







决策树构建(二)
决策树构建(二)
前边我们学习了比特化,信息熵,条件熵,纯度等知识信息熵的计算公式是什么?条件熵的两个计算公式是什么?信息熵的高低和系统混乱程度的关系是什么?
- 高信息熵——>系统均匀分布——>不确定性高——>确定性低——>系统越混乱
- 低信息熵——>大概率+小概率(不均匀分布)——>不确定性低——>确定性高——>系统越有序
- 纯度:进行分割后,子集里的标签,类别足够的纯,越少越好,尽可能的有一种标签、类别(最纯)
决策树量化纯度
决策树的构建是基于样本概率和纯度进行构建操作的,那么进行判断数据集是否“纯”可以通过三个公式进行判断,分别是Gini系数、嫡(Entropy)、错误率,这三个公式值越大,表示数据越“不纯”;越小表示越“纯”;实践证明这三种公式效果差不多,一般情况使用嫡公式
三个公式如下:
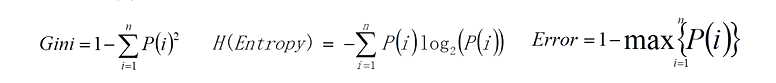
分析:
1、嫡(Entropy)
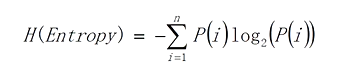
如果划分之后:
子集足够纯——>自己里更多的是同一类型——>有序的系统——低信息熵
那么我们现在要用熵表示这个数据的不纯度,则:
- 信息熵越高——>不纯度越高——越不纯
- 信息熵越低——>不纯度越低——越纯
我们想要信息熵越低,所以P越不趋向于平均越好。
2、Gini系数
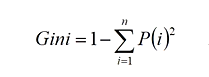
- Gini越大——>越不纯
- Gini越小——>越纯
我们想要纯度越高,则我们期望Gini越小越好,然后有公式:
Gini = 1 -(所有取值的概率的平方和)
所有事件概率和 = 1
根据公式,当后面的∑越大——>Gini越小
那什么时候∑最大呢?(a+b=1,a = b时,a2 + b2 最小)
P(i)都相等的时候——>∑最小——>1-∑最大Gini最大——>最不纯
我们想要Gini越小越好,所以P越不趋向于平均越好。
3、错误率
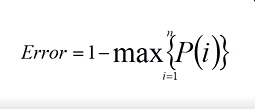
Error = 1-概率最大的一个
- Error越大——>越不纯
- Error越小——>越纯
所有事件概率和 = 1
假设有P1,P2,和为1 Error最大时,即P1 = P2,这个时候Error = 0.5,当P1,P2,不相等时,必然有一个是大于0.5的,那么1减这个值就会小于0.5。
我们想要Error越小越好,所以P越不趋向于平均越好。
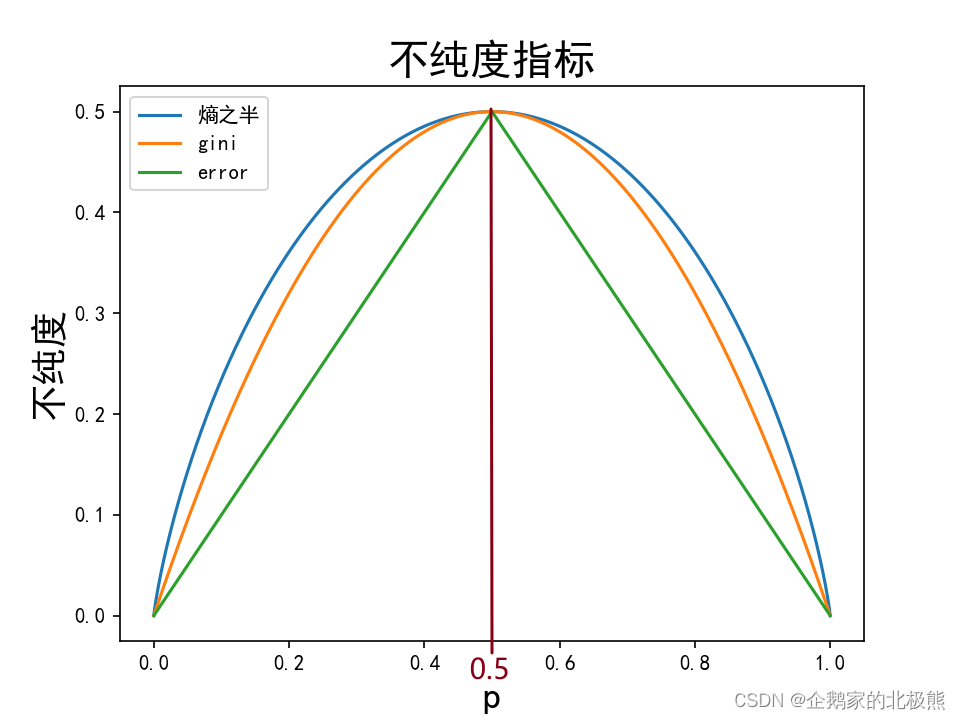
可以用代码直观的看一下这三个值与数据不纯度的关系
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
## 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
##信息熵
def entropy(p):
