







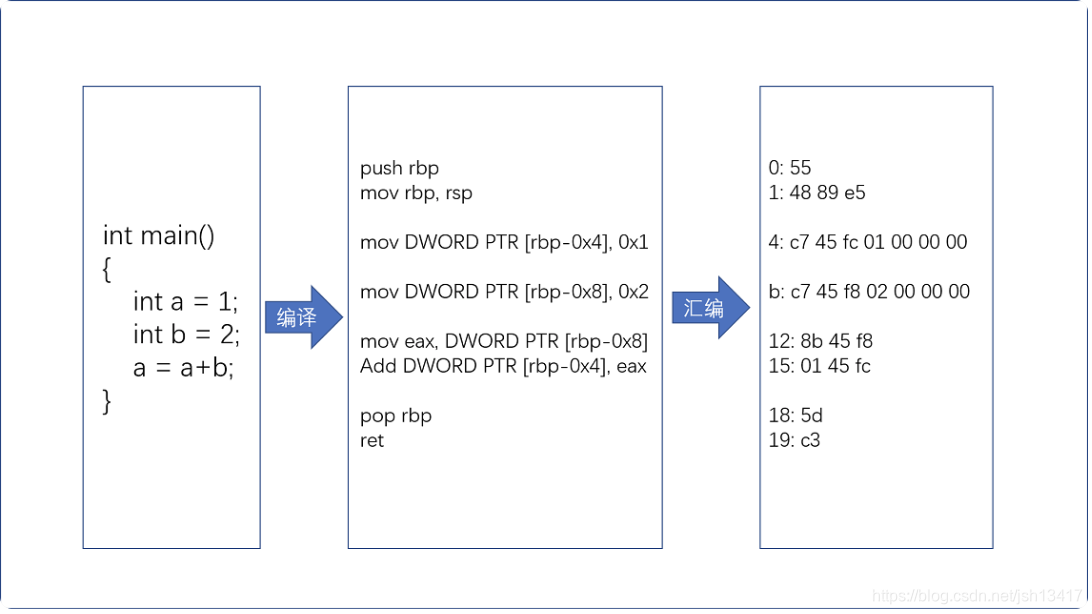
编译到汇编,代码从如何变成机器码
看下面的C代码示例:
#include <stdio.h>
int main()
{
int a = 1;
int b = 2;
a = a + b;
return 0 ;
}
通过编译和汇编后生成机器码
[root@localhost ~]# gcc -g -c test.c
[root@localhost ~]# ls
anaconda-ks.cfg test.c test.o
[root@localhost ~]# objdump -d -M intel -S test.o
test.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
#include <stdio.h>
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 1;
4: c7 45 fc 01 00 00 00 mov DWORD PTR [rbp-0x4],0x1
int b = 2;
b: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
a = a + b;
12: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
15: 01 45 fc add DWORD PTR [rbp-0x4],eax
return 0 ;
18: b8 00 00 00 00 mov eax,0x0
}
1d: 5d pop rbp
1e: c3 ret
详细的转换关系如下图所示:
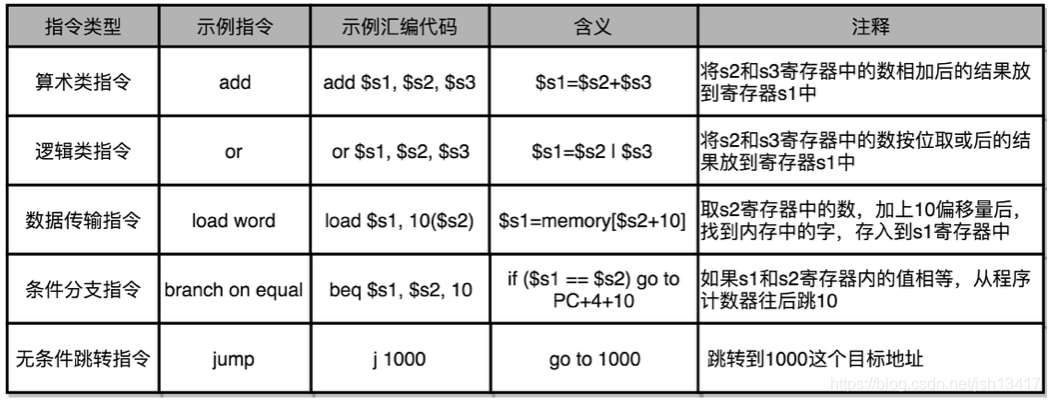
在inter 处理器中大概支持2000多种机器指令集,常见的指令可以分为下面的五类:
IF else 条件指令学习
#include <time.h>
#include <stdlib.h>
int main()
{
srand(time(NULL));
int r = rand() % 2;
int a = 10;
if (r == 0)
{
a = 1;
} else {
a = 2;
}
对应上面if条件的指令如下:
if (r == 0)
3b: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
3f: 75 09 jne 4a <main+0x4a>
{
a = 1;
41: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x1
48: eb 07 jmp 51 <main+0x51>
}
else
{
a = 2;
4a: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
51: b8 00 00 00 00 mov eax,0x0
}
cmp 指令比较了前后两个操作数的值,这里的 DWORD PTR 代表操作的数据类型是 32 位的整数,而 [rbp-0x4] 则是一个寄存器的地址。所以,第一个操作数就是从寄存器里拿到的变量 r 的值。第二个操作数 0x0 就是我们设定的常量 0 的 16 进制表示。cmp 指令的比较结果,会存入到条件码寄存器当中去。
跟着的 jne 指令,是 jump if not equal 的意思,它会查看对应的零标志位。如果为 0,会跳转到后面跟着的操作数 4a 的位置。这个 4a,对应这里汇编代码的行号,也就是上面设置的 else 条件里的第一条指令。当跳转发生的时候,PC 寄存器就不再是自增变成下一条指令的地址,而是被直接设置成这里的 4a 这个地址。这个时候,CPU 再把 4a 地址里的指令加载到指令寄存器中来执行。跳转到执行地址为 4a 的指令,实际是一条 mov 指令,第一个操作数和前面的 cmp 指令一样,是另一个 32 位整型的寄存器地址,以及对应的 2 的 16 进制值 0x2。mov 指令把 2 设置到对应的寄存器里去,相当于一个赋值操作。然后,PC 寄存器里的值继续自增,执行下一条 mov 指令。这条 mov 指令的第一个操作数 eax,代表累加寄存器,第二个操作数 0x0 则是 16 进制的 0 的表示。这条指令其实没有实际的作用,它的作用是一个占位符。我们回过头去看前面的 if 条件,如果满足的话,在赋值的 mov 指令执行完成之后,有一个 jmp 的无条件跳转指令。跳转的地址就是这一行的地址 51。我们的 main 函数没有设定返回值,而 mov eax, 0x0 其实就是给 main 函数生成了一个默认的为 0 的返回值到累加器里面。if 条件里面的内容执行完成之后也会跳转到这里,和 else 里的内容结束之后的位置是一样的。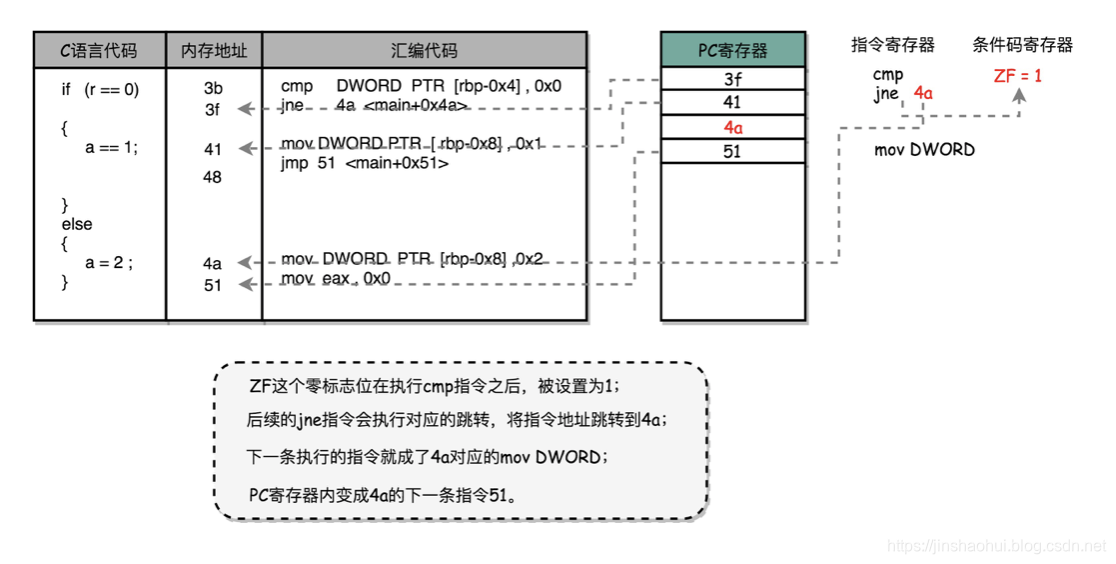
for 循环指令
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
int a = 0;
4: c7 45 fc 00 00 00 00 mov DWORD PTR [rbp-0x4],0x0
int i;
for( i = 0; i < 5; i ++)
b: c7 45 f8 00 00 00 00 mov DWORD PTR [rbp-0x8],0x0
12: eb 0a jmp 1e <main+0x1e>
{
a += i;
14: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
17: 01 45 fc add DWORD PTR [rbp-0x4],eax
for( i = 0; i < 5; i ++)
1a: 83 45 f8 01 add DWORD PTR [rbp-0x8],0x1
1e: 83 7d f8 04 cmp DWORD PTR [rbp-0x8],0x4
22: 7e f0 jle 14 <main+0x14>
}
return 0;
24: b8 00 00 00 00 mov eax,0x0
}
29: 5d pop rbp
2a: c3 ret
JLE ;有符号小于等于则跳转
JMP;无条件跳转
JNE;不等于侧跳转
switch 指令
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 48 83 ec 10 sub rsp,0x10
char a = getchar();
8: e8 00 00 00 00 call d <main+0xd>
d: 88 45 ff mov BYTE PTR [rbp-0x1],al
int b = 0;
