






前言:
搭建一套稳定的代理池服务,可以保证爬虫的快速稳定运行,应对一些反爬技术。
一、安装redis
Redis是一个字典结构的存储服务器,主要用来存储代理ip。
redis下载地址:Releases · tporadowski/redis · GitHub
本文以5.0.14版本为例,下载并解压文件,文件内容如下:

打开cmd窗口,进入redis路径使用如下命令运行redis:
redis-server.exe redis.windows.conf当然也可以将redis路径加入到系统环境变量,以后使用会方便一点。
验证redis是否可以正常使用。
连接redis:
redis-cli.exe -h 127.0.0.1 -p 6379设置键值对:
set myKey abc取出键值对:
get myKey
设置redis密码:
config get requirepass //查看密码(没有设置的话返回的密码为空) 
config set requirepass 123456 //设置密码为123456

密码设置成功后需要重新登录:
redis-cli.exe -h 127.0.0.1 -p 6379 -a 123456redis安装结束
二、下载配置python代理池爬虫项目
下载并解压开源项目 https://github.com/jhao104/proxy_pool
本文以2.4.0为例:

修改setting.py配置文件,修改本地的redis连接密码
DB_CONN = 'redis://:123456@127.0.0.1:6379/0'安装依赖:
pip install -r requirements.txt
使用cmd打开当前项目目录,
# 启动调度程序
python proxyPool.py schedule
# 启动webApi服务
python proxyPool.py serverapi使用:
| /get | GET | 随机获取一个代理| 可选参数: `?type=https` 过滤支持https的代理|
| /pop | GET | 获取并删除一个代理| 可选参数: `?type=https` 过滤支持https的代理|
| /all | GET | 获取所有代理 |可选参数: `?type=https` 过滤支持https的代理|
| /count | GET | 查看代理数量 |None|
| /delete | GET | 删除代理 |`?proxy=host:ip`|
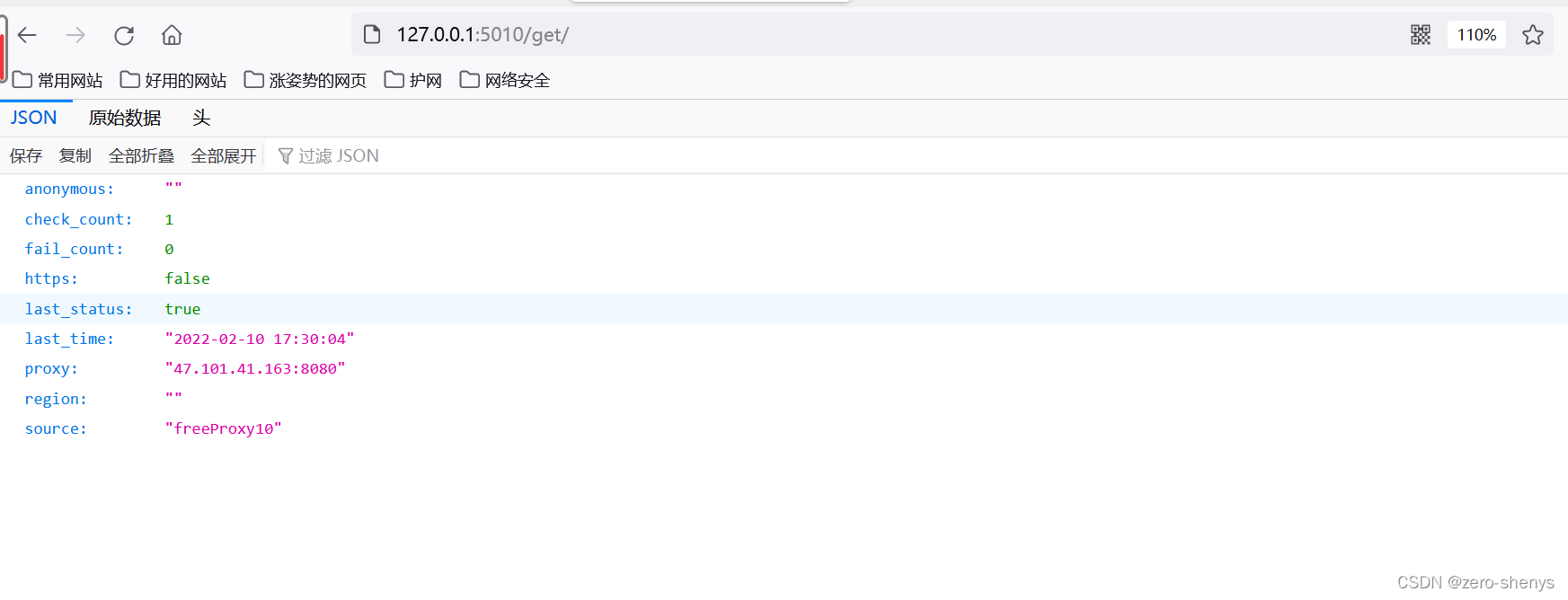
到此,代理池搭建完毕。














 86
86











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









