






新手入门真的很推荐尝试的一个练手的站——网易云评论。(仅供学习研究,如侵权联系删除)
话不多说直接切入主题,我们打开网易云随便找一个音乐。网易云音乐,对他这个页面进行分析,首先我们先抓包。

OK,我们找到了这个评论接口,我们可以看到这里面有两个加密参数,我们对他们进行分析。

我们直接在全局搜索 快捷键 shift + ctrl +f

如果不想搜索,我们也可以打XHR断点,或者跟栈一步一步找,我懒我就直接全局搜索了。点进去之后是下面这样,params和encSecKey 都是从bMs6m里面获得的,然后我们发现bMs6m就在上面那一行,所以我们发现了这个加密位置就是这里,

打上断点跟进去发现url在这里被传入进去,并不是我们要找的那个接口 我们要找的接口是评论接口而这个是啥我也不知道~~~~ 我们可以释放断点看看他有什么变化。

果然!!!点了两下,接口就被发现了,然后我们对加密函数,也就是打断点的地方的参数分析。

第一个JSON.stringify(i5n) 直接在控制台打印,发现是个字符串

第二个bsi3x(["流泪", "强"]) 在控制台打印也是个字符串,第三个第四个以此类推,我懒我不弄了。

四个参数都弄出来之后 我们发现除了第一个是变化的,剩下三个是不变的(打开另一个歌曲的页面自己去试!我说的没错!!!!)
然后就要对加密函数进行分析了,明显加密函数是window.asrsea
追进去!!!!!!

追进去之后定位到这个函数,我们直接TM抠出来


别忘了传进去我们需要的参数(注:rid":"R_SO_4_2019620319","threadId":"R_SO_4_2019620319" 这两个参数中,R_SO_4_后面加的是歌曲id)
args ='{"rid":"R_SO_4_2019620319","threadId":"R_SO_4_2019620319","pageNo":"1","pageSize":"20","cursor":"-1","offset":"0","orderType":"1","csrf_token":""}'
args1 = "010001"
args2 = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
args3 = "0CoJUm6Qyw8W8jud"
然后我们开始,开始运行,扣代码

缺啥补啥这缺a,我们在浏览器的控制台console去搜索a然后补上!缺啥补啥!记住!
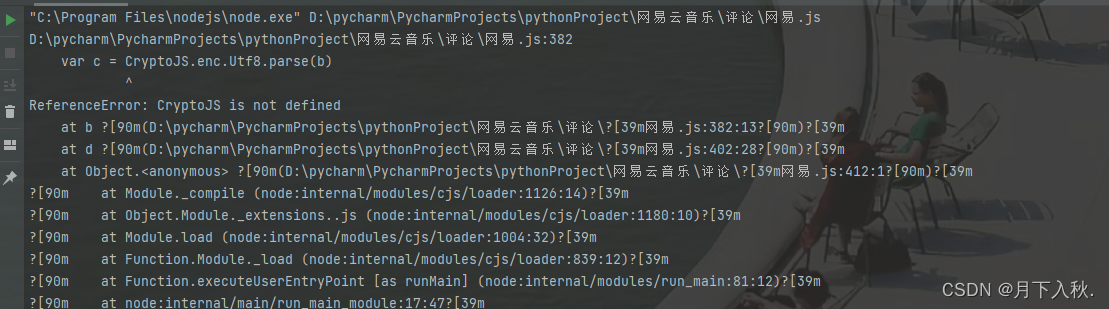 在补了两三行后,我们发现报 CryptoJS is not defined ,然后发现这是一个AES加密
在补了两三行后,我们发现报 CryptoJS is not defined ,然后发现这是一个AES加密
我们直接导库,先在终端(terminal)输入 npm i crypto-js 这里要注意一下 一定要是
crypto-js 不能是 cryptojs,这两个东西虽然很像,但是不是一个东西!仔细!!!!
var CryptoJS = require("crypto-js")然后把它补上 我一般都是补在程序的第一行。
然后我们缺啥补啥就行了,直到不报错

然后我们封装一个函数去return d方法 ,然后通过execjs调用一下,然后在request一下,直接拿到数据。


完结撒花,爬虫路上的第一个独立完成的案例,值得记录一下。















 213
213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