return np.sum([-i * np.log2(i) for i in p if i != 0])
##信息熵
def H(p):
return entropy(p)
##基尼系数
def gini(p):
return 1 - np.sum([i * i for i in p])
##错误率
def error(p):
return 1 - np.max(p)
# # 不纯度
P0 = np.linspace(0.0, 1.0, 1000) # 这个表示在0到1之间生成1000个p值(另外的就是1-p)
P1 = 1 - P0
y1 = [H([p0, 1 - p0]) * 0.5 for p0 in P0] ##熵之半
y2 = [gini([p0, 1 - p0]) for p0 in P0]
y3 = [error([p0, 1 - p0]) for p0 in P0]
plt.plot(P0, y1, label=u'熵之半')
plt.plot(P0, y2, label=u'gini')
plt.plot(P0, y3, label=u'error')
plt.legend(loc='upper left')
plt.xlabel(u'p', fontsize=18)
plt.ylabel(u'不纯度', fontsize=18)
plt.title(u'不纯度指标', fontsize=20)
plt.show() # 绘制图像
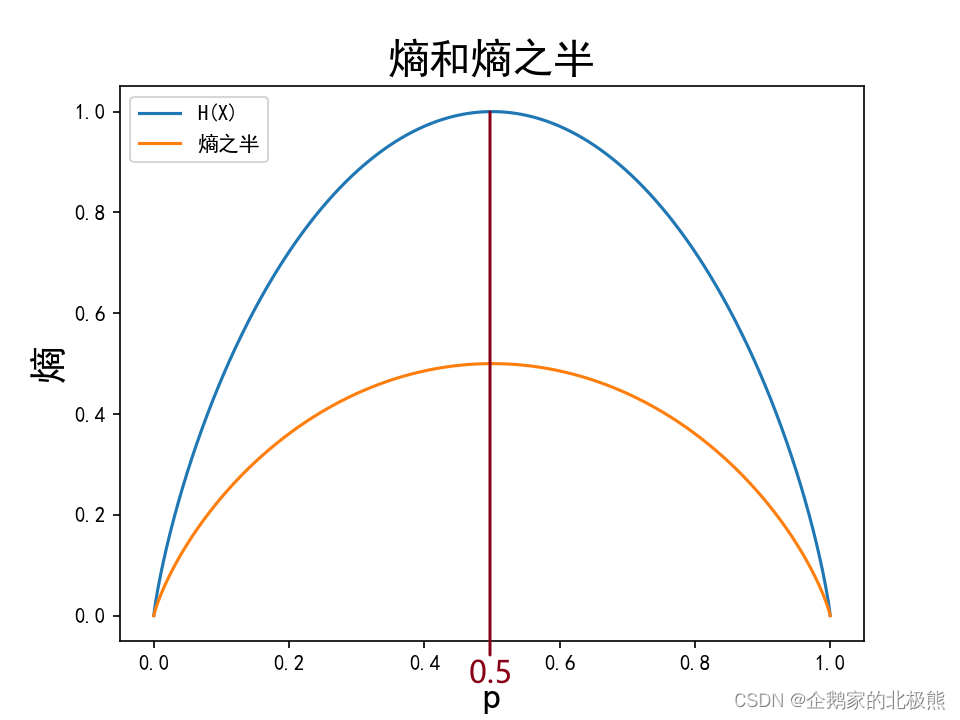
# # 熵和熵之半
y = [H([p0, 1 - p0]) for p0 in P0]
y1 = [H([p0, 1 - p0]) * 0.5 for p0 in P0]
plt.plot(P0, y, label=u'H(X)')
plt.plot(P0, y1, label=u'熵之半')
plt.legend(loc='upper left')
plt.xlabel(u'p', fontsize=18)
plt.ylabel(u'熵', fontsize=18)
plt.title(u'熵和熵之半', fontsize=20)
plt.show() # 绘制图像
输出:
可以发现,都是在P(i) = 0.5的时候三个评估指点最大且效果上是一样的
如果在上边的代码中信息熵不乘0.5得到的结果是一样的。
信息增益度
计算出各个属性的量化纯度以后,就要进行选择,选择出当前数据集的分割特征属性,我们用信息增益度进行选择。
计算公式:
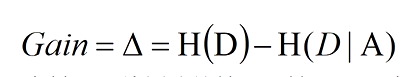
- D为目标属性,A为某一划分的特征属性:Gain为A为特征对训练数据D的信息增益(集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差)
重点来了:
- 如果信息增益度的值越大——>以该特征进行分裂后的条件熵越小——>分割后的信息熵越低——>越纯——>在该特征属性上损失的纯度越大(如果用该属性进行分裂会变得更纯)——>用该属性进行分裂,该属性应该在决策树的上层。
举例:
加入现在有一批数据,进行如下分割
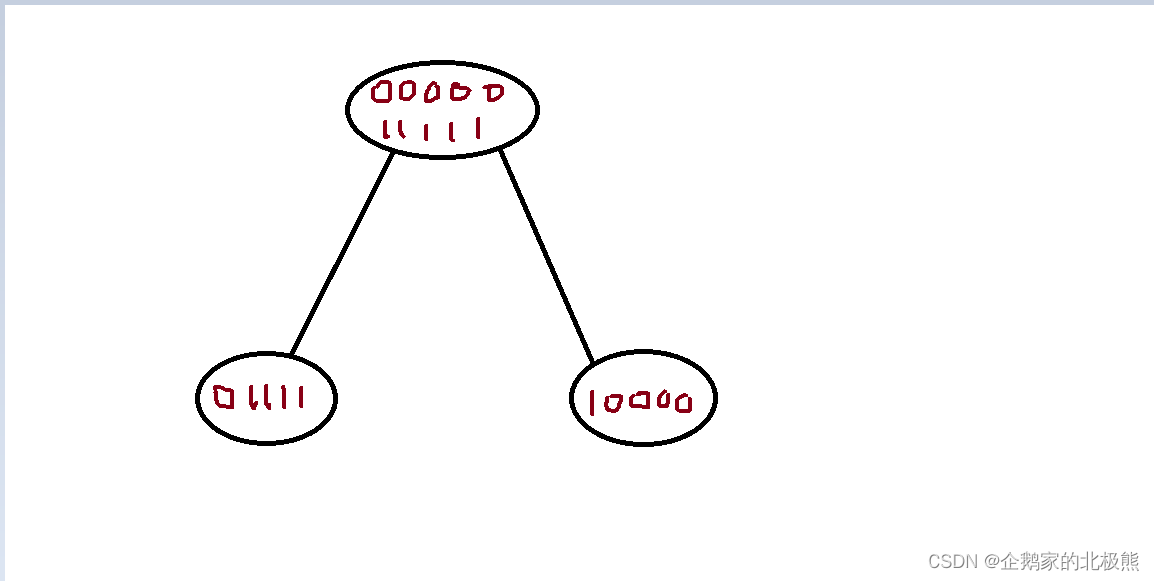
分割之前的信息熵:
H(D) = 1
分割之后的条件熵:
H(D|A) = 左边的信息熵 + 右边的信息熵 = 0.50.72 + 0.50.72 = 0.72
Gain = H(D) - H(D|A) = 0.28
重点又来了:
- 前边我们用信息熵这个参数来衡量系统的不纯度,信息熵越大,越不纯,现在,用某个特征进行分割以后,信息熵变小了,有一定的损失,那是不是就说明:不纯度有一定的降低,损失的数量就是Gain,不纯度有了一定的降低,是不是纯度有了一定的增加,那我们当然是希望这个损失越大越好啊。用哪个特征进行分割可以使得分割后的Gain更大就用哪个特征进行分割呗,把他放在最上层不就完了。
决策树算法的停止条件
决策树构建的过程是一个递归的过程,所以必须给定停止条件,否则过程将不会停止。
一般有以下两种停止条件:
- 1、当每个节点只有一种类型时停止构建
这个方式很容易导致过拟合
这个时候意味着此时的信息熵为0,已经足够纯了。是一个确定事件,那还分个啥! - 2、当前节点的样本数小于某个阈值,同时迭代次数达到给定值时,停止构建过程,此时用max(p(i))作为节点的对应类型(多数投票法)
比如说当前节点中的样本数为10个,我们就不继续划分了,哪怕这10个样本中有8个0,2个1,也不再划分,因为我要求了样本数小于10 不在划分,或者说划分了我规定的划分100次停止划分,因为如果我不做限制,无限次的划分,划分到最后,一定会达到第一种条件:每一个叶子节点只有一类别。
注意:
按照方式1进行迭代,会使数的节点过多,导致过拟合等问题。
比较常用的是方式二作为停止条件
决策树算法效果评估
- 决策树的效果评估和一般的分类算法一样,采用混淆矩阵来进行计算准确率、召回率、精确率等指标
- 也可以用叶子结点的不纯度值的综合来评估算法效果,值越小,效果越好,因为我们肯定希望不纯度越小越好,计算公式如下:

其中:
t = 1-leaf : 每一个叶子结点
H(t) = 信息熵
Dt :叶子节点中的样本数量
D : 原来总的样本数量
|Dt | / D:叶子里数据出现的概率,实际上就是各个叶子节点的条件熵。
所以在构建决策树的时候,我们常认为损失函数就是:
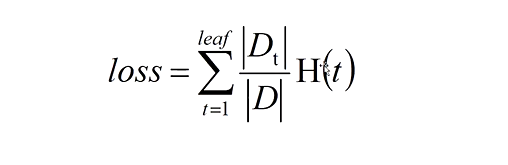
所有叶子节点的条件熵的综合,我们希望每一层划分后,这个函数越小越好,这个值越小,算法越好
实际上构建决策树的这个过程,就是在降低这个损失。就是在优化算法。
知道了这些知识我们就可以开始着手构建一颗决策树了















 1562
1562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











