







本题来自左神《程序员代码面试指南》“找到二叉树中的最大搜索二叉子树”题目。
题目
给定一棵二叉树的头节点 head,已知其中所有节点的值都不一样,找到含有节点最多的搜索二叉子树,并返回这棵子树的头节点。
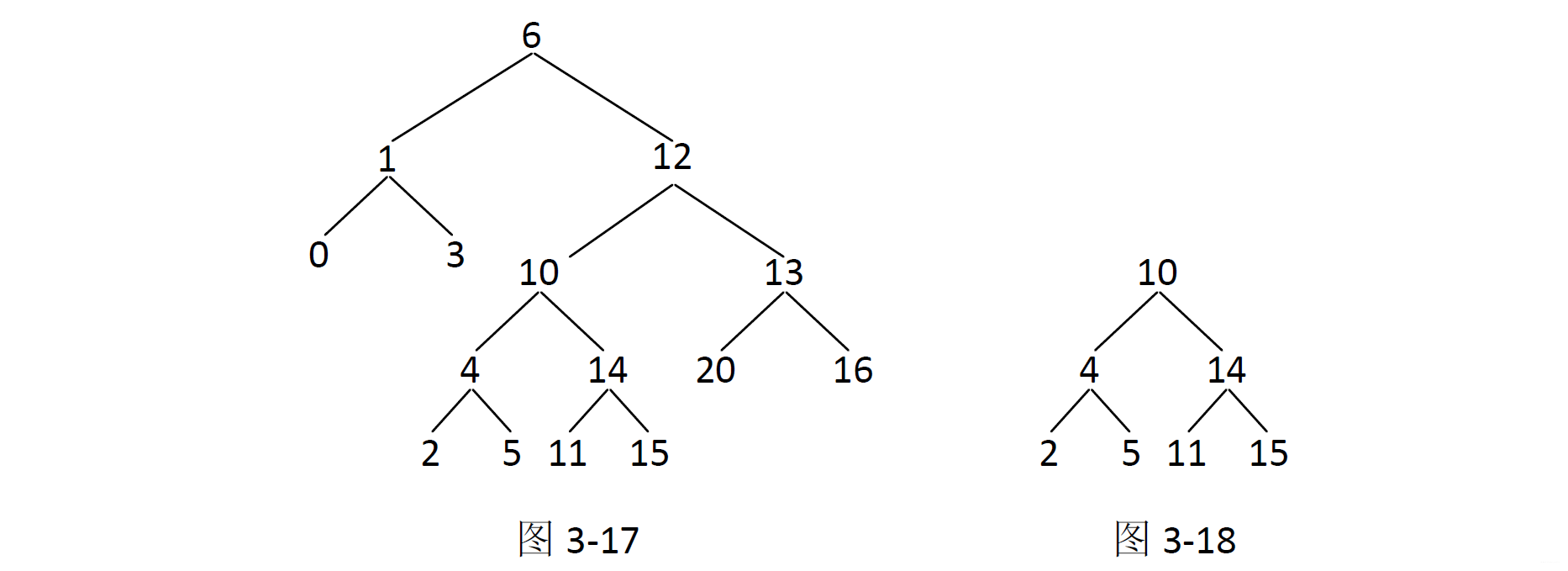
例如,二叉树如图 3-17 所示。
这棵树中的最大搜索二叉子树如图 3-18 所示。
要求:如果节点数为 N,则要求时间复杂度为 O(N),额外空间复杂度为 O(h),其中,h 为二叉树的高度。
题解
本题涉及二叉树面试题中一个很常见的套路,也是全书的一个重要内容。利用分析可能性求解在二叉树上做类似动态规划的问题。请读者理解并学习这种套路,本章还有很多面试题目是用这个套路求解的,我们把这个套路的名字叫作 树形 dp 套路。
树形dp 套路使用前提:如果题目求解目标是S 规则,则求解流程可以定成以每一个节点为头节点的子树在S 规则下的每一个答案,并且最终答案一定在其中。
如何理解这个前提呢?以本题为例,题目求解目标是:整棵二叉树中的最大搜索二叉子树,这就是我们的规则。那么求解流程可不可以定成:在整棵二叉树中,求出每一个节点为头节点的子树的最大搜索二叉子树(对任何一棵子树都求出答案),并且最终答案(整棵二叉树的最大搜索二叉子树)一定在其中?当然可以。因此,本题可以使用套路。
树形dp 套路第一步:
以某个节点X 为头节点的子树中,分析答案有哪些可能性,并且这种分析是以X 的左子树、X 的右子树和X 整棵树的角度来考虑可能性的。
用本题举例。以节点X 为头节点的子树中,最大的搜索二叉子树只可能是以下三种情况中可能性最大的那种。
- 第一种:X 为头节点的子树中,最大的搜索二叉子树就是X 的左子树中的最大搜索二叉子树。也就是说,答案可能来自左子树。比如,本例中,当X 为节点12 时。
- 第二种:X 为头节点的子树中,最大的搜索二叉子树就是X 的右子树中的最大搜索二叉子树。也就是说,答案可能来自右子树。比如,本例中,当X 为节点6 时。
- 第三种:如果X 左子树上的最大搜索二叉子树是X 左子树的全体,X 右子树上的最大搜索二叉子树是X 右子树的全体,并且X 的值大于X 左子树所有节点的最大值,但小于X 右子树所有节点的最小值,那么X 为头节点的子树中,最大的搜索二叉子树就是以X 为头节点的全体。
也就是说,答案可能是用X 连起所有。比如,本例中,当X 为节点10 时。
树形dp 套路第二步:
根据第一步的可能性分析,列出所有需要的信息。
用本题举例,为了分析第一、二种可能性,需要分别知道左子树和右子树上的最大搜索二叉子树的头部,记为leftMaxBSTHead、rightMaxBSTHead,因为要比较大小,所以还需要分别知道左子树和右子树上的最大搜索二叉子树的大小,记为leftBSTSize、rightBSTSize,并且有了这些信息还能帮助分析第三种可能性,因为如果知道了leftMaxBSTHead,并且发现它正好是X 的左孩子节点,则说明X左子树上的最大搜索二叉子树是X 左子树的全体。同理,可以利用rightMaxBSTHead 来判断X右子树上的最大搜索二叉子树是否为X 右子树的全体。但是有这些还不够,因为第三种可能性还要求X 的值大于X 左子树所有节点的最大值,但小于X 右子树所有节点的最小值。因此,需要从左子树上取得左子树的最大值leftMax,从右子树上取得右子树的最小值rightMin。
汇总一下,为了分析所有的可能性,左树上需要的信息为:leftMaxBSTHead、leftBSTSize、leftMax;右树上需要的信息为:rightMaxBSTHead、rightBSTSize、rightMin。
树形dp 套路第三步:
合并第二步的信息,对左树和右树提出同样的要求,并写出信息结构。
以本题举例,左树和右树都需要最大搜索二叉子树的头节点及其大小这两个信息,但是左树只需要最大值,右树只需要最小值,那么合并变成统一要求。信息结构请看如下的ReturnType 类。
树形 dp 套路第四步:
设计递归函数,递归函数是处理以X 为头节点的情况下的答案,包括设计递归的base case,默认直接得到左树和右树的所有信息,以及把可能性做整合,并且要返回第三步的信息结构这四个小步骤。本题的实现请看如下的process 方法。
package chapter_3_binarytreeproblem;
public class Problem_07_BiggestSubBSTInTree {
public static class Node {
public int value;
public Node left;
public Node right;
public Node(int data) {
this.value = data;
}
}
/**
* 主方法:找到二叉树中的最大搜索二叉子树
*/
public static Node getMaxBST(Node head) {
return process(head).maxBSTHead;
}
public static class ReturnType {
public Node maxBSTHead; // 最大搜索二叉子树头结点
public int maxBSTSize; // 最大搜索二叉子树大小
public int min; // 右树只需最小值
public int max; // 左树只需最大值
public ReturnType(Node maxBSTHead, int maxBSTSize, int min, int max) {
this.maxBSTHead = maxBSTHead;
this.maxBSTSize = maxBSTSize;
this.min = min;
this.max = max;
}
}
/**
* 用递归函数设计一个二叉树后序遍历的过程:
* 先遍历左子树收集信息,然后是右子树收集信息,最后在头结点做信息整合
*/
public static ReturnType process(Node X) {
// base case : 如果子树是空树
// 最小值为系统最大
// 最大值为系统最小
if (X == null) {
return new ReturnType(null, 0, Integer.MAX_VALUE, Integer.MIN_VALUE);
}
// 默认直接得到左树全部信息
ReturnType lData = process(X.left);
// 默认直接得到右树全部信息
ReturnType rData = process(X.right);
// 【以下过程为信息整合】
// 同时以X为头的子树也做同样的要求,也需要返回如ReturnType描述的全部信息
// 以X为头的子树的最小值是:左树最小、右树最小、X的值,三者中最小的
int min = Math.min(X.value, Math.min(lData.min, rData.min));
// 以X为头的子树的最大值是:左树最大、右树最大、X的值,三者中最大的
int max = Math.max(X.value, Math.max(lData.max, rData.max));
// 如果只考虑可能性一和可能性二,以X为头的子树的“最大搜索二叉树大小”
int maxBSTSize = Math.max(lData.maxBSTSize, rData.maxBSTSize);
// 如果只考虑可能性一和可能性二,以X为头的子树的“最大搜索二叉树头节点”
Node maxBSTHead = lData.maxBSTSize >= rData.maxBSTSize ? lData.maxBSTHead : rData.maxBSTHead;
// 利用收集的信息,可以判断是否存在可能性三
if (lData.maxBSTHead == X.left && rData.maxBSTHead == X.right && X.value > lData.max && X.value < rData.min) {