10: c7 45 f8 00 00 00 00 mov DWORD PTR [rbp-0x8],0x0
switch(a)
17: 0f be 45 ff movsx eax,BYTE PTR [rbp-0x1]
1b: 83 f8 02 cmp eax,0x2
1e: 74 13 je 33 <main+0x33>
20: 83 f8 03 cmp eax,0x3
23: 74 17 je 3c <main+0x3c>
25: 83 f8 01 cmp eax,0x1
28: 75 1a jne 44 <main+0x44>
{
case 1:
b = 2;
2a: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
break;
31: eb 11 jmp 44 <main+0x44>
case 2:
b = 9;
33: c7 45 f8 09 00 00 00 mov DWORD PTR [rbp-0x8],0x9
break;
3a: eb 08 jmp 44 <main+0x44>
case 3:
b = 5;
3c: c7 45 f8 05 00 00 00 mov DWORD PTR [rbp-0x8],0x5
break;
43: 90 nop
}
return 0;
44: b8 00 00 00 00 mov eax,0x0
}
49: c9 leave
4a: c3 ret
if 条件多个的判断
if (r== 0)
4c: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
50: 75 09 jne 5b <main+0x5b>
{
a = 1;
52: c7 45 f8 01 00 00 00 mov DWORD PTR [rbp-0x8],0x1
59: eb 16 jmp 71 <main+0x71>
}else if(r==1){
5b: 83 7d fc 01 cmp DWORD PTR [rbp-0x4],0x1
5f: 75 09 jne 6a <main+0x6a>
a = 2;
61: c7 45 f8 02 00 00 00 mov DWORD PTR [rbp-0x8],0x2
68: eb 07 jmp 71 <main+0x71>
}else{
a = 3;
6a: c7 45 f8 03 00 00 00 mov DWORD PTR [rbp-0x8],0x3
}
}
从上面的汇编语言来看,判断条件大于2个话,使用switch性能更好,还有case分支中越容易发生的放在前面。
我们再看下面三目远算和if else 区别
当三目运算的数值非0和1时,和if esle 指令时一模一样的。具体看下面:
b = (r == 0)?2:3;
71: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
75: 75 07 jne 7e <main+0x7e>
77: b8 02 00 00 00 mov eax,0x2
7c: eb 05 jmp 83 <main+0x83>
7e: b8 03 00 00 00 mov eax,0x3
83: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
b = (r == 0)?0:1;
86: 83 7d fc 00 cmp DWORD PTR [rbp-0x4],0x0
8a: 0f 95 c0 setne al
8d: 0f b6 c0 movzx eax,al
90: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
函数调用
一个简单add函数操作和具体的汇编代码。
#include <stdio.h>
int static add(int a,int b)
{
return a + b;
}
int main()
{
int x = 5;
int y = 10;
int u = add(x,y);
return 0;
}
汇编代码
int static add(int a,int b)
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 89 7d fc mov DWORD PTR [rbp-0x4],edi
7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
return a + b;
a: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
d: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
10: 01 d0 add eax,edx
}
12: 5d pop rbp
13: c3 ret
0000000000000014 <main>:
int main()
{
14: 55 push rbp
15: 48 89 e5 mov rbp,rsp
18: 48 83 ec 10 sub rsp,0x10
int x = 5;
1c: c7 45 fc 05 00 00 00 mov DWORD PTR [rbp-0x4],0x5
int y = 10;
23: c7 45 f8 0a 00 00 00 mov DWORD PTR [rbp-0x8],0xa
int u = add(x,y);
2a: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
2d: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
30: 89 d6 mov esi,edx
32: 89 c7 mov edi,eax
34: e8 c7 ff ff ff call 0 <add>
39: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
return 0;
3c: b8 00 00 00 00 mov eax,0x0
}
41: c9 leave
42: c3 ret
