







第一次用JAVA进行爬虫,参考了很多大佬的博客,然后自己觉得JSOUP比较好理解,就用JSOUP解析搞了个小项目
jsoup中文文档参考:https://www.open-open.com/jsoup/selector-syntax.htm
后续将会再此项目中继续加入翻页爬取、连接数据库、存入数据库等功能,到时再更新。
目录
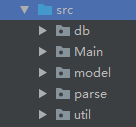
Db
存放连接数据库的代码(暂时还没开始弄,等后续再更新)
Main
程序执行的入口
Model
存放数据的属性的代码
Parse
存放解析网页的代码
Util
存放各种工具类代码
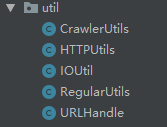
Crawler
爬虫工具类
HTTP
响应客户端工具类
IO
文件输入输出工具类类
Regular
正则表达式工具类
URL
超链接处理工具类
在此次的JAVA爬虫中,我只使用了HTTP和URL两个工具类
Jar包
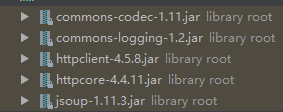
这些包都可以通过搜索下载
好,废话不多说,上代码,代码注释里讲得很清楚
Main
package Main;
import model.myMovie;
import org.apache.http.ParseException;
import org.apache.http.client.HttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import util.URLHandle;
import java.io.IOException;
import java.util.List;
public class myMovieMain {
public static void main(String[] args) {
System.out.println("正在生成客户端...");
HttpClient client = HttpClientBuilder.create().build();
System.out.println("客户端生成完毕.");
String url = "https://maoyan.com/board/4";
List<myMovie> movieList = null;
//开始解析
try {
System.out.println("开始响应客户端...");
movieList = URLHandle.urlParser(client, url);
System.out.println("响应完成.");
} catch (ParseException e) {
e. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









