







一、引言
前文回顾:
【Python时序预测系列】基于Holt-Winters方法实现单变量时间序列预测(源码)
【Python时序预测系列】基于ARIMA法实现单变量时间序列预测(源码)
【Python时序预测系列】基于SARIMA实现单变量时间序列预测(源码)
LSTM(Long Short-Term Memory,长短期记忆)是一种常用的循环神经网络(Recurrent Neural Network,RNN)架构,用于处理和建模时间序列数据。相比于传统的RNN,LSTM具有更强的记忆能力和长期依赖建模能力,能够有效地处理长序列和解决梯度消失/爆炸的问题。
LSTM的核心思想是引入了称为"门"的结构,以控制信息的流动和记忆的保留。LSTM单元由一个输入门(input gate)、一个遗忘门(forget gate)和一个输出门(output gate)组成,每个门都有一个可学习的权重参数。这些门决定了输入数据的处理方式,以及过去记忆的保留和遗忘。
在LSTM中,输入门控制新输入数据的加入,遗忘门控制过去记忆的遗忘,输出门控制输出的生成。通过这些门的调节,LSTM可以选择性地记住或忘记过去的信息,并将当前输入和过去的记忆相结合,产生新的输出。这种机制使得LSTM能够有效地处理长期依赖关系,从而在许多任务中取得了很好的效果,如语言建模、机器翻译、语音识别等。
本文以"国际航空乘客"数据集为例,使用LSTM进行单变量单步预测。
二、实现过程
导入相关的库
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
from statsmodels.tsa.holtwinters import ExponentialSmoothing
import matplotlib.pyplot as plt2.1 读取数据集
# 读取数据集
data = pd.read_csv('international-airline-passengers.csv')
# 将日期列转换为日期时间类型
data['Month'] = pd.to_datetime(data['Month'])
# 将日期列设置为索引
data.set_index('Month', inplace=True)data:
2.2 划分数据集
# 拆分数据集为训练集和测试集
train_size = int(len(data) * 0.8)
train_data = data[:train_size]
test_data = data[train_size:]
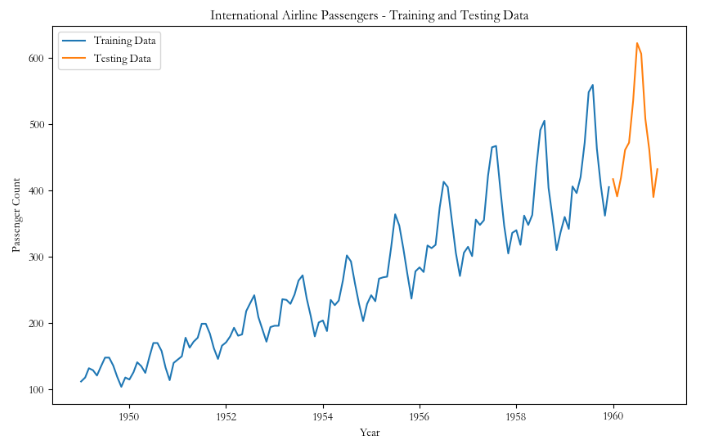
# 绘制训练集和测试集的折线图
plt.figure(figsize=(10, 6))
plt.plot(train_data, label='Training Data')
plt.plot(test_data, label='Testing Data')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Training and Testing Data')
plt.legend()
plt.show()共144条数据,8:2划分:训练集115,测试集29。
训练集和测试集:
2.3 归一化
# 将数据归一化到 0~1 范围
scaler = MinMaxScaler()
train_data_scaler = scaler.fit_transform(train_data.values.reshape(-1, 1))
test_data_scaler = scaler.transform(test_data.values.reshape(-1, 1))2.4 构造数据集
# 定义滑动窗口函数
def create_sliding_windows(data, window_size):
X, Y = [], []
for i in range(len(data) - window_size):
X.append(data[i:i+window_size])
Y.append(data[i+window_size])
return np.array(X), np.array(Y)
# 定义滑动窗口大小
window_size = 12
# 创建滑动窗口数据集
X_train, Y_train = create_sliding_windows(train_data_scaler, window_size)
X_test, Y_test = create_sliding_windows(test_data_scaler, window_size)
# 将数据集转换为 LSTM 模型所需的形状(样本数,时间步长,特征数)
X_train = np.reshape(X_train, (X_train.shape[0], window_size, 1))
X_test = np.reshape(X_test, (X_test.shape[0], window_size, 1)滑动窗口12
训练集:
【1-12】【13】
【2-13】【14】
...
【102-113】【114】
【103-114】【115】
X_train:(103,12,1)
Y_train:(103,1)
经过滑动窗口构造的数据集,新的训练集数据数量(103)比原始训练集(115)少一个滑动窗口数量(12)
因此,实际训练值只有103条,是训练的13-115的部分。
测试集:
【116-127】【128】
【117-128】【129】
...