对应上面函数 add 的汇编代码,我们来仔细看看,main 函数调用 add 函数时,add 函数入口在 0~1 行,add 函数结束之后在 12~13 行。我们在调用第 34 行的 call 指令时,会把当前的 PC 寄存器里的下一条指令的地址压栈,保留函数调用结束后要执行的指令地址。而 add 函数的第 0 行,push rbp 这个指令,就是在进行压栈。这里的 rbp 又叫栈帧指针(Frame Pointer),是一个存放了当前栈帧位置的寄存器。push rbp 就把之前调用函数,也就是 main 函数的栈帧的栈底地址,压到栈顶。接着,第 1 行的一条命令 mov rbp, rsp 里,则是把 rsp 这个栈指针(Stack Pointer)的值复制到 rbp 里,而 rsp 始终会指向栈顶。这个命令意味着,rbp 这个栈帧指针指向的地址,变成当前最新的栈顶,也就是 add 函数的栈帧的栈底地址了。而在函数 add 执行完成之后,又会分别调用第 12 行的 pop rbp 来将当前的栈顶出栈,这部分操作维护好了我们整个栈帧。然后,我们可以调用第 13 行的 ret 指令,这时候同时要把 call 调用的时候压入的 PC 寄存器里的下一条指令出栈,更新到 PC 寄存器中,将程序的控制权返回到出栈后的栈顶。
rbp 是属于当前函数的栈空间基地址,rsp 是包含当前函数为被调用函数准备的栈空间的基地址。
ELF 和静态链接
我们把上面的add示例进行拆分成add_lib.c和link.c,
//add_lib.c
int add(int a,int b)
{
return a + b;
}
//link.c
#include <stdio.h>
int main()
{
int a = 10;
int b = 5;
int c = add(a,b);
printf("c = %d\n",c);
}
对应的各个汇编程序如下
[jinsh@localhost 08]$ objdump -d -M intel -S add_lib.o
add_lib.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <add>:
int add(int a,int b)
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 89 7d fc mov DWORD PTR [rbp-0x4],edi
7: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
return a + b;
a: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
d: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
10: 01 d0 add eax,edx
}
12: 5d pop rbp
13: c3 ret [jinsh@localhost 08]$ objdump -d -M intel -S link.o
link.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
#include <stdio.h>
int main()
{
0: 55 push rbp
1: 48 89 e5 mov rbp,rsp
4: 48 83 ec 10 sub rsp,0x10
int a = 10;
8: c7 45 fc 0a 00 00 00 mov DWORD PTR [rbp-0x4],0xa
int b = 5;
f: c7 45 f8 05 00 00 00 mov DWORD PTR [rbp-0x8],0x5
int c = add(a,b);
16: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
19: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
1c: 89 d6 mov esi,edx
1e: 89 c7 mov edi,eax
20: b8 00 00 00 00 mov eax,0x0
25: e8 00 00 00 00 call 2a <main+0x2a>
2a: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
printf("c = %d\n",c);
2d: 8b 45 f4 mov eax,DWORD PTR [rbp-0xc]
30: 89 c6 mov esi,eax
32: bf 00 00 00 00 mov edi,0x0
37: b8 00 00 00 00 mov eax,0x0
3c: e8 00 00 00 00 call 41 <main+0x41>
}
41: c9 leave
42: c3 ret
我们生成可执行可连接的elf文件
[jinsh@localhost 08]$ gcc -o link add_lib.o link.o
[jinsh@localhost 08]$ file link
link: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=095a881508fdcdedeac58205b272e626f9616c7f, not stripped```
第一个部分由编译(Compile)、汇编(Assemble)以及链接(Link)三个阶段组成。在这三个阶段完成之后,我们就生成了一个可执行文件。第二部分,我们通过装载器(Loader)把可执行文件装载(Load)到内存中。CPU 从内存中读取指令和数据,来开始真正执行程序。

下面是ELF文件的基本组成部分

```c
[jinsh@localhost 08]$ objdump -d -M intel -S link
link: 文件格式 elf64-x86-64
Disassembly of section .init:
00000000004003e0 <_init>:
4003e0: 48 83 ec 08 sub rsp,0x8
4003e4: 48 8b 05 0d 0c 20 00 mov rax,QWORD PTR [rip+0x200c0d] # 600ff8 <__gmon_start__>
4003eb: 48 85 c0 test rax,rax
4003ee: 74 05 je 4003f5 <_init+0x15>
4003f0: e8 3b 00 00 00 call 400430 <__gmon_start__@plt>
4003f5: 48 83 c4 08 add rsp,0x8
4003f9: c3 ret
Disassembly of section .plt:
0000000000400400 <.plt>:
400400: ff 35 02 0c 20 00 push QWORD PTR [rip+0x200c02] # 601008 <_GLOBAL_OFFSET_TABLE_+0x8>
400406: ff 25 04 0c 20 00 jmp QWORD PTR [rip+0x200c04] # 601010 <_GLOBAL_OFFSET_TABLE_+0x10>
