






声明:此文章只是随笔记录,仅供学习研究,切勿用于非法途径!!!!!!!如有侵权联系删除。
目标站:aHR0cHM6Ly9jaWZlcnF1ZXJ5LnNpbmdsZXdpbmRvdy5jbi8=
复盘一下昨晚扣的网站。

 通过抓包分析,headers和cookies中并没有什么加密参数,最后在返回的数据中有加密,所以我们只通过翻页来进行调试
通过抓包分析,headers和cookies中并没有什么加密参数,最后在返回的数据中有加密,所以我们只通过翻页来进行调试
打开F12,有一个无限debugger,通过右键绕过直接卡死,我们选择用hook的方式绕过。
Function.prototype.constructor_=Function.prototype.constructor;
Function.prototype.constructor=function(x){
if(x!=="debugger"){
return Function.prototype.constructor(x)
}
}
打上XHR断点进行单步调试。没跟几步就会找到他的入口

开始抠代码, 缺什么补什么就好了

扣到这里的时候 会发现从浏览器控制台copy出来的 与实际打印的一比,缺少好多方法,先不管,留着 一会看看 万一用不到呢
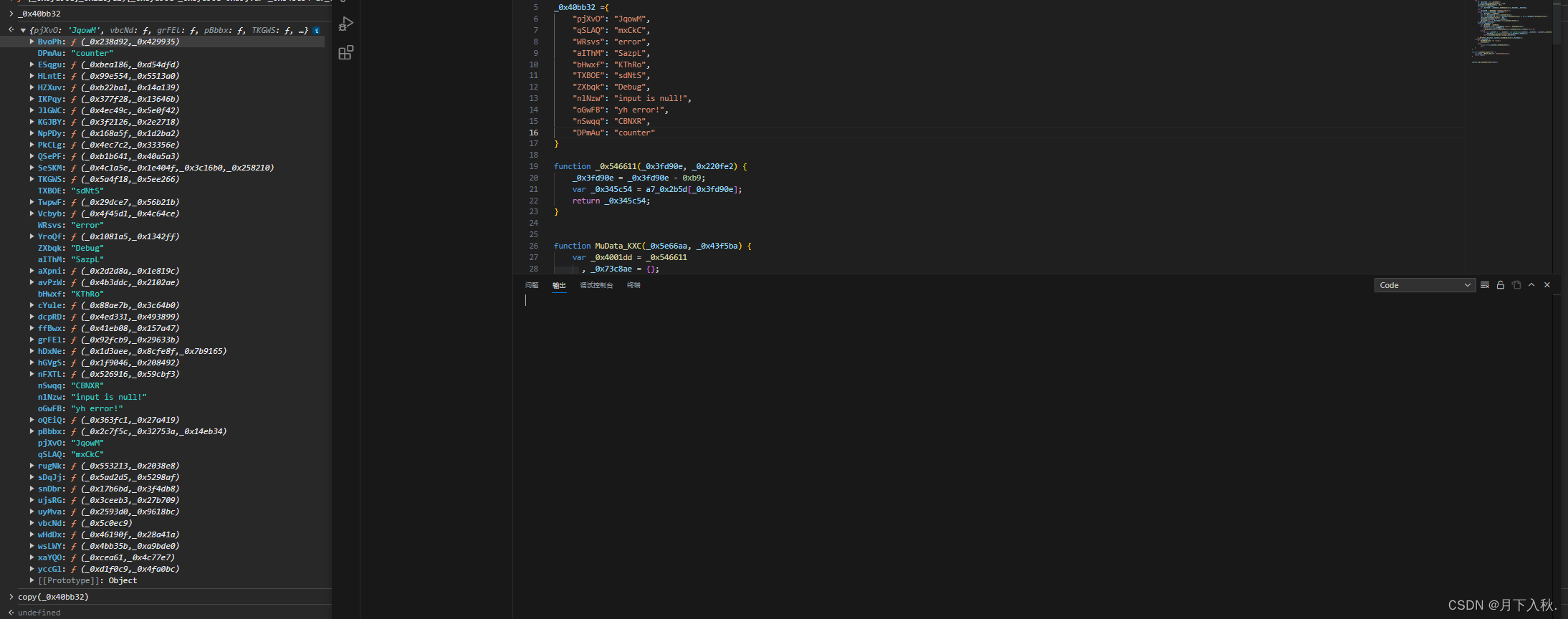
又补了两步,发现打印了null,去分析。发现在这个函数中,有一个try 对异常进行了捕获,看来是try分支里的代码报错,所以走了catch 打印了null 直接把try catch删掉,只保留try里的。
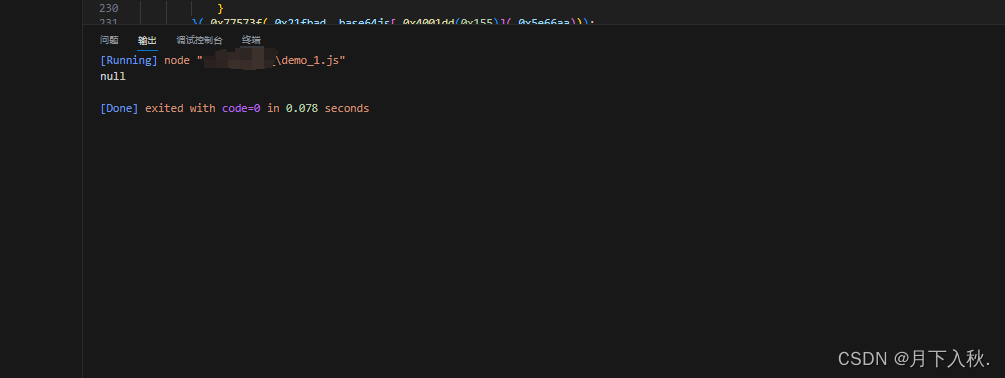

进行了上面的操作,又回到了熟悉的地方。缺什么补什么就好了。。。
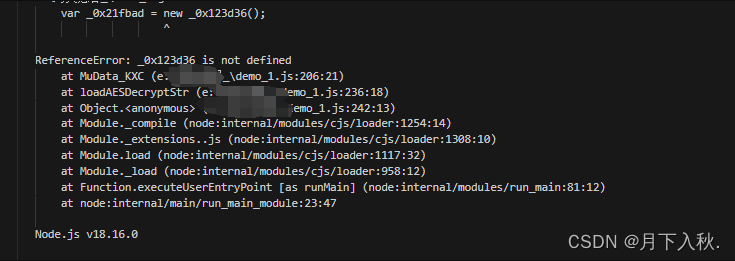
没补几步出来了这个错误,OK立刻想到上面的大数组, 把他补齐就好了 。到后面还有一个base64js的对象,这个不用补 但是有个Uint8Array这个小东西需要注意一下。
我就不补了 饿了 吃饭去了。。。体力活 挺简单的。















 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









