







方法一:start_requests方法中添加cookies与headers:
1、重写spider中的start_requests方法
浏览器中cookies是这样的
Cookie:_T_WM=98075578786; WEIBOCN_WM=3349; H5_wentry=H5; backURL=https%3A%2F%2Fm.weibo.cn%2Fdetail%2F4396824548695177; ALF=1568417075; SCF=Ap5VqXy_BfNHBEUteiYtYDRa04jqF4QPJBULzWo7c1c_noO0GpnJW3BqhIkH7JXJSwWhL0qSg69_Vici5P7NbmY.; SUB=_2A25wUOt6DeRhGeFM41AT9y3LyDSIHXVTuvUyrDV6PUJbktANLVXzkW1NQL_2tT4ZmobAs5b6HbIQwSRXHjjiRkzj; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFWyDsTszIBJPBJ6gn7ccSM5JpX5K-hUgL.FoME1hzES0eNe0n2dJLoI0YLxK-L1K.L1KMLxK-L1KzLBoeLxK-L12BLBK2LxK-LBK-LB.BLxK-LBK-LB.BLxKnLB-qLBoBLxKnLB-qLBoBt; SUHB=0S7CWHWuRz1aWf; SSOLoginState=1565825835需要转换为字典格式
转换代码:
def transform(self,cookies):
cookie_dict = {}
cookies = cookies.replace(' ','')
list = cookies.split(';')
for i in list:
keys = i.split('=')[0]
values = i.split('=')[1]
cookie_dict[keys] = values
return cookie_dict在start_request中新增
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
cookies = {'_T_WM': '98075578786', 'WEIBOCN_WM': '3349', 'H5_wentry': 'H5', 'backURL': 'https%3A%2F%2Fm.weibo.cn%2Fdetail%2F4396824548695177', 'ALF': '1568417075', 'SCF': 'Ap5VqXy_BfNHBEUteiYtYDRa04jqF4QPJBULzWo7c1c_noO0GpnJW3BqhIkH7JXJSwWhL0qSg69_Vici5P7NbmY.', 'SUB': '_2A25wUOt6DeRhGeFM41AT9y3LyDSIHXVTuvUyrDV6PUJbktANLVXzkW1NQL_2tT4ZmobAs5b6HbIQwSRXHjjiRkzj', 'SUBP': '0033WrSXqPxfM725Ws9jqgMF55529P9D9WFWyDsTszIBJPBJ6gn7ccSM5JpX5K-hUgL.FoME1hzES0eNe0n2dJLoI0YLxK-L1K.L1KMLxK-L1KzLBoeLxK-L12BLBK2LxK-LBK-LB.BLxK-LBK-LB.BLxKnLB-qLBoBLxKnLB-qLBoBt', 'SUHB': '0S7CWHWuRz1aWf', 'SSOLoginState': '1565825835'}2、修改方法返回值
yield scrapy.Request(url=url, headers=headers, cookies=cookies, callback=self.parse)样例:
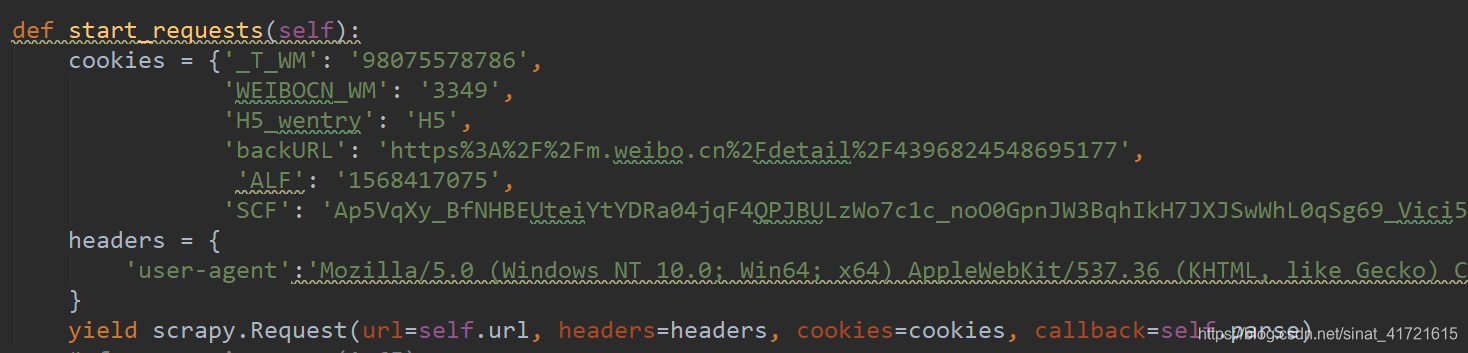
3、修改COOKIES_ENABLED
- 当COOKIES_ENABLED是注释的时候scrapy默认没有开启cookie
- 当COOKIES_ENABLED没有注释设置为False的时候scrapy默认使用了settings里面的cookie
- 当COOKIES_ENABLED设置为True的时候scrapy就会把settings的cookie关掉,使用自定义cookie
所以需要在settings.py文件中设置COOKIES_ENABLED = True
并且在settings.py文件中设置ROBOTSTXT_OBEY = False #不遵守robotstxt协议
方法二:在setting.py文件中添加cookies与headers --- 最简单的方法
- settings文件中给Cookies_enabled=False和DEFAULT_REQUEST_HEADERS解注释
- 在settings的DEFAULT_REQUEST_HEADERS配置的cookie就可以使用了
推荐使用这种方法,因为可以用shell进行调试
样例:

方法三:激活DownloadMiddleware(下载器中间件)
- settings.py中给DOWNLOADER_MIDDLEWARES解注释
- 去中间件文件中找DownloaderMiddleware这个类,修改process_request,添加request.cookies={}
参考链接:https://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/downloader-middleware.html

















 4823
4823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