40040c: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
0000000000400410 <printf@plt>:
400410: ff 25 02 0c 20 00 jmp QWORD PTR [rip+0x200c02] # 601018 <printf@GLIBC_2.2.5>
400416: 68 00 00 00 00 push 0x0
40041b: e9 e0 ff ff ff jmp 400400 <.plt>
0000000000400420 <__libc_start_main@plt>:
400420: ff 25 fa 0b 20 00 jmp QWORD PTR [rip+0x200bfa] # 601020 <__libc_start_main@GLIBC_2.2.5>
400426: 68 01 00 00 00 push 0x1
40042b: e9 d0 ff ff ff jmp 400400 <.plt>
0000000000400430 <__gmon_start__@plt>:
400430: ff 25 f2 0b 20 00 jmp QWORD PTR [rip+0x200bf2] # 601028 <__gmon_start__>
400436: 68 02 00 00 00 push 0x2
40043b: e9 c0 ff ff ff jmp 400400 <.plt>
Disassembly of section .text:
0000000000400440 <_start>:
400440: 31 ed xor ebp,ebp
400442: 49 89 d1 mov r9,rdx
400445: 5e pop rsi
400446: 48 89 e2 mov rdx,rsp
400449: 48 83 e4 f0 and rsp,0xfffffffffffffff0
40044d: 50 push rax
40044e: 54 push rsp
40044f: 49 c7 c0 00 06 40 00 mov r8,0x400600
400456: 48 c7 c1 90 05 40 00 mov rcx,0x400590
40045d: 48 c7 c7 41 05 40 00 mov rdi,0x400541
400464: e8 b7 ff ff ff call 400420 <__libc_start_main@plt>
400469: f4 hlt
40046a: 66 0f 1f 44 00 00 nop WORD PTR [rax+rax*1+0x0]
0000000000400470 <deregister_tm_clones>:
400470: b8 3f 10 60 00 mov eax,0x60103f
400475: 55 push rbp
400476: 48 2d 38 10 60 00 sub rax,0x601038
40047c: 48 83 f8 0e cmp rax,0xe
400480: 48 89 e5 mov rbp,rsp
400483: 77 02 ja 400487 <deregister_tm_clones+0x17>
400485: 5d pop rbp
400486: c3 ret
400487: b8 00 00 00 00 mov eax,0x0
40048c: 48 85 c0 test rax,rax
40048f: 74 f4 je 400485 <deregister_tm_clones+0x15>
400491: 5d pop rbp
400492: bf 38 10 60 00 mov edi,0x601038
400497: ff e0 jmp rax
400499: 0f 1f 80 00 00 00 00 nop DWORD PTR [rax+0x0]
00000000004004a0 <register_tm_clones>:
4004a0: b8 38 10 60 00 mov eax,0x601038
4004a5: 55 push rbp
4004a6: 48 2d 38 10 60 00 sub rax,0x601038
4004ac: 48 c1 f8 03 sar rax,0x3
4004b0: 48 89 e5 mov rbp,rsp
4004b3: 48 89 c2 mov rdx,rax
4004b6: 48 c1 ea 3f shr rdx,0x3f
4004ba: 48 01 d0 add rax,rdx
4004bd: 48 d1 f8 sar rax,1
4004c0: 75 02 jne 4004c4 <register_tm_clones+0x24>
4004c2: 5d pop rbp
4004c3: c3 ret
4004c4: ba 00 00 00 00 mov edx,0x0
4004c9: 48 85 d2 test rdx,rdx
4004cc: 74 f4 je 4004c2 <register_tm_clones+0x22>
4004ce: 5d pop rbp
4004cf: 48 89 c6 mov rsi,rax
4004d2: bf 38 10 60 00 mov edi,0x601038
4004d7: ff e2 jmp rdx
4004d9: 0f 1f 80 00 00 00 00 nop DWORD PTR [rax+0x0]
00000000004004e0 <__do_global_dtors_aux>:
4004e0: 80 3d 4d 0b 20 00 00 cmp BYTE PTR [rip+0x200b4d],0x0 # 601034 <_edata>
4004e7: 75 11 jne 4004fa <__do_global_dtors_aux+0x1a>
4004e9: 55 push rbp
4004ea: 48 89 e5 mov rbp,rsp
4004ed: e8 7e ff ff ff call 400470 <deregister_tm_clones>
4004f2: 5d pop rbp
4004f3: c6 05 3a 0b 20 00 01 mov BYTE PTR [rip+0x200b3a],0x1 # 601034 <_edata>
4004fa: f3 c3 repz ret
4004fc: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
0000000000400500 <frame_dummy>:
400500: 48 83 3d 18 09 20 00 cmp QWORD PTR [rip+0x200918],0x0 # 600e20 <__JCR_END__>