maxBSTSize = lData.maxBSTSize + rData.maxBSTSize + 1;
maxBSTHead = X;
}
// 【信息全部搞定】返回
return new ReturnType(maxBSTHead, maxBSTSize, min, max);
}
// for test -- print tree
public static void printTree(Node head) {
System.out.println("Binary Tree:");
printInOrder(head, 0, "H", 17);
System.out.println();
}
public static void printInOrder(Node head, int height, String to, int len) {
if (head == null) {
return;
}
printInOrder(head.right, height + 1, "v", len);
String val = to + head.value + to;
int lenM = val.length();
int lenL = (len - lenM) / 2;
int lenR = len - lenM - lenL;
val = getSpace(lenL) + val + getSpace(lenR);
System.out.println(getSpace(height * len) + val);
printInOrder(head.left, height + 1, "^", len);
}
public static String getSpace(int num) {
String space = " ";
StringBuffer buf = new StringBuffer("");
for (int i = 0; i < num; i++) {
buf.append(space);
}
return buf.toString();
}
public static void main(String[] args) {
Node head = new Node(6);
head.left = new Node(1);
head.left.left = new Node(0);
head.left.right = new Node(3);
head.right = new Node(12);
head.right.left = new Node(10);
head.right.left.left = new Node(4);
head.right.left.left.left = new Node(2);
head.right.left.left.right = new Node(5);
head.right.left.right = new Node(14);
head.right.left.right.left = new Node(11);
head.right.left.right.right = new Node(15);
head.right.right = new Node(13);
head.right.right.left = new Node(20);
head.right.right.right = new Node(16);
printTree(head);
Node bst = getMaxBST(head);
printTree(bst);
}
}
树形 dp 套路就是以上四个步骤,就是利用递归函数设计一个二叉树后序遍历的过程:先遍历左子树收集信息,然后是右子树收集信息,最后在头节点做信息整合。因为是递归函数,所以对所有的子树要求一样,都返回ReturnType 的实例。依次求出每棵子树的答案,总答案一定在其中。既然是后序遍历,则时间复杂度为O(N)。














 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









