







锟斤拷烫烫烫
你一定在学习的过程中遇到过这种编码,但你有没有想过它们是如何出现的呢?
这就必须要说一下计算机存储字符的问题了。
计算机存储字符
我们都知道,计算机只能认识010101这样的二进制数字,但是人类日常使用的却是“ABC”、“你好”这样的文字,所以想要让普通人也能够看懂计算机的文字,就必须建立两者之间的桥梁,这就是字符集,即二进制编码与自然语言之间的映射关系。
ASCII
众所周知,我们现在用到的计算机发扬于大洋彼岸的美利坚,所以世界上第一份字符集也自然而然的是二进制代码与西欧字母之间的映射表,即ASCII字符集。ASCII字符集由美国国家标准局ANSI制定,包含了26个英文字母以及常见的各种字符,共计128个,也就是说用7位二进制数字就可以表示整个ASCII字符集,但是由于在计算机中一般使用1字节,即8位进行存储,所以根据ASCII字符集创造的ASCII编码一般也使用8位来进行字符的存储。
下面是一张ASCII字符集对应关系图:
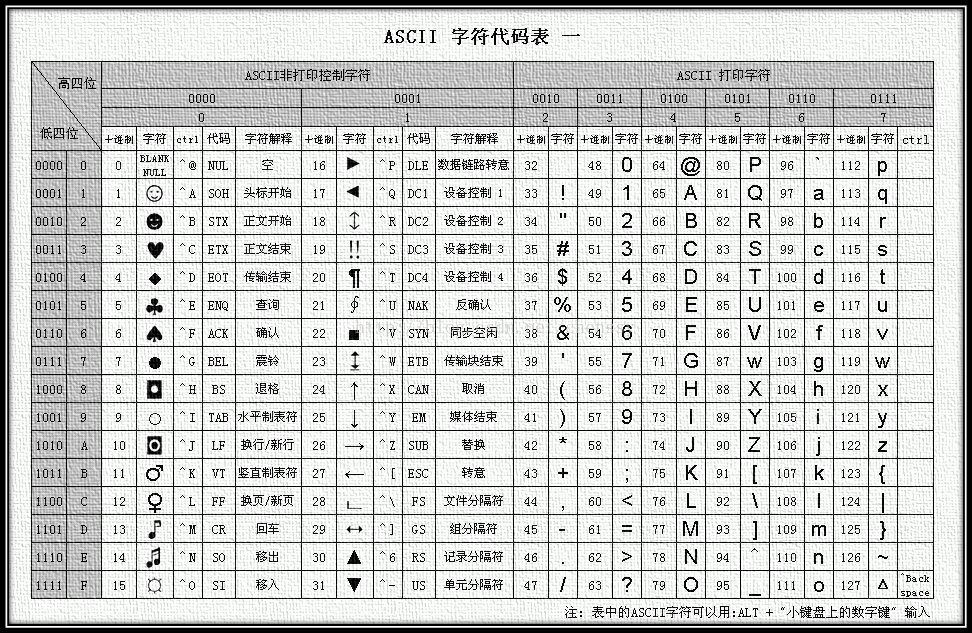
如图所示,A对应的高4位是0100,低4位是0001,组合在一起即为0100 0001,就是65。
一段话,计算机在进行解码的时候,每8位进行一次切割,打印对应的字符即可输出正确内容。

GB2312
ASCII字符集被创造出来的时候,这份字符集成功的解决了人与计算机沟通的问题,但随着时间的流逝,计算机在不同的国家也吸引了大批用户,这个时候ASCII字符集显然就不够用了,于是我国在1980年发布了属于中文与计算机二进制的映射关系,就是GB2312字符集。在这个字符集中一共收录了6763个汉字和682个非汉字图形字符。与此同时,日本、港台等地也制定了不同的字符集,例如港台使用Big5编码。想象一下,如果你有一个朋友住在台湾,而你们要进行电子邮件的往来,你的电脑支持GB2312字符编码,而他的电脑支持Big5字符编码,这会出现什么问题呢?由于编解码规则不一致,你写的电子邮件在他的电脑上只会出现一堆乱码。
Unicode
于是有人说“我想让所有人都在同一台电脑上看到自己认识的文字!”,Unicode编码横空出世,即万国码,他致力于在一个编码表中加入所有的文字、非文字。如果所有的电脑都装上了这样的字符编码,你写给你朋友的电子邮件就可以正常的被解码出来了。

UTF-8、UTF-32
前面说了很多,都是在说“字符集”,那么什么是“字符编码”呢?就是真正实现了“字符集”的一套规则实现。不论是ASCII字符集还是GB2312字符集,它们的字符编码实现起来就是直接基于字符集进行的。但是在Unicode字符集这里就遇到了问题,ASCII字符集只有1个字节,GB2312有2个字节,到了Unicode这里一下就要4个字节了!西欧国家的用户可不乐意了,以前存储文章1个字符只要1字节,现在直接扩大了4倍!

所以聪明的人又想到了UTF-8这个字符编码,即不必要每个字符都用4个字节来表示,在万国码的基础上,大大降低了存储代价,真是美哉。
那UTF-8到底是怎么实现的呢?首先获取一个字符对应Unicode的编码值,然后一顿操作,就ok了!这个过程不容易用语言来形容,直接上图来解释吧。
首先我们先讲讲UTF-8是如何做到不全使用4字节来表示字符的,UTF-8在对二进制编码进行解码的时候,如果遇到了0开头的字节,就说明之后只有1个字节表示对应的字符;如果遇到了110开头的字节,就说明这个字符是用2个字节来表示的;如果是1110,那就说明是是3格字节来表示这个字符,以此类推。
我们看一张表,这张表中记录了不同范围的Unicode字符值对应的UTF-8字符值:

我们先获取“你”的Unicode字符编码:百度一下可以得到是16进制数字4F60,所以属于在3字节表示的范围内。
4F60对应的2进制编码为00000000 00000000 01001111 01100000,拆分成对应的UTF08形式
11100100 10111101 10100000。
是不是非常神奇?
总结
现在再回头看看“锟斤拷”的问题,在我们的电脑中,虽然支持了Unicode字符集,但是这不代表我们的电脑拥有字符集中的所有字符,比如某个新出的emoji就不在我们的电脑中,这个时候,Unicode中一个神奇的字符就要发挥作用了,那就是�,有些编辑器会在UTF-8无法解码或无法表示字符的时候主动将对应的字符替换为�,而这个字符对应的编码又是FFFD,对应的UTF-8二进制编码为11101111 10111111 10111101,如果恰好有两个�连在一起,那么就会出现11101111 10111111 10111101 11101111 10111111 10111101的情况,如果又恰好你用了GBK编码进行解码的话,就会将这6个字节分成3组(GBK用两个字节表示一个字符),如图所示。

而在GBK中刚好EFBF对应的就是“锟”、BFEF对应的就是“斤”,BFBD对应的就是“拷”。
不得不赞赏发明了Unicode字符集和UTF-8编码的先辈们的智慧,正如其名“万国码”,让整个世界的计算机用户都可以通过一套字符集看见自己的文字,对文化的交流做出了无比巨大的贡献。
后记
如果你喜欢这篇文章,不妨点个赞。
如果有什么问题或错误请大家踊跃留言,理性讨论。
你的支持就是作者创作的动力。















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