400507: 00
400508: 74 1e je 400528 <frame_dummy+0x28>
40050a: b8 00 00 00 00 mov eax,0x0
40050f: 48 85 c0 test rax,rax
400512: 74 14 je 400528 <frame_dummy+0x28>
400514: 55 push rbp
400515: bf 20 0e 60 00 mov edi,0x600e20
40051a: 48 89 e5 mov rbp,rsp
40051d: ff d0 call rax
40051f: 5d pop rbp
400520: e9 7b ff ff ff jmp 4004a0 <register_tm_clones>
400525: 0f 1f 00 nop DWORD PTR [rax]
400528: e9 73 ff ff ff jmp 4004a0 <register_tm_clones>
000000000040052d <add>:
int add(int a,int b)
{
40052d: 55 push rbp
40052e: 48 89 e5 mov rbp,rsp
400531: 89 7d fc mov DWORD PTR [rbp-0x4],edi
400534: 89 75 f8 mov DWORD PTR [rbp-0x8],esi
return a + b;
400537: 8b 45 f8 mov eax,DWORD PTR [rbp-0x8]
40053a: 8b 55 fc mov edx,DWORD PTR [rbp-0x4]
40053d: 01 d0 add eax,edx
}
40053f: 5d pop rbp
400540: c3 ret
0000000000400541 <main>:
#include <stdio.h>
int main()
{
400541: 55 push rbp
400542: 48 89 e5 mov rbp,rsp
400545: 48 83 ec 10 sub rsp,0x10
int a = 10;
400549: c7 45 fc 0a 00 00 00 mov DWORD PTR [rbp-0x4],0xa
int b = 5;
400550: c7 45 f8 05 00 00 00 mov DWORD PTR [rbp-0x8],0x5
int c = add(a,b);
400557: 8b 55 f8 mov edx,DWORD PTR [rbp-0x8]
40055a: 8b 45 fc mov eax,DWORD PTR [rbp-0x4]
40055d: 89 d6 mov esi,edx
40055f: 89 c7 mov edi,eax
400561: b8 00 00 00 00 mov eax,0x0
400566: e8 c2 ff ff ff call 40052d <add>
40056b: 89 45 f4 mov DWORD PTR [rbp-0xc],eax
printf("c = %d\n",c);
40056e: 8b 45 f4 mov eax,DWORD PTR [rbp-0xc]
400571: 89 c6 mov esi,eax
400573: bf 20 06 40 00 mov edi,0x400620
400578: b8 00 00 00 00 mov eax,0x0
40057d: e8 8e fe ff ff call 400410 <printf@plt>
}
400582: c9 leave
400583: c3 ret
400584: 66 2e 0f 1f 84 00 00 nop WORD PTR cs:[rax+rax*1+0x0]
40058b: 00 00 00
40058e: 66 90 xchg ax,ax
0000000000400590 <__libc_csu_init>:
400590: 41 57 push r15
400592: 41 89 ff mov r15d,edi
400595: 41 56 push r14
400597: 49 89 f6 mov r14,rsi
40059a: 41 55 push r13
40059c: 49 89 d5 mov r13,rdx
40059f: 41 54 push r12
4005a1: 4c 8d 25 68 08 20 00 lea r12,[rip+0x200868] # 600e10 <__frame_dummy_init_array_entry>
4005a8: 55 push rbp
4005a9: 48 8d 2d 68 08 20 00 lea rbp,[rip+0x200868] # 600e18 <__init_array_end>
4005b0: 53 push rbx
4005b1: 4c 29 e5 sub rbp,r12
4005b4: 31 db xor ebx,ebx
4005b6: 48 c1 fd 03 sar rbp,0x3
4005ba: 48 83 ec 08 sub rsp,0x8
4005be: e8 1d fe ff ff call 4003e0 <_init>
4005c3: 48 85 ed test rbp,rbp
4005c6: 74 1e je 4005e6 <__libc_csu_init+0x56>
4005c8: 0f 1f 84 00 00 00 00 nop DWORD PTR [rax+rax*1+0x0]
4005cf: 00
4005d0: 4c 89 ea mov rdx,r13
4005d3: 4c 89 f6 mov rsi,r14
4005d6: 44 89 ff mov edi,r15d
4005d9: 41 ff 14 dc call QWORD PTR [r12+rbx*8]
4005dd: 48 83 c3 01 add rbx,0x1
4005e1: 48 39 eb cmp rbx,rbp
4005e4: 75 ea jne 4005d0 <__libc_csu_init+0x40>
4005e6: 48 83 c4 08 add rsp,0x8
4005ea: 5b pop rbx
4005eb: 5d pop rbp
4005ec: 41 5c pop r12
4005ee: 41 5d pop r13
4005f0: 41 5e pop r14
4005f2: 41 5f pop r15
4005f4: c3 ret
4005f5: 90 nop
4005f6: 66 2e 0f 1f 84 00 00 nop WORD PTR cs:[rax+rax*1+0x0]
