descent will not get stuck at a bad local minimum.
【解析】Even though we can fit our training set perfectly, this does not mean that we'll always make perfect predictions on houses in the future/on houses that we have not yet seen.
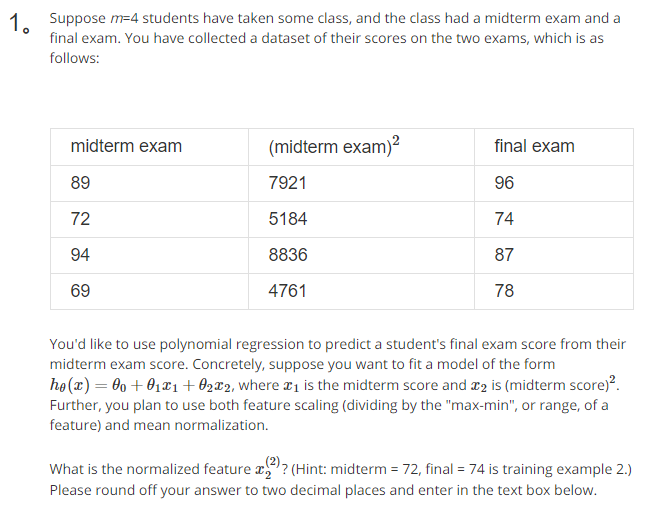
平均值: (7921+5184+8836+4761)/4=6675.5
特征值范围Max-Min=8836-4761=4075
归一化后(5184-6675.5)/4075=-0.3660 结果为-0.37

X为m行n+1列 y为m行1列 θ为n+1行
5.Which of the following are reasons for using feature scaling?
[A] It speeds up gradient descent by making it require fewer iterations to get to a good solution.
[B] It speeds up solving for θ using the normal equation.
[C] It is necessary to prevent gradient descent from getting stuck in local optima.
[D] It prevents the matrix XTX (used in the normal equation) from being non-invertable (singular/degenerate).
A.迭代次数的减少,加快了正确答案的得出。B.正规方程对计算只与训练集的大小有关,而与θ无关,
C.不能阻止梯度下降局部最优。D.除非可以减少特征变量,否则不能解决此问题
所以选A
6
A C = X + 1;
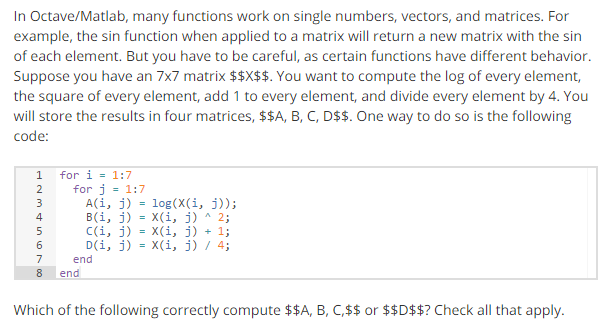
B D = X / 4;
C B = X .^ 2;
D B = X ^ 2;
答案为ABC
7
Suppose that you have trained a logistic regression classifier, and it outputs on a new
example x a prediction hθ(x) = 0.4. This means (check all that apply):
A Our estimate for P(y=1|x;θ) is 0.6.
B Our estimate for P(y=1|x;θ) is 0.4.
C Our estimate for P(y=0|x;θ) is 0.6.
D Our estimate for P(y=0|x;θ) is 0.4.
答案为BC
hθ(x) = P(y=1|x;θ) = 1-P(y=0|x;θ)P(y=1|x;θ
8

答案为ACD
B 是由于使用代价函数为线性回归代价函数,会有很多局部最优值,使用其他优化算法的原因是因为不予要学习率,比梯度下降更快。
9、You are training a classification model with logistic regression. Which of the following statements are true? Check all that apply.
A. Introducing regularization to the model always results in equal or better performance on the training set.
B .Adding many new features to the model helps prevent overfitting on the training set.
C. Adding a new feature to the model always results in equal or better performance on examples not in the training set.
D .Adding a new feature to the model always results in equal or better performance on the training set.
答案【D】
【A】If we introduce too much regularization, we can underfit the training set and have worse performance on the training set.
【B】Adding many new features gives us more expressive models which are able to better fit our training set. If too many new features are added, this can lead to overfitting of the training set.
【C】Adding more features might result in a model that overfits the training set, and thus can lead to worse performs for examples which are not in the training set.
【D】By adding a new feature, our model must be more (or just as) expressive, thus allowing it learn more complex hypotheses to fit the training set.

A 选项中XOR(异或)需要多层叠加
C logical function有四种操作:AND OR XOR NOT. 其中两层的Network可以表示出AND OR NOT这三类,三层Network可以表示出XOR.
11、Suppose you are working on a spam classifier, where spam emails are positive examples (y = 1) and non-spam emails are negative examples (y = 0). You have a training set of emails in which 99% of the emails are non-spam and the other 1% is spam. Which of the following statements are true? Check all that apply.
A、If you always predict non-spam (output y=0), your classifier will have 99% accuracy on the trainingset, but it will do much worse on the cross validation set because it has overfit the training data.
B、A good classifier should have both a high precision and high recall on the cross validation set.
C、If you always predict non-spam (output y=0), your classifier will have 99% accuracy on the training set, and it will likely perform similarly on the cross validation set.
D、If you always predict non-spam (output y=0), your classifier will have an accuracy of 99%

答案:BCD
y = 0,a=0,b=1,c=0,d=99,
y = 1,a=1,b=0,c=99,d=0
解析:A 当y = 0时,其准确度为99%,在交叉验证集上做的更糟,但不是过度训练数据
12、 Which of the following statements are true? Check all that apply.
A、The"error analysis" process of manually examining the examples whichyour algorithm got wrong can help suggest what are good steps to take (e.g., developing new features) to improve your algorithm's performance.
B、Itis a good idea to spend a lot of time collecting a large amount of data before building your first version of a
learning algorithm.
C、If your model is underfitting the training set, then obtaining more data is likely to help.
D、After training a logistic regression classifier, you must use 0.5 as your threshold for predicting whether an example is positive or negative.
E、Using a very large training set makes it unlikely for model to overfit the training data.
答案:ACE
解析:B 需要的是大量有用的数据,而不是大量数据
C 已经说了不适合训练集的模型,获取更多数据没有用
12、
答案:BD
解析:A 可线性分离的数据集通常可以被许多不同的行分开。 改变参数将导致SVM的决策边界在这些可能性之间变化。 例如,对于一个非常大的值,它可能会学习更大的值以增加某些示例的边际值。
13 Which of the following statements are true? Select all that apply.
A、Since K-Means is an unsupervised learning algorithm, it cannot overfit the data, and thus it is always better to
have as large a number of clusters as is computationally feasible.
B、If we are worried about K-means getting stuck in bad local optima, one way to ameliorate (reduce) this problem is
if we try using multiple random initializations.-
C、For some datasets, the “right” or “correct” value of K (the number of clusters) can be ambiguous, and hard
even for a human expert looking carefully at the data to decide.
D、The standard way of initializing K-means is setting μ1=⋯=μk to be equal to a vector of zeros.
答案BC















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









