







MapReduce基本概念
- MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
Mapreduce相关术语
- 作业(Job):用户的每一个计算请求,就称为一个作业。
- 作业服务器(JobTracker):用户提交作业的服务器,同时,它还负责各个作业任务的分配,管理所有的任务服务器。
- 任务服务器(TaskTracker):负责执行具体的任务。 备份任务(Speculative
Task):每一个任务,都有可能执行失败或者缓慢,为了降低为此付出的代价,系统会在另外的任务服务器上执行同样一个任务,这就是备份任务。
Mapreduce版本
经典的MapReduce(MapReduce 1)
- 客户端(client):编写mapreduce程序,配置作业,提交作业,这就是程序员完成的工作;
- JobTracker:初始化作业,分配作业,与TaskTracker通信,协调整个作业的执行;
- TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行Map或Reduce任务,TaskTracker和JobTracker的不同有个很重要的方面,就是在执行任务时候TaskTracker可以有n多个,JobTracker则只会有一个(JobTracker只能有一个就和hdfs里namenode一样存在单点故障)
- Hdfs:保存作业的数据、配置信息等等,最后的结果也是保存在hdfs上面
升级后的MapReduce-YARN(MapReduce2)
- 提交Mapreduce作业的客户端
- YARN资源管理器,负载协调集群上计算资源的分配
- YARN节点管理器,负责启动和监视集群中机器上的计算容器
- MapReduce应用程序master负责协调运行MapReduce作业任务,它和MapReduce任务在容器中运行,这些容器有资源管理器分配并由节点管理器进行管理
- Hdfs,用来与其他实体间共享作业文件。
Mapreduce运行机制
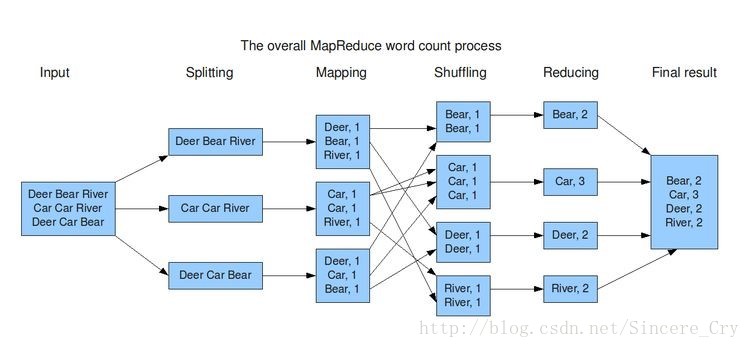
输入分片(input split):将输入数据分成等长的小数据块,每个输入分片建立一个map任务,输入分片存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组。分片的大小影响因素为两个:
1.负载平衡,拥有较多的分片(处理分片所需时间少于处理整个输入数据的时间),能够使得整个处理过程获得更好的负载平衡,由于不同计算机的运行速率不同,分片大小越细则负载平衡越好。 2.时间管理,由于分片切分太小,使得管理分片时间和构建map任务的时间决定整个时间。即分片时间更趋向于一个块的大小,由于这样可以确保存储在单个节点上的最大输入块大小,若分片跨越两个数据块则在执行一个map函数时会占用hdfs中数据的传输,使得效率效率较低map阶段:分片后的的数据执行之前写好的map函数,因此map函数效率相对好控制,而且一般map操作都是本地化操作也就是在数据存储节点上进行;map函数将其输出到本地硬盘,而非HDFS由于map的输出结果为中间结果,一旦作业完成即其输出结果就可以删除,若其中map结果传送至reduce失败,将会重新运行map任务再次构建map中间结果。
combiner阶段:combiner其实也是一种reduce操作,Combiner是一个本地化的reduce操作,它是map运算的后续操作,主要是在map计算出中间文件前做一个简单的合并重复key值的操作,目的为降低map和reduce任务之间传输资源的占用率。但使用原则是combiner的输入不会影响到reduce计算的最终输入,例如:做平均值计算使用combiner的话,最终的reduce计算结果就会出错。
shuffle阶段:将map的输出作为reduce的输入的过程,这个是mapreduce优化的重点地方。shuffle阶段的原理为:一开始就是map阶段做输出操作,一般mapreduce计算的都是海量数据,map输出时候不是把所有文件都放到内存操作,因此map写入磁盘的过程以及后面的进行排序,内存开销是很大的,map在做输出时候会在内存里开启一个环形内存缓冲区,这个缓冲区专门用来输出的,默认大小是100mb,并且在配置文件里为这个缓冲区设定了一个阀值,默认是0.80,同时map还会为输出操作启动一个守护线程,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把内容写到磁盘上,这个过程叫spill,另外的20%内存可以继续写入要写进磁盘的数据,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作,前面我讲到写入磁盘前会有个排序操作,这个是在写入磁盘操作时候进行,不是在写入内存时候进行的,如果我们定义了combiner函数,那么排序前还会执行combiner操作。
reduce阶段:和map函数一样也是程序员编写的,最终结果是存储在hdfs上的。














 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