4005fd: 00 00 00
0000000000400600 <__libc_csu_fini>:
400600: f3 c3 repz ret
Disassembly of section .fini:
0000000000400604 <_fini>:
400604: 48 83 ec 08 sub rsp,0x8
400608: 48 83 c4 08 add rsp,0x8
40060c: c3 ret
ELF 文件格式把各种信息,分成一个一个的 Section 保存起来。ELF 有一个基本的文件头(File Header),用来表示这个文件的基本属性,比如是否是可执行文件,对应的 CPU、操作系统等等。除了这些基本属性之外,大部分程序还有这么一些 Section:
首先是.text Section,也叫作代码段或者指令段(Code Section),用来保存程序的代码和指令;接着是.data Section,也叫作数据段(Data Section),用来保存程序里面设置好的初始化数据信息;
然后就是.rel.text Secion,叫作重定位表(Relocation Table)。重定位表里,保留的是当前的文件里面,哪些跳转地址其实是我们不知道的。比如上面的 link_example.o 里面,我们在 main 函数里面调用了 add 和 printf 这两个函数,但是在链接发生之前,我们并不知道该跳转到哪里,这些信息就会存储在重定位表里;
[jinsh@localhost 08]$ objdump -r link.o
link.o: 文件格式 elf64-x86-64
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
0000000000000026 R_X86_64_PC32 add-0x0000000000000004
0000000000000033 R_X86_64_32 .rodata
000000000000003d R_X86_64_PC32 printf-0x0000000000000004
RELOCATION RECORDS FOR [.debug_info]:
OFFSET TYPE VALUE
0000000000000006 R_X86_64_32 .debug_abbrev
000000000000000c R_X86_64_32 .debug_str+0x0000000000000027
0000000000000011 R_X86_64_32 .debug_str+0x0000000000000020
0000000000000015 R_X86_64_32 .debug_str+0x000000000000006f
0000000000000019 R_X86_64_64 .text
0000000000000029 R_X86_64_32 .debug_line
0000000000000030 R_X86_64_32 .debug_str+0x0000000000000097
0000000000000037 R_X86_64_32 .debug_str+0x00000000000000ae
000000000000003e R_X86_64_32 .debug_str
0000000000000045 R_X86_64_32 .debug_str+0x0000000000000013
000000000000004c R_X86_64_32 .debug_str+0x00000000000000ca
0000000000000053 R_X86_64_32 .debug_str+0x00000000000000d6
0000000000000061 R_X86_64_32 .debug_str+0x00000000000000c1
0000000000000068 R_X86_64_32 .debug_str+0x00000000000000e0
000000000000006f R_X86_64_32 .debug_str+0x00000000000000a9
0000000000000074 R_X86_64_32 .debug_str+0x00000000000000bc
000000000000007e R_X86_64_64 .text
RELOCATION RECORDS FOR [.debug_aranges]:
OFFSET TYPE VALUE
0000000000000006 R_X86_64_32 .debug_info
0000000000000010 R_X86_64_64 .text
RELOCATION RECORDS FOR [.debug_line]:
OFFSET TYPE VALUE
000000000000002a R_X86_64_64 .text
RELOCATION RECORDS FOR [.eh_frame]:
OFFSET TYPE VALUE
0000000000000020 R_X86_64_PC32 .text
最后是.symtab Section,叫作符号表(Symbol Table)。符号表保留了我们所说的当前文件里面定义的函数名称和对应地址的地址簿。我们可以通过下面的命令来查看符号表:
[jinsh@localhost 08]$ readelf -s link
Symbol table '.dynsym' contains 4 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FUNC GLOBAL DEFAULT UND printf@GLIBC_2.2.5 (2)
2: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_start_main@GLIBC_2.2.5 (2)
3: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
Symbol table '.symtab' contains 70 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000400238 0 SECTION LOCAL DEFAULT 1
2: 0000000000400254 0 SECTION LOCAL DEFAULT 2
3: 0000000000400274 0 SECTION LOCAL DEFAULT 3
4: 0000000000400298 0 SECTION LOCAL DEFAULT 4
5: 00000000004002b8 0 SECTION LOCAL DEFAULT 5