【131-142】【143】
【132-143】【144】
X_test:(17,12,1)
Y_test:(17,1)
经过滑动窗口构造的数据集,新的测试集数据数量(17)比原始训测试集(29)少一个滑动窗口数量(12)
因此,实际预测值只有17个,是预测的128-144的部分,如果想预测116-128的部分,可以取训练集的最后12个数进行预测。
2.5 建立模拟合模型进行预测
# 构建 LSTM 模型
model = Sequential()
model.add(LSTM(50, activation='relu', input_shape=(window_size, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
# 训练 LSTM 模型
model.fit(X_train, Y_train, epochs=100, batch_size=32)
# 使用 LSTM 模型进行预测
train_predictions = model.predict(X_train)
test_predictions = model.predict(X_test)
# 反归一化预测结果
train_predictions = scaler.inverse_transform(train_predictions)
test_predictions = scaler.inverse_transform(test_predictions)predictions:
2.6 预测效果展示
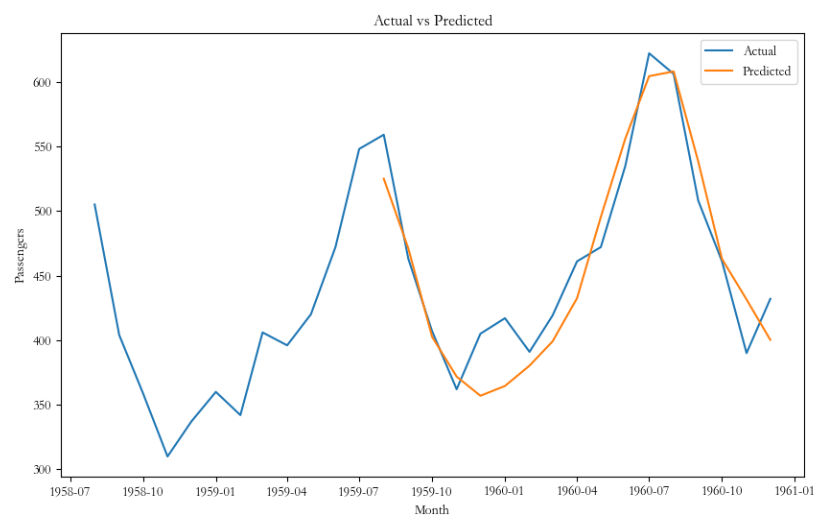
# 绘制测试集预测结果的折线图
plt.figure(figsize=(10, 6))
plt.plot(test_data, label='Actual')
plt.plot(list(test_data.index)[-17:], test_predictions, label='Predicted')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.title('Actual vs Predicted')
plt.legend()
plt.show()测试集真实值与预测值:
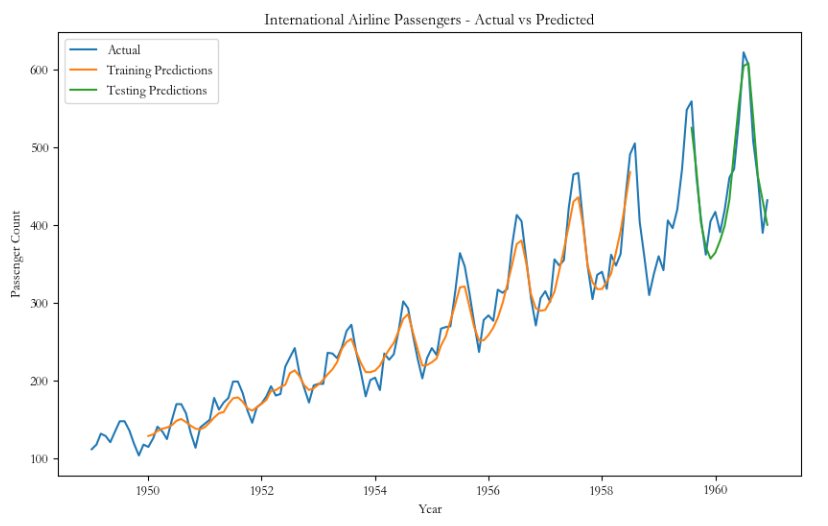
# 绘制原始数据、训练集预测结果和测试集预测结果的折线图
plt.figure(figsize=(10, 6))
plt.plot(data, label='Actual')
plt.plot(list(train_data.index)[window_size:train_size], train_predictions, label='Training Predictions')
plt.plot(list(test_data.index)[-(len(test_data)-window_size):], test_predictions, label='Testing Predictions')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Actual vs Predicted')
plt.legend()
plt.show()原始数据、训练集预测结果和测试集预测结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











