



参考:大数据技术原理与应用(第3版)林子雨 编著
目录
BigTable
BigTable是一个分布式存储系统。
BigTable解决谷歌公司内部大规模网页搜索问题,存储其大量网页。
BigTable的诞生:
1.主要满足互联网搜索引擎的基本需求
2.用于网页搜索
3.用于谷歌非常多的项目里面,包括搜索、地图、财经、打印
4.还用于一些社交网站、视频共享网站、博客网站等
BigTable受到广泛关注的原因:
1.具有非常好的性能(可以支持PB级别的数据)
2.具有非常好的可扩展性(用集群去存储几千台服务器完成分布式存储)
BigTable特性:
1.支持大规模海量数据
2.分布式并发数据处理效率极高
3.易于扩展、支持动态伸缩
4.适用于廉价设备
5.适合读操作不适合写操作
HBase简介
HBase是谷歌BigTable的开源实现
Hadoop生态系统中HBase与其他部分的关系
- HBase利用Hadoop MapReduce来处理HBase中的海量数据,实现高性能计算
- 利用ZooKeeper作为协同服务,实现稳定服务和失败恢复
- 使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力
- Sqoop提供了高效、便捷的关系数据库管理系统数据导入功能
- Pig和Hive为HBase提供了高层语言支持
HBase和BigTable的底层技术对应关系
| BigTable | HBase | |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同服务管理 | Chubby | Zookeeper |
已有关系数据库、Hadoop(HDFS和MapReduce),为什么还要去设计HBase?
1.虽然已有HDFS和MapReduce,但Hadoop主要解决大规模数据离线批量处理,Hadoop是没办法满足大数据实时处理需求。
2.随着这些年数据大规模爆炸式增长,传统关系数据库的扩展能力有限
3.两个缺陷:不便利、效率低
HBase与传统关系数据库的对比分析
- 数据类型:关系数据库采用关系模型,具有丰富数据类型和存储方式。HBase采用更简单的数据模型,把数据存储为未经解释的字符串
- 数据操作:HBase避免复杂的表与表之间的关系,采用单表主键查询,无法实现像关系数据库中那样的表与表之间的连接操作
- 存储模式:关系数据库基于行模式存储,HBase基于列存储
- 数据索引:关系数据库通常多个索引。HBase只有一个索引——行键
- 数据维护:关系数据库会替换旧值,更新后旧值不存在。HBase不会删除数据的旧版本,生成一个新版本后,旧版本仍然保留。
- 可伸缩性:关系数据库难实现横向扩展,纵向扩展空间也有限。HBase实现灵活的横向扩展,能轻易通过在集群中增加或减少硬件数量来实现性能的伸缩。
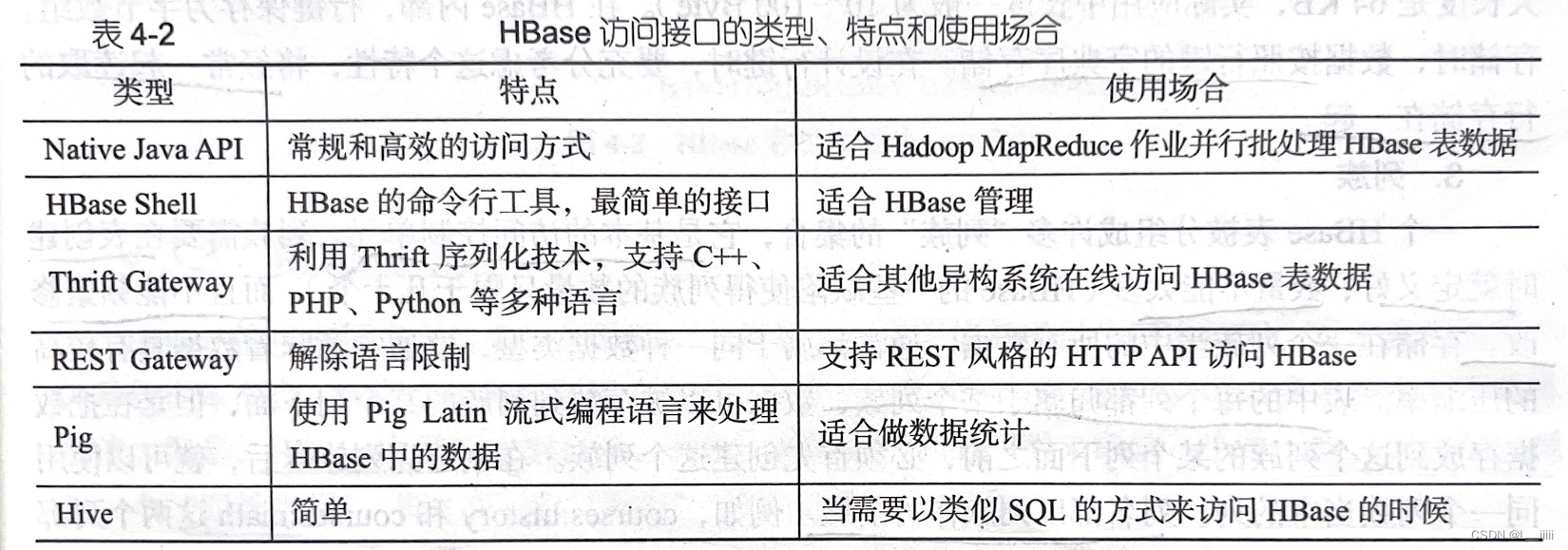
HBase访问接口
HBase数据模型
HBase是一个稀疏、多维度、排序的映射表。采用行键、列族、列限定符、时间戳进行索引。
数据模型的相关概念
1.表:HBase采用表来组织数据,由行和列组成,列划分为若干个列族。
2.行键:每个行有行键来标识。行键可以是任意字符串。经常一起读取的行存储在一起。
访问表中的行的方式(3种):
(1)通过单个行键访问
(2)通过一个行键的区间来访问
(3)全表扫描
3.列族:一个HBase表被分组成许多列族集合,是基本的访问控制单元。支持动态扩展、保留旧版本。
4.列限定符:列族中数据通过列限定符(或列)来定位,不需要事先定义。
5.单元格:每个单元格中可以保存一个数据的多个版本,每个版本对应一个时间戳。
6.时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引。
数据坐标
HBase使用四维坐标来定位表中的数据。四维坐标:[“行键”,“列族”,“列限定符”,“时间戳”]
HBase可以看作一个键值数据库。
列式存储——>按一个列去存储——>可以带来很高的数据压缩率
HBase的实现原理
HBase的功能组件
HBase的实现包括三个主要的功能组件:
库函数:一般用于连接每个客户端
Master服务器:充当管家的作用
Region服务器:负责存储不同的Region
Master服务器的功能:
1.对分区信息进行维护和管理
2.维护一个Region服务器列表
3.检测整个集群当中有哪些Region服务器在工作
4.负责对Region进行分配
5.负载平衡



















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