6: 0000000000400318 0 SECTION LOCAL DEFAULT 6
7: 0000000000400358 0 SECTION LOCAL DEFAULT 7
8: 0000000000400360 0 SECTION LOCAL DEFAULT 8
9: 0000000000400380 0 SECTION LOCAL DEFAULT 9
10: 0000000000400398 0 SECTION LOCAL DEFAULT 10
11: 00000000004003e0 0 SECTION LOCAL DEFAULT 11
12: 0000000000400400 0 SECTION LOCAL DEFAULT 12
13: 0000000000400440 0 SECTION LOCAL DEFAULT 13
14: 0000000000400604 0 SECTION LOCAL DEFAULT 14
15: 0000000000400610 0 SECTION LOCAL DEFAULT 15
16: 0000000000400628 0 SECTION LOCAL DEFAULT 16
17: 0000000000400668 0 SECTION LOCAL DEFAULT 17
18: 0000000000600e10 0 SECTION LOCAL DEFAULT 18
19: 0000000000600e18 0 SECTION LOCAL DEFAULT 19
20: 0000000000600e20 0 SECTION LOCAL DEFAULT 20
21: 0000000000600e28 0 SECTION LOCAL DEFAULT 21
22: 0000000000600ff8 0 SECTION LOCAL DEFAULT 22
23: 0000000000601000 0 SECTION LOCAL DEFAULT 23
24: 0000000000601030 0 SECTION LOCAL DEFAULT 24
25: 0000000000601034 0 SECTION LOCAL DEFAULT 25
26: 0000000000000000 0 SECTION LOCAL DEFAULT 26
27: 0000000000000000 0 SECTION LOCAL DEFAULT 27
28: 0000000000000000 0 SECTION LOCAL DEFAULT 28
29: 0000000000000000 0 SECTION LOCAL DEFAULT 29
30: 0000000000000000 0 SECTION LOCAL DEFAULT 30
31: 0000000000000000 0 SECTION LOCAL DEFAULT 31
32: 0000000000000000 0 FILE LOCAL DEFAULT ABS crtstuff.c
33: 0000000000600e20 0 OBJECT LOCAL DEFAULT 20 __JCR_LIST__
34: 0000000000400470 0 FUNC LOCAL DEFAULT 13 deregister_tm_clones
35: 00000000004004a0 0 FUNC LOCAL DEFAULT 13 register_tm_clones
36: 00000000004004e0 0 FUNC LOCAL DEFAULT 13 __do_global_dtors_aux
37: 0000000000601034 1 OBJECT LOCAL DEFAULT 25 completed.6355
38: 0000000000600e18 0 OBJECT LOCAL DEFAULT 19 __do_global_dtors_aux_fin
39: 0000000000400500 0 FUNC LOCAL DEFAULT 13 frame_dummy
40: 0000000000600e10 0 OBJECT LOCAL DEFAULT 18 __frame_dummy_init_array_
41: 0000000000000000 0 FILE LOCAL DEFAULT ABS add_lib.c
42: 0000000000000000 0 FILE LOCAL DEFAULT ABS link.c
43: 0000000000000000 0 FILE LOCAL DEFAULT ABS crtstuff.c
44: 0000000000400778 0 OBJECT LOCAL DEFAULT 17 __FRAME_END__
45: 0000000000600e20 0 OBJECT LOCAL DEFAULT 20 __JCR_END__
46: 0000000000000000 0 FILE LOCAL DEFAULT ABS
47: 0000000000600e18 0 NOTYPE LOCAL DEFAULT 18 __init_array_end
48: 0000000000600e28 0 OBJECT LOCAL DEFAULT 21 _DYNAMIC
49: 0000000000600e10 0 NOTYPE LOCAL DEFAULT 18 __init_array_start
50: 0000000000400628 0 NOTYPE LOCAL DEFAULT 16 __GNU_EH_FRAME_HDR
51: 0000000000601000 0 OBJECT LOCAL DEFAULT 23 _GLOBAL_OFFSET_TABLE_
52: 0000000000400600 2 FUNC GLOBAL DEFAULT 13 __libc_csu_fini
53: 0000000000601030 0 NOTYPE WEAK DEFAULT 24 data_start
54: 000000000040052d 20 FUNC GLOBAL DEFAULT 13 add
55: 0000000000601034 0 NOTYPE GLOBAL DEFAULT 24 _edata
56: 0000000000400604 0 FUNC GLOBAL DEFAULT 14 _fini
57: 0000000000000000 0 FUNC GLOBAL DEFAULT UND printf@@GLIBC_2.2.5
58: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_start_main@@GLIBC_
59: 0000000000601030 0 NOTYPE GLOBAL DEFAULT 24 __data_start
60: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
61: 0000000000400618 0 OBJECT GLOBAL HIDDEN 15 __dso_handle
62: 0000000000400610 4 OBJECT GLOBAL DEFAULT 15 _IO_stdin_used
63: 0000000000400590 101 FUNC GLOBAL DEFAULT 13 __libc_csu_init
64: 0000000000601038 0 NOTYPE GLOBAL DEFAULT 25 _end
65: 0000000000400440 0 FUNC GLOBAL DEFAULT 13 _start
66: 0000000000601034 0 NOTYPE GLOBAL DEFAULT 25 __bss_start
67: 0000000000400541 67 FUNC GLOBAL DEFAULT 13 main
68: 0000000000601038 0 OBJECT GLOBAL HIDDEN 24 __TMC_END__
69: 00000000004003e0 0 FUNC GLOBAL DEFAULT 11 _init
程序装载到内存
说起来只是装载到内存里面这一句话的事儿,实际上装载器需要满足两个要求。
第一,可执行程序加载后占用的内存空间应该是连续的。执行指令的时候,程序计数器是顺序地一条一条指令执行下去。这也就意味着,这一条条指令需要连续地存储在一起。
第二,我们需要同时加载很多个程序,并且不能让程序自己规定在内存中加载的位置。虽然编译出来的指令里已经有了对应的各种各样的内存地址,但是实际加载的时候,我们其实没有办法确保,这个程序一定加载在哪一段内存地址上。因为我们现在的计算机通常会同时运行很多个程序,可能你想要的内存地址已经被其他加载了的程序占用了。
我们把指令里用到的内存地址叫作虚拟内存地址(Virtual Memory Address),实际在内存硬件里面的空间地址,我们叫物理内存地址(Physical Memory Address)。程序里有指令和各种内存地址,我们只需要关心虚拟内存地址就行了。对于任何一个程序来说,它看到的都是同样的内存地址。我们维护一个虚拟内存到物理内存的映射表,这样实际程序指令执行的时候,会通过虚拟内存地址,找到对应的物理内存地址,然后执行。因为是连续的内存地址空间,所以我们只需要维护映射关系的起始地址和对应的空间大小就可以了。
我们来看这样一个例子。我现在手头的这台电脑,有 1GB 的内存。我们先启动一个图形渲染程序,占用了 512MB 的内存,接着启动一个 Chrome 浏览器,占用了 128MB 内存,再启动一个 Python 程序,占用了 256MB 内存。这个时候,我们关掉 Chrome,于是空闲内存还有 1024 - 512 - 256 = 256MB。按理来说,我们有足够的空间再去装载一个 200MB 的程序。但是,这 256MB 的内存空间不是连续的,而是被分成了两段 128MB 的内存。因此,实际情况是,我们的程序没办法加载进来。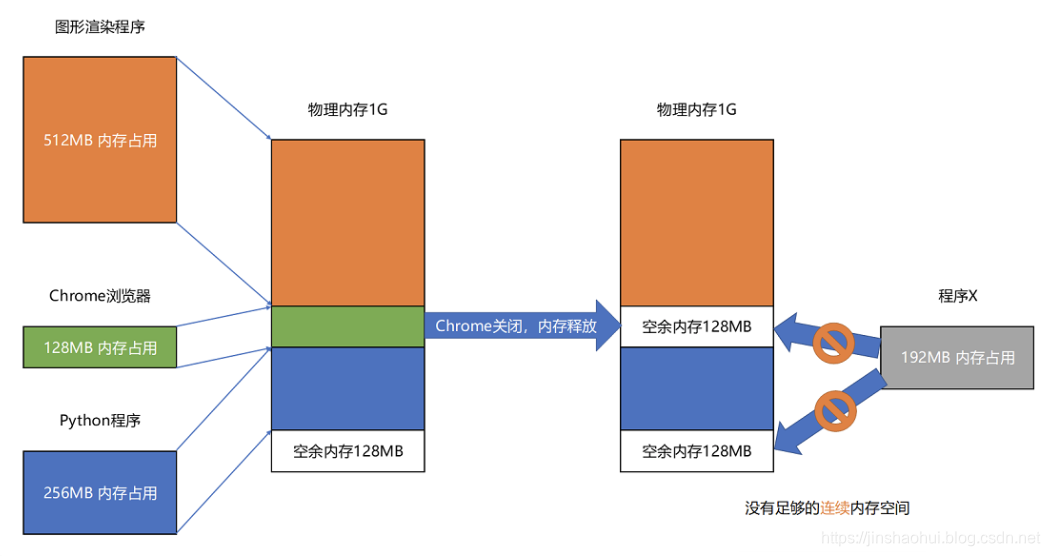
当然,这个我们也有办法解决。解决的办法叫内存交换(Memory Swapping)。我们可以把 Python 程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里面。不过读回来的时候,我们不再把它加载到原来的位置,而是紧紧跟在那已经被占用了的 512MB 内存后面。这样,我们就有了连续的 256MB 内存空间,就可以去加载一个新的 200MB 的程序。如果你自己安装过 Linux 操作系统,你应该遇到过分配一个 swap 硬盘分区的问题。这块分出来的磁盘空间,其实就是专门给 Linux 操作系统进行内存交换用的。虚拟内存、分段,再加上内存交换,看起来似乎已经解决了计算机同时装载运行很多个程序的问题。不过,你千万不要大意,这三者的组合仍然会遇到一个性能瓶颈。硬盘的访问速度要比内存慢很多,而每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。所以,如果内存交换的时候,交换的是一个很占内存空间的程序,这样整个机器都会显得卡顿。
内存分页
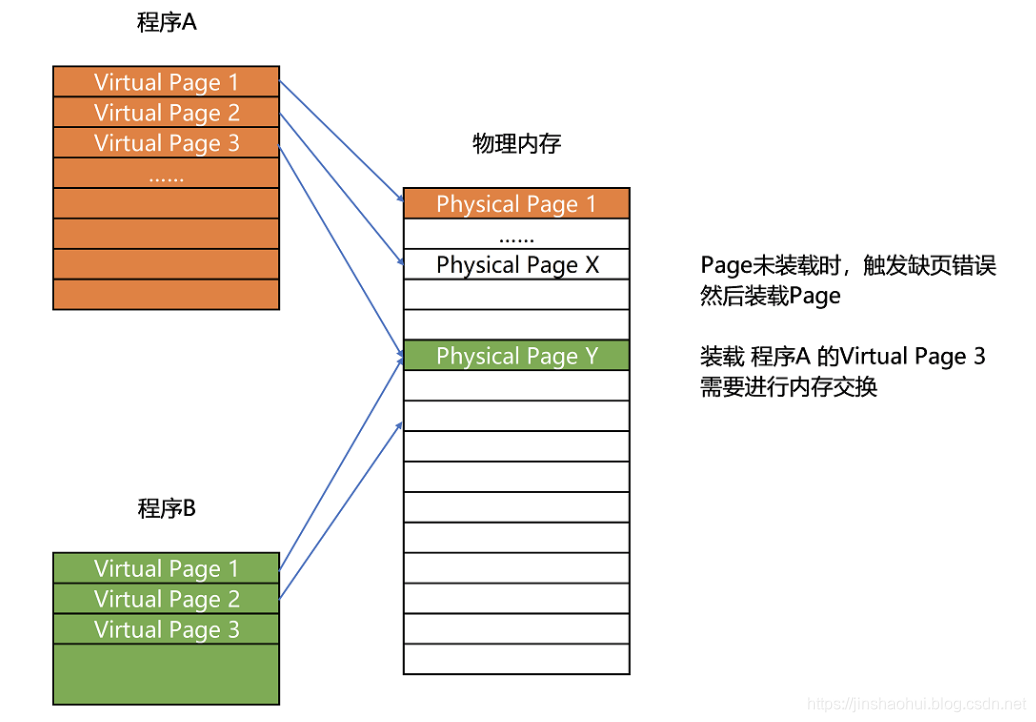
既然问题出在内存碎片和内存交换的空间太大上,那么解决问题的办法就是,少出现一些内存碎片。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决这个问题。这个办法,在现在计算机的内存管理里面,就叫作内存分页(Paging)。
和分段这样分配一整段连续的空间给到程序相比,分页是把整个物理内存空间切成一段段固定尺寸的大小。而对应的程序所需要占用的虚拟内存空间,也会同样切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。从虚拟内存到物理内存的映射,不再是拿整段连续的内存的物理地址,而是按照一个一个页来的。页的尺寸一般远远小于整个程序的大小。在 Linux 下,我们通常只设置成 4KB。你可以通过命令看看你手头的 Linux 系统设置的页的大小。
 ```c
```c
[jinsh@localhost 08]$ getconf PAGE_SIZE
4096
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。实际上,我们的操作系统,的确是这么做的。当要读取特定的页,却发现数据并没有加载到物理内存里的时候,就会触发一个来自于 CPU 的缺页错误(Page Fault)。我们的操作系统会捕捉到这个错误,然后将对应的页,从存放在硬盘上的虚拟内存里读取出来,加载到物理内存里。这种方式,使得我们可以运行那些远大于我们实际物理内存的程序。同时,这样一来,任何程序都不需要一次性加载完所有指令和数据,只需要加载当前需要用到就行了。通过虚拟内存、内存交换和内存分页这三个技术的组合,我们最终得到了一个让程序不需要考虑实际的物理内存地址、大小和当前分配空间的解决方案。这些技术和方法,对于我们程序的编写、编译和链接过程都是透明的。这也是我们在计算机的软硬件开发中常用的一种方法,就是加入一个间接层。通过引入虚拟内存、页映射和内存交换,我们的程序本身,就不再需要考虑对应的真实的内存地址、程序加载、内存管理等问题了。任何一个程序,都只需要把内存当成是一块完整而连续的空间来直接使用。

















 2925
2925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









